




 本文介绍了基于SOFAJRaft的高性能Java日志系统改进,移除对RocksDB的依赖,设计了纯Java的索引模块,涉及内存映射、文件管理、组提交和预分配技术,旨在提升存储性能和代码可读性。
本文介绍了基于SOFAJRaft的高性能Java日志系统改进,移除对RocksDB的依赖,设计了纯Java的索引模块,涉及内存映射、文件管理、组提交和预分配技术,旨在提升存储性能和代码可读性。

📄
文|黄章衡(SOFAJRaft 项目组)
福州大学 19 级计算机系
研究方向|分布式中间件、分布式数据库
Github 主页|https://github.com/hzh0425
校对|冯家纯(SOFAJRaft 开源社区负责人)
本文 9402 字 阅读 18 分钟
▼
PART. 1 项目介绍
1.1 SOFAJRaft 介绍
SOFAJRaft 是一个基于 RAFT 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。使用 SOFAJRaft 你可以专注于自己的业务领域,由 SOFAJRaft 负责处理所有与 RAFT 相关的技术难题,并且 SOFAJRaft 非常易于使用,你可以通过几个示例在很短的时间内掌握它。
Github 地址:
https://github.com/sofastack/sofa-jraft
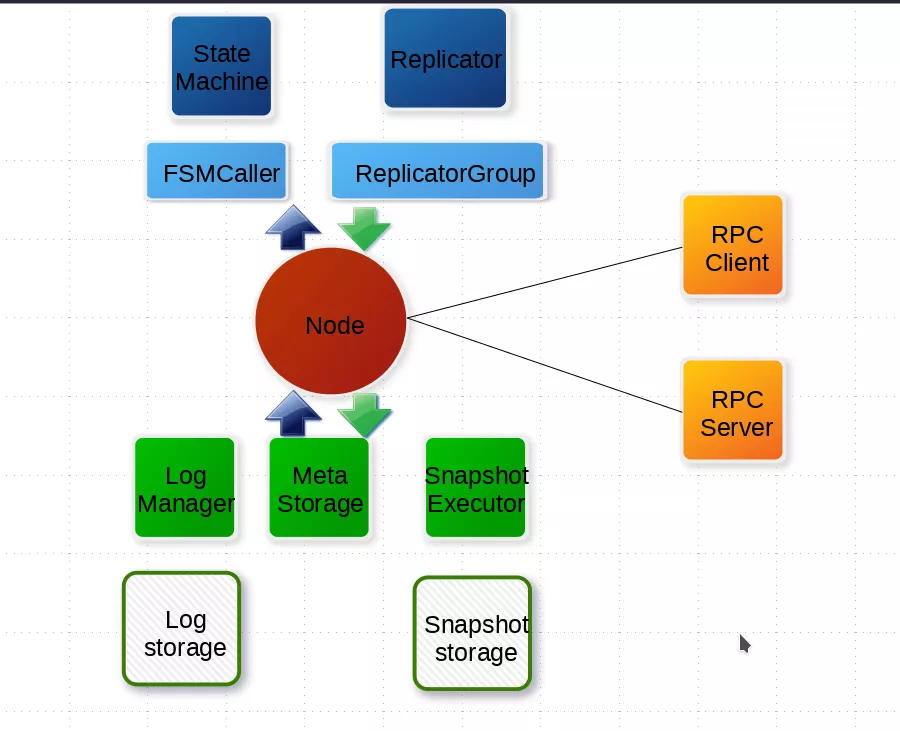
1.2 任务要求
**目标:*当前 LogStorage 的实现,采用 index 与 data 分离的设计,我们将 key 和 value 的 offset 作为索引写入 rocksdb,同时日志条目(data)*写入 Segment Log。因为使用 SOFAJRaft 的用户经常也使用了不同版本的 rocksdb,这就要求用户不得不更换自己的 rocksdb 版本来适应 SOFAJRaft, 所以我们希望做一个改进:移除对 rocksdb 的依赖,构建出一个纯 Java 实现的索引模块。
PART. 2 前置知识
Log Structured File Systems
如果学习过类似 Kafka 等消息队列的同学,对日志型系统应该并不陌生。
如图所示,我们可以在单机磁盘上存储一些日志型文件,这些文件中一般包含了旧文件和新文件的集合。区别在于 Active Data File 一般是映射到内存中的并且正在写入的新文件*(基于 mmap 内存映射技术)*,而 Older Data File 是已经写完了,并且都 Flush 到磁盘上的旧文件,当一块 Active File 写完之后,就会将其关闭,并打开一个新的 Active File 继续写。
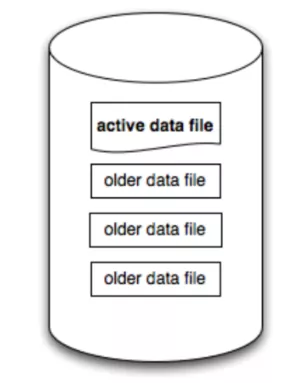
并且每一次的写入,每个 Log Entry 都会被 Append 到 Active File 的尾部,而 Active File 往往会用 mmap 内存映射技术,将文件映射到 os Page Cache 里,因此每一次的写入都是内存顺序写,性能非常高。
终上所述,一块 File 无非就是一些 Log Entry 的集合,如图所示:
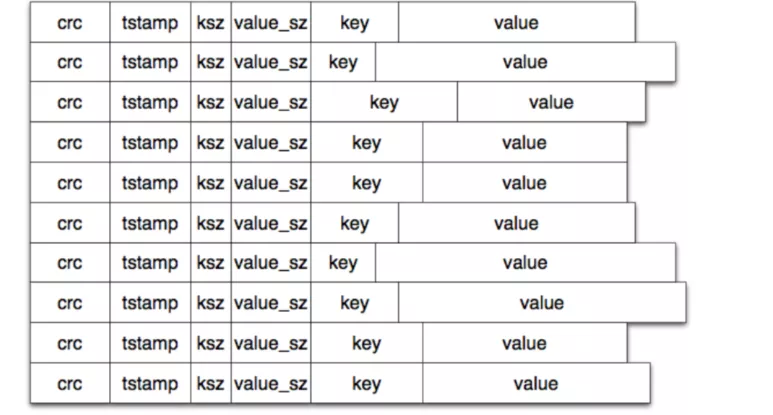
同时,仅仅将日志写入到 File 中还不够,因为当需要搜索日志的时候,我们不可能顺序遍历每一块文件去搜索,这样性能就太差了。所以我们还需要构建这些文件的 “目录”,也即索引文件。这里的索引本质上也是一些文件的集合,其存储的索引项一般是固定大小的,并提供了 LogEntry 的元信息,如:
- File_Id : 其对应的 LogEntry 存储在哪一块 File 中
- Value_sz : LogEntry 的数据大小
(注: LogEntry 是被序列化后, 以二进制的方式存储的)
- Value_pos: 存储在对应 File 中的哪个位置开始
- 其他的可能还有 crc,时间戳等…

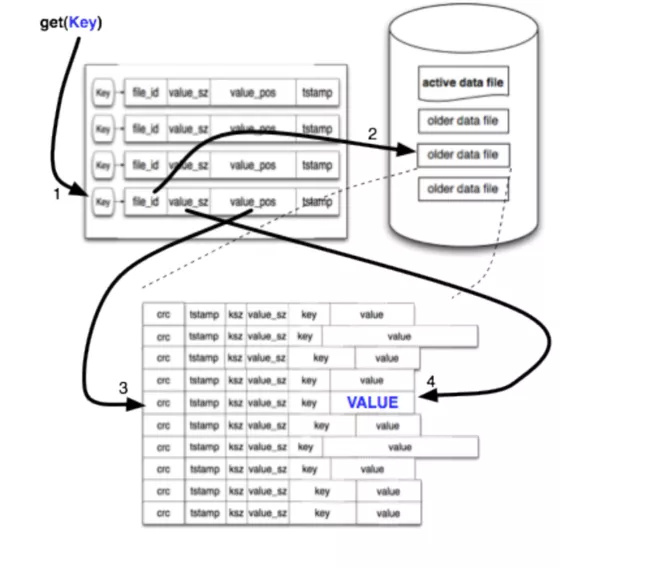
那么依据索引文件的特性,就能够非常方便的查找 IndexEntry。
- 日志项 IndexEntry 是固定大小的
- IndexEntry 存储了 LogEntry 的元信息
- IndexEntry 具有单调递增的特性
举例,如果要查找 LogIndex = 4 的日志:
- 第一步,根据 LogIndex = 4,可以知道索引存储的位置:IndexPos = IndexEntrySize * 4
- 第二步,根据 IndexPos,去索引文件中,取出对应的索引项 IndexEntry
- 第三步,根据 IndexEntry 中的元信息,如 File_Id、Pos 等,到对应的 Data File 中搜索
- 第四步,找到对应的 LogEntry
内存映射技术 mmap
上文一直提到了一个技术:将文件映射到内存中,在内存中写 Active 文件,这也是日志型系统的一个关键技术,在 Unix/Linux 系统下读写文件,一般有两种方式。
传统文件 IO 模型
一种标准的 IO 流程, 是 Open 一个文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









