







非参数模型(在AI 也叫作cased-based reasoning instance-based learning, case-based or memory-based)
非参数模型在相似度定义上不同,没有global model,local model 随着需要而估计,只受nearby 训练实例影响
不需要prior参数形式 复杂度取决于训练集的大小或者数据内部的复杂问题
非参数模型也成做实例-based 或者memory-based 学习算法
左右的训练实例存储O(N)的内存,根据所给输入找相似输出的计算量也是O(N),也称作lazy学习算法。不用马上计算模型,而是在给测试实例时在计算,缺点是对内存和计算能力的需求增加
相似输入有相似输出
非参数密度估计

- 对累积分布函数的非参数估计
- 对密度函数的非参数估计
h是tiny interval
直方估计
输入空间划分为等大小的intervals->bins,x0 原点,bin(宽度h)[xo + mh, xo + (m + 1)h),
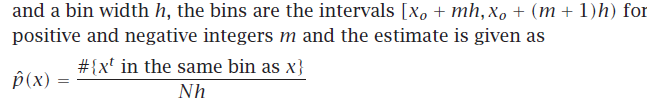
超参数-需要选择x0和h
x0原点->影响bins的near 边界估计
h->影响估计的smoothness,小bins,估计就spiky;大bins,估计更平滑
直方估计的优点是 一旦bin估计计算和存储,则无需保留训练集
不连续:如果在bin边界且估计值为0
Naive 估计器
(不用设置原点, x总是在bin的zise h 中心)两种写法:
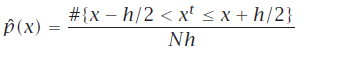
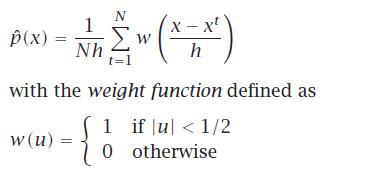
不连续 在ht+−h/2h^{t}+-h/2h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









