




 本文详细探讨了Java集合框架中的HashMap、HashTable、HashSet和LinkedHashSet。HashMap中,TreeNode扩展自LinkedHashMap.Entry,用于支持红黑树和链表的转换。HashTable默认容量为11,扩容系数为2x + 1,所有方法同步,不接受null键。HashSet基于HashMap,其value存储为固定对象PRESENT。LinkedHashSet则在HashSet基础上提供按插入顺序迭代的功能,具有更好的迭代性能。
本文详细探讨了Java集合框架中的HashMap、HashTable、HashSet和LinkedHashSet。HashMap中,TreeNode扩展自LinkedHashMap.Entry,用于支持红黑树和链表的转换。HashTable默认容量为11,扩容系数为2x + 1,所有方法同步,不接受null键。HashSet基于HashMap,其value存储为固定对象PRESENT。LinkedHashSet则在HashSet基础上提供按插入顺序迭代的功能,具有更好的迭代性能。
1、HashMap节选
public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable {
// 默认容量16,new时为0,put()时调用putval(),putval()调用resize()table才不为null
// 和ArrayList类似,初始化不指定容量时,只有第一次put()时才会扩容到16
// 大小是2的幂次,便于计算index,便于resize()的开销,对每个Node只需要做一次&运算
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认装填因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 转化为红黑树的阈值,和退化为链表的阈值,两者不一致是为了避免链表和红黑树的频繁转化
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
// 只有表的容量>=64才能转化为红黑树
static final int MIN_TREEIFY_CAPACITY = 64;
static class Node<K, V> implements Map.Entry<K, V> {
final int hash;
final K key;
V value;
Node<K, V> next;
public final String toString() {
return key + "=" + value;
}
// 注意Node的hash是key^value
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
}
// key可以为null,放在tab[0]里,不直接利用key的hash,避免了低位相同、高位不同的key的冲突
// 从这里可以看出,hashMap允许key == null
// 老生常谈的话题,HashMap KV均可为null,TreeMap key不可为null,HashTable均不可为null
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 寻找>=cap的2的幂次,写得挺巧妙的
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
transient Node<K, V>[] table;
transient Set<Map.Entry<K, V>> entrySet;
transient int size;
// 扩容阈值,capacity * load factor
int threshold;
final float loadFactor;
// getNode先找到对应的index(tab[(n - 1) & hash], n是tab.length),再遍历链表或者红黑树判断是否是给定的key
public V get(Object key) {
Node<K, V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/*
* putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean,
* evict)找到对应的index再插入到链尾,最后会调用afterNodeInsertion(evict)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// 无冲突时直接插入
tab[i] = newNode(hash, key, value, null);
else {
// 有冲突
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
// 插入红黑树
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
// 遍历链表
if ((e = p.next) == null) {
// 已经遍历至最后一个节点
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
// 插入回调,例如LinkedHashMap就实现了这个方法
afterNodeInsertion(evict);
return null;
}
final Node<K, V>[] resize() {
/*
* 将地址i上的链表或红黑树根据node.hash & oldCap == 0分成两条链表,node.hash & oldCap ==
* 0的链插入到newTab[i]中,node.hash & oldCap == 1的链插入到newTab[i + oldCap]中
* 1.8之前是倒序插入的,多线程resize()时会产生死循环,1.8改成了正序插入
*/
}
// 红黑树根据hash(key)排序
static final class TreeNode<K, V> extends LinkedHashMap.Entry<K, V> {
TreeNode<K, V> parent;
TreeNode<K, V> left;
TreeNode<K, V> right;
TreeNode<K, V> prev;
boolean red;
}
}

HashMap中的TreeNode继承自LinkedHashMap.Entry,而LinkedHashMap.Entry又继承自HashMap.Node(如上图),主要是为了给红黑树的节点增加before和after的指针,便于链表和红黑树的转化。
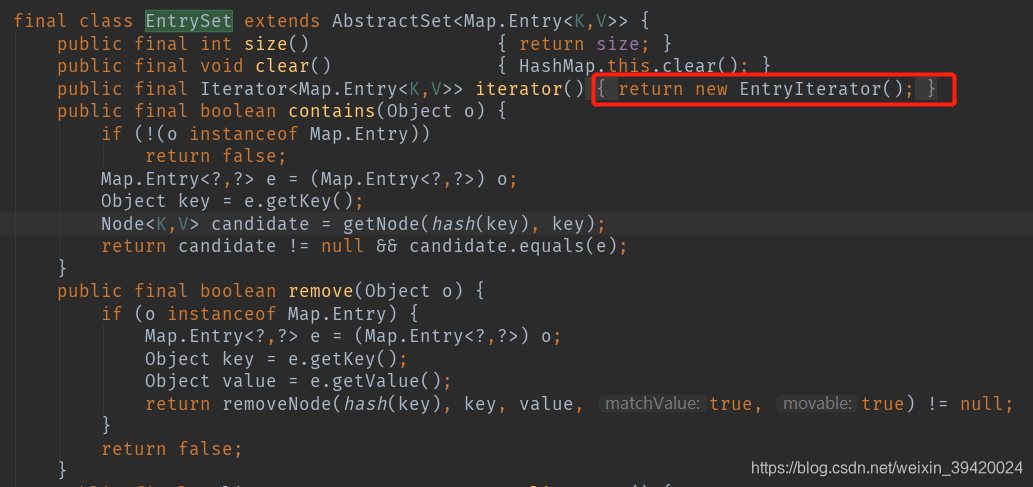
HashMap中有 transient Set<Map.Entry<K,V>> entrySet,并不进行添加操作,里面也不存储值,通过EntryIterator来遍历,如下图。

2、HashTable
默认11,0.75,2x + 1倍扩容,不允许key为null,方法是synchronized的,keySet()和values()调用了AbstractMap的方法,利用了entry的迭代器
public class Hashtable<K, V> extends Dictionary<K, V> implements Map<K, V>, Cloneable, java.io.Serializable {
// 默认大小11
private transient Entry<?, ?>[] table;
private transient int count;
private int threshold;
// 默认装填因子0.75
private float loadFactor;
private transient int modCount = 0;
@SuppressWarnings("unchecked")
public synchronized V get(Object key) {
Entry<?, ?> tab[] = table;
int hash = key.hashCode();
// 地址直接进行模运算
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?, ?> e = tab[index]; e != null; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V) e.value;
}
}
return null;
}
protected void rehash() {
int oldCapacity = table.length;
Entry<?, ?>[] oldMap = table;
// 扩容到2x + 1
int newCapacity = (oldCapacity << 1) + 1;
......
}
}
3、HashSet
利用了HashMap,entry的value都是private static final Object PRESENT = new Object();
4、LinkedHashSet
public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable
都是复用的HashSet的方法,迭代时会以插入的顺序迭代,迭代性能略强于HashSet,插入略差

















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









