







 本文是《Kafka权威指南》的读书笔记,主要探讨Kafka的可靠性机制,包括集群成员关系、控制器、复制、请求处理等方面。同时,文章还介绍了Kafka作为数据管道的角色,以及其在跨集群数据镜像和流式处理中的应用。
本文是《Kafka权威指南》的读书笔记,主要探讨Kafka的可靠性机制,包括集群成员关系、控制器、复制、请求处理等方面。同时,文章还介绍了Kafka作为数据管道的角色,以及其在跨集群数据镜像和流式处理中的应用。
写在前面,最近网易驱赶绝症员工的事情很火,网易做出这种事情一点也不奇怪,早就爆出过保安驱赶员工的事情。专门挑周五、没人的会议室谈话裁员,怕员工闹事,不给n+1。考拉卖给阿里的时候组里人心惶惶根本没人干活,拖了一两个月高层一句话都没说,最后丁胖子出来说了句在合作,然后转手就被卖了,对员工毫无责任心。考拉被阿里收购也算因祸得福吧,祝网易的前同事早日脱离苦海。。。
一、深入Kafka
(1)集群成员关系
Kafka 使用ZK来维护集群成员的信息。每个broker 都有一个唯一标识符,创建临时节点把自己的ID注册到ZK。Kafka 组件订阅ZK的/brokers/ids路径(broker在ZK上的注册路径),当有broker 加入集群或退出集群时,这些组件就可以获得通知。如果使用相同的id启动另一个全新的broker(旧broker已关闭),它会立即加入集群,井拥有与旧broker相同的分区和主题。
(2)控制器
控制器是负责分区首领选取的broker。集群里第一个启动的broker在ZK创建一个临时节点/controller让自己成为控制器,其他broker在控制器节点上创建ZK watch对象接收变更通知。当控制器发现broker离线,为失去首领的分区选举首领,遍历分区,并确定谁应该成为新首领(简单来说就是分区副本列表里的下一个副本),发送通知。控制器使用epoch 来避免“脑裂” ,“脑裂”是指两个节点同时认为自己是当前的控制器。
(3)复制
每个分区都有一个首领副本。为了保证一致性,所有生产者请求和消费者请求都会经过这个副本,而跟随者副本的唯一任务就是从首领那里复制消息,保持与首领一致的状态,首领副本还需要维护所有的跟随者副本和同步副本。
跟随者向首领发送获取数据的请求,这种请求与消费者为了读取消息而发送的请求是一样的,可以看做一个消费者。跟随者在阈值时间内没有请求最新消息,被认为是不同步的,不会被控制器选举为新的主分区。
每个分区都有一个首选首领,是创建主题时分区的首领,有较好的均衡性。
(4)处理请求(元数据请求、生产消费请求)
broker按序处理请求,包括生产和消费请求(消费者或者跟随者副本发送)。Processor线程(网络线程)数量可配,从客户端获取请求消息,把它们放进请求队列,然后从相应队列获取响应消息,返回给客户端。
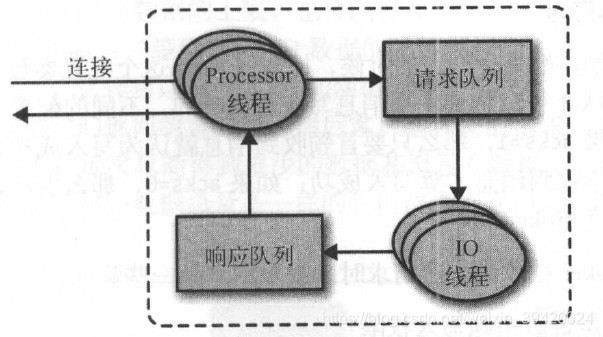
任意一个broker都缓存了主题和分区的元数据,客户端向任意一个broker获取元数据。如果收到非首领错误(连接到了跟随者副本),刷新元数据缓存。
acks参数指定了需要多少个broker 确认才可以认为一个消息写入是成功的,之后,消息被写入本地磁盘。在Linux 系统上,消息会被写到文件系统缓存里,并不保证它们何时会被刷新到磁盘上。Kafka不会一直等待数据被写到磁盘上一一它依赖复制功能来保证消息的持久性。在消息被写入分区的首领之后,如果acks = 0 or 1,立即返回;如果acks = all,缓存请求,等待所有副本响应。
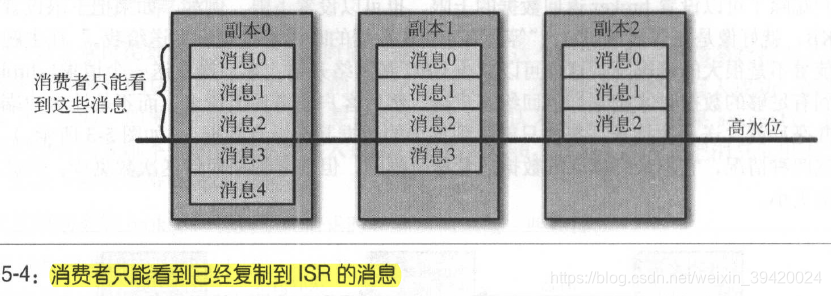
Kafka 使用零复制(零拷贝)技术向客户端发送消息一一也就是说, Kafka直接把消息从文件(或者更确切地说是Linux文件系统缓存)里发送到网络通道,无需额外的缓冲区。并不是所有保存在分区首领上的数据都可以被客户端读取。大部分客户端只能读取已经被写入所有同步副本的消息。
(5)物理存储
Kafka的基本存储单元是分区,配置的时候log.dirs指定分区目录。分配分区时,要根据分区数、主分区、机架均摊,每个broker分区数接近,主分区均匀,同一分区的副本分布在不同机架上。新的分区总是被添加到分区数最少的目录里。
(6)文件
我们把分区分成若干个片段。默认情况下,每个片段包含1 GB或一周的数据,以较小的那个为准。在broker往分区写入数据时,如果达到片段上限,就关闭当前文件,井打开一个新文件。当前正在写入数据的片段叫作活跃片段。活动片段永远不会被删除,所以有时数据存活时间会比设置的阈值来的大。
保存在磁盘上的数据格式与从生产者发送过来或者发送给消费者的消息格式是一样的,所以可以采用零拷贝技术,也避免了压缩和解压的开销。推荐在生产者端开启压缩功能,减少消息头的开销。
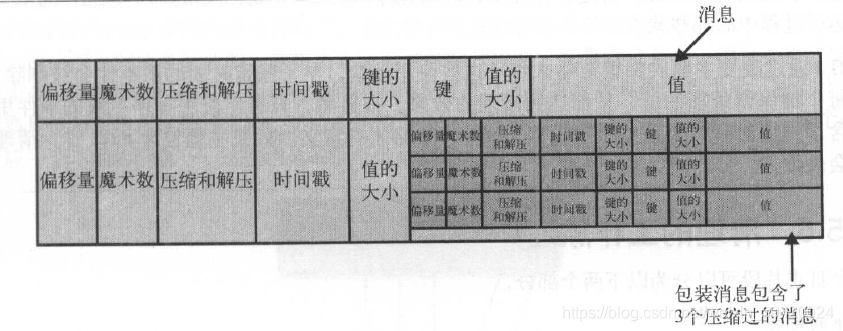
Kafka为每个分区维护了一个索引。索引把偏移量映射到片段文件和偏移量在文件里的位置。
如果启动了清理功能,清理线程会选择污浊比最高的分区清理,污浊的消息是指上次清理后写入的消息。相同的key保留最新的value,想要删除key可以发送(key, null),称为墓碑消息,会被清理线程移除。
二、可靠性
(1)Kafka在分区维度保证消息顺序性,只有当消息被写入分区的所有同步副本时(但不一定要写入磁盘),它才被认为是“ 已提交”的,才可以被消费者读取。所有事件都被发送给分区的首领副本,其他副本只负责与首领副本同步。如果副本在同步和非同步状态之间快速切换,很可能是副本所在broker频繁fullgc与ZK断开了连接。
有三个系数影响可靠性,可以应用在broker和主题级别。(1)复制系数,replicatlon.factor,即分区的副本数,默认3。(2)不完全的首领选举,unclean.leader.selection,是指在没有同步副本时,是否允许非同步副本成为主副本。允许的话会数据不一致,不允许会不可用,需要等待旧首领上线。(3)最小同步副本数,min.insync.replicas,当同步副本数小于设定值,无法对分区进行写入。
可靠性对于生产者来说,最重要的指标是error-rate和retry-rate,对消费者是cosumer-lag,表示已提交的offset和已消费的消息的差距,理想为0。
(2)生产者可靠性
acks参数指定确认消息被接收需要收到多少个分区的ack。重试可以让生产者自动处理错误,有可重试和不可重试错误,比如首领不可用就是可重试的,配置错误是不可重试的。Kafka不保证有且只有一次消费,重试可能会造成重复消费,可以在应用层为消息添加id、保证消息幂、处理其他类型错误。
(3)消费者可靠性
消费者可靠性配置有auto.offset.reset(latesth或者earliest),enable.auto.commit(自动提交已处理偏移量,如果异步处理,可能会提交尚未处理的偏移量),auto.commit.interval.ms(自动提交时间间隔)。
消费者遇到可重试错误时,提交偏移量,把没处理的消息放入缓冲区,调用pause()保证轮询不返回数据(不是停止轮询,否则会被认为死亡),防止缓冲区被覆盖,继而处理错误,resume()重新从轮询中获取数据。或者将错误消息写入独立主题,由另一个消费者读取错误消息进行处理,类似RabbitMQ中的死信队列。
Kafka不提供事务支持,也不支持有且仅有一次的消息投递,可以通过支持唯一键的外部系统,实现将Kafka消息有且仅有一次地写入外部系统。
VerifiableProduce和VerifiableConsumer是Kafka的测试工具,可以发送、消费消息,模拟异常情况。
三、数据管道、跨集群数据镜像、管理与监控、流式计算
这部分偏运维,简单了解一下。
(1)数据管道
Kafka可以作为数据管道的一个端点,或者两个端点之间的通道,为各个数据端点(MYSQL,ES等)提供了大型缓冲区。Kafka有回压策略,可以延后向生产者ACK,类似TCP,消费者根据自己的消费速率自行拉取,吞吐量大,可靠性高,适合做大型缓冲区。
Connect API为集成外部系统提供了处理偏移量的APl ,连接器因此可以构建仅一次传递的端到端数据管道。Connect API支持伸缩,而且擅长并行处理任务,有自己的内存对象模型,包括数据类型和schema。
数据转换分为ETL(extract-transform-load),提取-加载-转换,数据经过管道时进行处理,下游节省了时间,但是数据不完整,处理不够自由;还有ELT,保留全部数据,下游自行处理,推荐ELT,保持灵活性。
Connect以worker进程集群的方式运行。连接器拆分任务,交给worker执行;任务获得worker分配的源系统上下文,负责将数据移入或者移出Kafka;转换器把Mqsql行转换为JSON写入Kafka(或者其他转换方式)。worker进程类似客户端,也有心跳和再分配机制。Kafka作为数据管道也可以看做大型的生产者消费者,适配不同的source和destination。
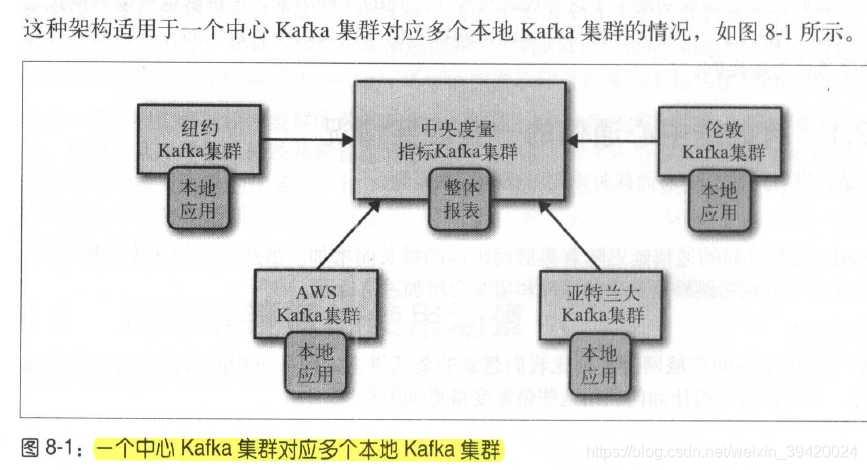
(2)跨集群数据镜像
Kafka内置跨集群复制工具MirrorMaker。有几种需要跨集群复制的场景,区域集群和中心集群(公司分布在不同城市,每个城市需要一个集群,向中心集群同步数据);冗余(backup);云迁移。尽量从远程中心读取数据,而不是向远程中心写入数据,因为一个离线的消费者比一个离线的生产者要安全得多。但是如果需要加密,最好放在source端,读取本地数据,建立SSL连接。
集群的Huk and Spoke架构:数据只会在本地的数据中心生成,而且每个数据中心的数据只会被镜像到中央数据中心一次。只处理单个数据中心数据的应用程序可以被部署在本地数据中心里, 而需要处理多个数据中心数据的应用程序则需要被部署在中央数据中心里,数据复制是单向的,本地集群是割裂的。
双活架构:互为backup,问题是如何在进行多个位置的数据异步读取和异步更新时避免冲突,类似git的冲突。还会导致循环镜像,可以在逻辑主题上加上集群的命名空间解决。
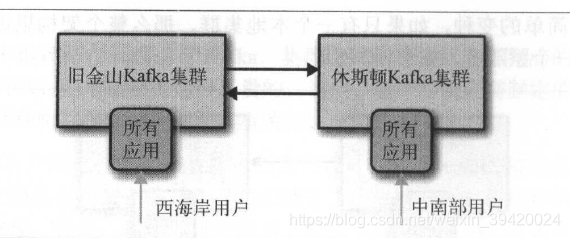
主备架构:易实现,容灾,但是浪费一个集群,无法实现不丢失数据或无重复数据的Kafka集群的失效备援(任何架构都无法做到)。
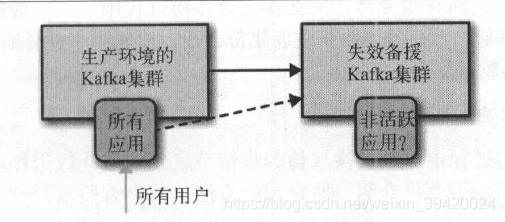
目前的Kafka 镜像解决方案无法为主集群和灾备集群保留偏移量。
延展集群是跨多个数据中心安装的单个Kafka 集群,优点是可以同步复制,容灾有限制。
(3)管理与监控
管理上主要介绍了对主题、分区、生产者消费者的CRUD命令行操作,不细讲了。
监控上,对broker来说,最重要的指标是非同步分区的数量,如果一直不变,可能某个broker已离线。还有分区的数量、首领分区的数量、主题流入字节速率、主题流入消息速率等指标,监控均衡性。如果想要将负载高的broker的分区移动到负载低的broker上,可以使用kafka-reassign-partitions.sh工具。
对主题和分区,有流入流出速率、分区size等指标。机器层面,还有cpu、io、GC等指标。
对生产者,record-error-rate是错误率,request-latency-avg表示请求平均RT。
对消费者,有发送请求的平均RT(fetch-latency-avg),fetch-rate(每秒请求数),fetch-size-avg 表示这些请求的平均字节数,
records-per-request-avg表示每个请求的平均消息数。
(4)流式处理
Kafka 一般被认为是一个强大的消息总线,可以传递事件流,但没有处理和转换事件的能力。Kafka 可靠的传递能力让它成为流式处理系统完美的数据来源。很多基于Kafka 构建的流式处理系统都将Kafka 作为唯一可靠的数据来隙,如Apache Storm 、Apache Spark Streaming 、Apache Flink 、Apache Samza等。
流式处理就是实时处理事件流,比如电商系统,实时地有订单消息过来,可以计算指定时间内的GMV、亏损额度等,大部分流操作都是基于时间窗口。
有时需要多阶段处理,如下,先分组处理,再聚合处理,类似map-reduce。
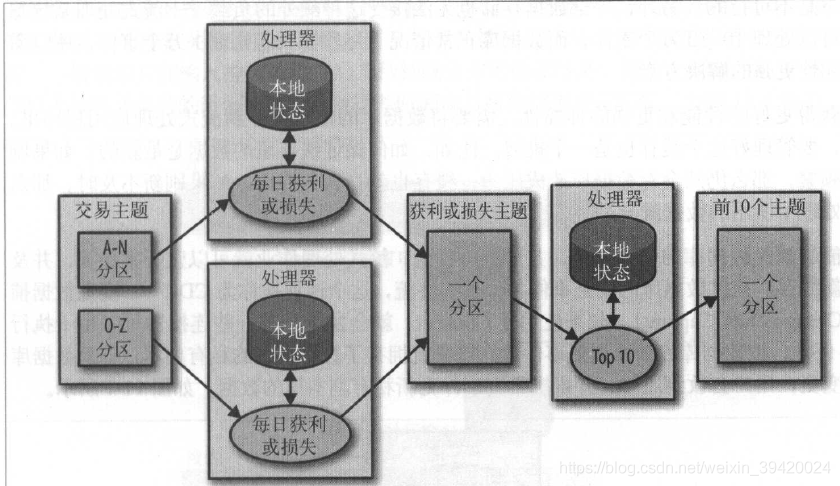
有时要查表,延迟大,可以监听表变更,将表变更也作为流里的一个事件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









