







 本文深入探讨了SOFAJRaft的日志复制和心跳机制,分析了Replicator的启动、心跳与探测消息的发送逻辑,以及AppendEntriesRequest的处理流程。重点介绍了日志同步架构中的Replicator、LogManager和LogStorage角色,阐述了日志持久化和Pipeline优化策略。
本文深入探讨了SOFAJRaft的日志复制和心跳机制,分析了Replicator的启动、心跳与探测消息的发送逻辑,以及AppendEntriesRequest的处理流程。重点介绍了日志同步架构中的Replicator、LogManager和LogStorage角色,阐述了日志持久化和Pipeline优化策略。
1.概述
今天来看一下jraft的日志复制,其实读源码并不一定需要完全理解其逻辑,更重要的是对于需求的实现方式。如果能深刻领悟,应用的自己的工作中,是非常有意义的。
2.日志同步架构
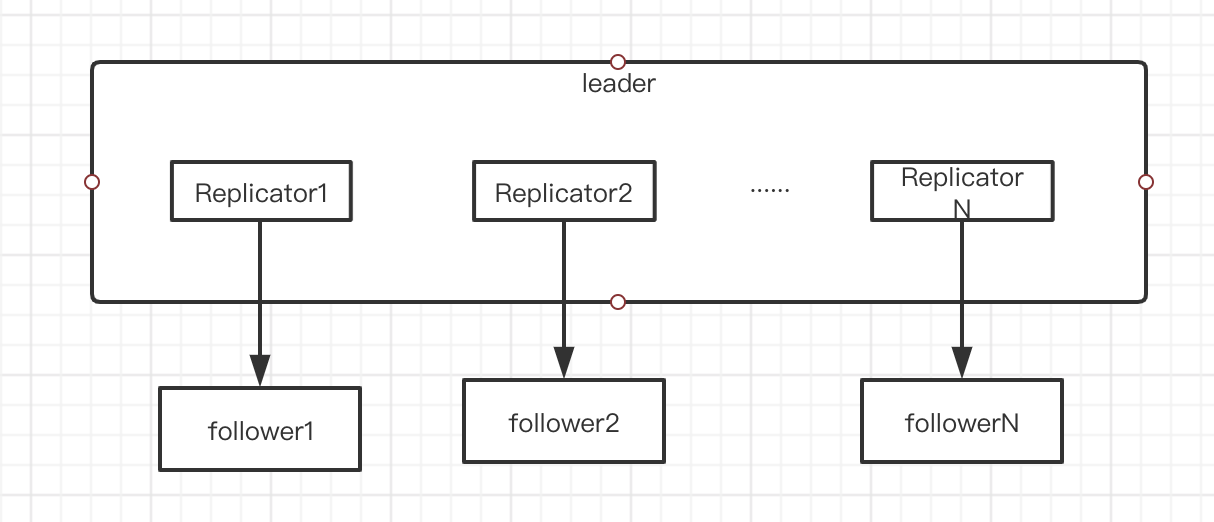
其实主要依赖Replicator、LogManager、LogStorage这三个实现。
- Replicator,leader发送日志和心跳的功能就是在此实现。每个leader>>都会有一个ReplicatorGroup,用来管理所有followers
- LogManager用于处理日志,主要就是消费复制或者apply的日志,将其写入磁盘。
- LogStorage主要就是日志的底层存储工作。给予RocksDB。
3.源码分析
我们先从Replicator开始。首先何时创建:
当节点成为leader后,会启动所有follower和learner的replicator。其实是通过addReplicator方法实现的。
for (final PeerId peer : this.conf.listPeers()) {
if (peer.equals(this.serverId)) {
continue;
}
LOG.debug("Node {} add a replicator, term={}, peer={}.", getNodeId(), this.currTerm, peer);
if (!this.replicatorGroup.addReplicator(peer)) {
LOG.error("Fail to add a replicator, peer={}.", peer);
}
}
// Start learner's replicators
for (final PeerId peer : this.conf.listLearners()) {
LOG.debug("Node {} add a learner replicator, term={}, peer={}.", getNodeId(), this.currTerm, peer);
if (!this.replicatorGroup.addReplicator(peer, ReplicatorType.Learner)) {
LOG.error("Fail to add a learner replicator, peer={}.", peer);
}
}
addReplicator方法
1.从failureReplicators中移除需要add的peer,这个肯定是要执行的。可能存在failureReplicators不存在当前peer的case。
2.复制一份集群配置,然后调用Replicator.start 方法。
3.成功的话,将返回的ThreadId 加入到replicatorMap,失败加入到failureReplicators。
Replicator是真正去完成工作的实现,ReplicatorGroup则是用来管理Replicator的实现类。
我们在编码中也可以这么做,理清楚每个点的意义,以及应该出现的地方,这么我们写出来的代码也是非常易于理解,并且鲁棒的。比如把所有Replicator共有的或者共同依赖对象可以放在ReplicatorGroup。
Replicator#start方法
1.初始化Replicator对象。
2.调用connect方法和对应节点建立连接。
3.创建ThreadId,其实是一个对Replicator对象的不可重入锁。只有获取到锁的情况Replicator才可用。其实就是维护Replicator的竞态条件。全局锁。我理解不可重入的原因就是同一线程不同操作的时候需要保证Replicator的安全。
4.执行监听回调,业务方可以实现对应监听器。
5.打开超时心跳,因为这个心跳是可动态调整的,所以并没有直接使用定时器。每次通过定时任务启动。这个方法会在每次心跳返回的时候再次调用。
final long dueTime = startMs + this.options.getDynamicHeartBeatTimeoutMs();
try {
this.heartbeatTimer = this.timerManager.schedule(() -> onTimeout(this.id), dueTime - Utils.nowMs(),
TimeUnit.MILLISECONDS) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









