






在网页端create一个爬虫: 爬取v2ex网站
分析v2ex网站:
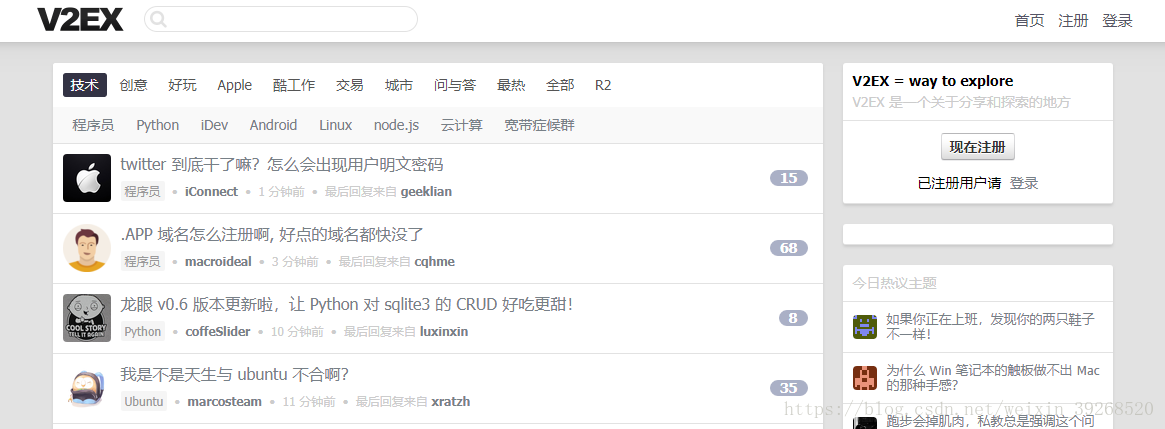
首先有不同的栏目,技术、创意等等,每个栏目下面还有子节点程序员、python等等,节点点开后就是一些分页的问题如图:
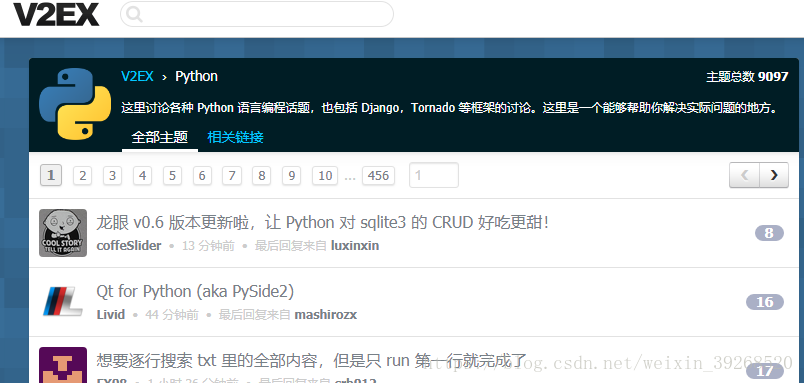
所以首要任务是找到技术,创意,等这一类顶层节点,然后把程序员、python这样的小层节点找出来,然后相应的版块就出来了,然后爬相应板块的问题,然后翻页再找所有的问题
创建一个爬虫:
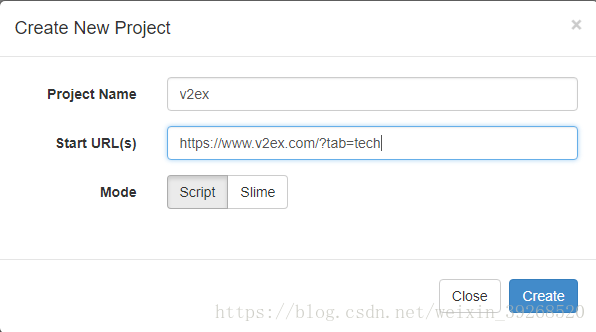
自动写好一个框架:
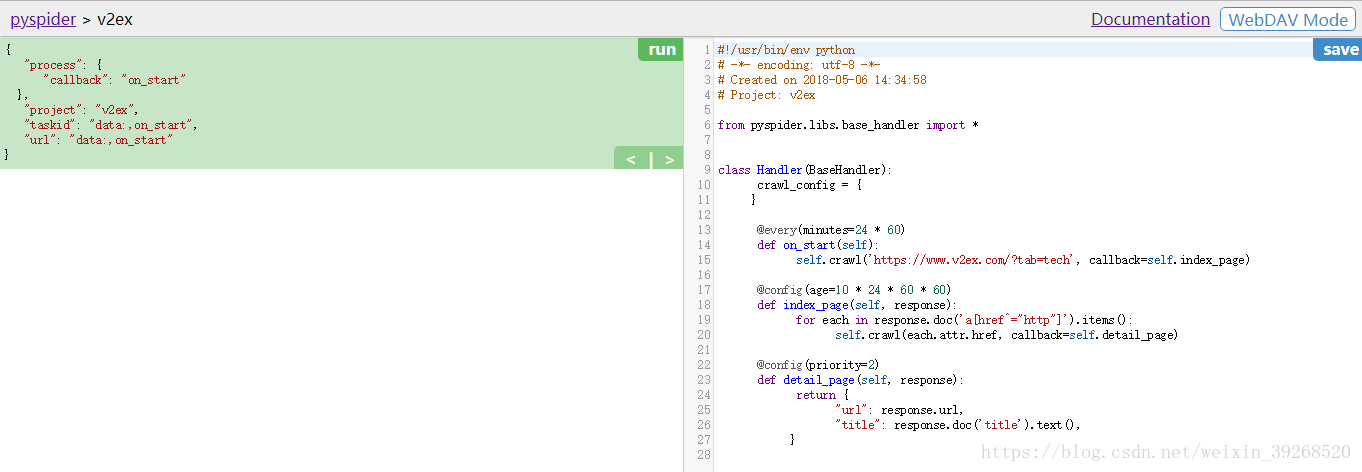
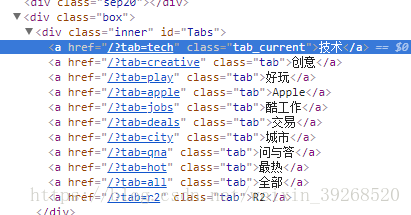
分析后标签元素后,先去爬这些标签,语法见css选择器
crawl到自己定义的页面定义一个函数:

保存运行后发生错误:
[E 180506 15:15:44 base_handler:203] HTTP 599: SSL certificate problem: self signed certificate in certificate chain
Traceback (most recent call last):
File "d:\pyproject\pyspiderdemo_01\venv\lib\site-packages\pyspider\libs\base_handler.py", line 196, in run_task
result = self._run_task(task, response)
File "d:\pyproject\pyspiderdemo_01\venv\lib\site-packages\pyspider\libs\base_handler.py", line 175, in _run_task
response.raise_for_status()
File "d:\pyproject\pyspiderdemo_01\venv\lib\site-packages\pyspider\libs\response.py", line 172, in raise_for_status
six.reraise(Exception, Exception(self.error), Traceback.from_string(self.traceback).as_traceback())
File "d:\pyproject\pyspiderdemo_01\venv\lib\site-packages\pyspider\fetcher\tornado_fetcher.py", line 378, in http_fetch
response = yield gen.maybe_future(self.http_client.fetch(request))
File "d:\pyproject\pyspiderdemo_01\venv\lib\site-packages\tornado\httpclient.py", line 102, in fetch
self._async_client.fetch, request, **kwargs))
File "d:\pyproject\pyspiderdemo_01\venv\lib\site-packages\tornado\ioloop.py", line 458, in run_sync
return future_cell[0].result()
File "d:\pyproject\pyspiderdemo_01\venv\lib\site-packages\tornado\concurrent.py", line 238, in result
raise_exc_info(self._exc_info)
File "<string>", line 3, in raise_exc_info
Exception: HTTP 599: SSL certificate problem: self signed certificate in certificate chain经过查找分析后得出是v2ex的https协议需要证书的问题,
如何解决见:https://www.cnblogs.com/shaosks/p/6856086.html
git地址:https://github.com/binux/pyspider
解决后如图:
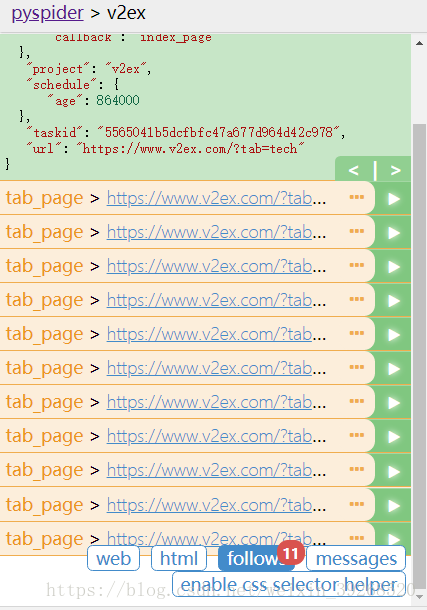
分析子节点:
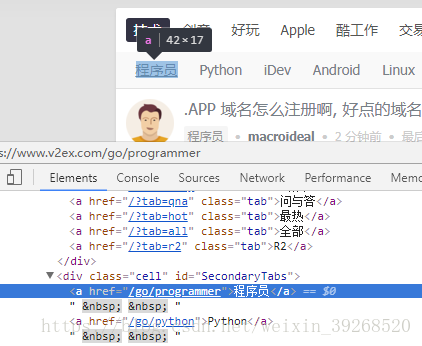
都是以go/开始的
所以爬去子节点:
@config(priority=2)
def tab_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/go/"]').items():
self.crawl(each.attr.href, callback=self.board_page, validate_cert=False)效果:
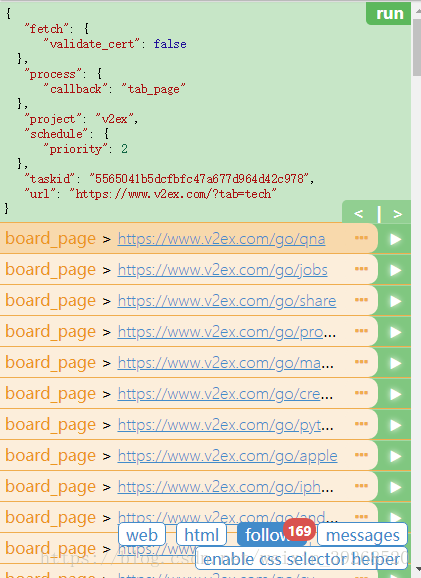
接下来就到了内层板块的页面,
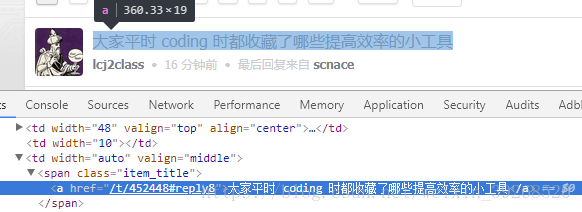
他的每一个问题的href都是t开头
@config(priority=2)
def board_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/t/"]').items():
self.crawl(each.attr.href, callback=self.detail_page, validate_cert=False) 抓到帖子页面后就是真正的detail页面了即:
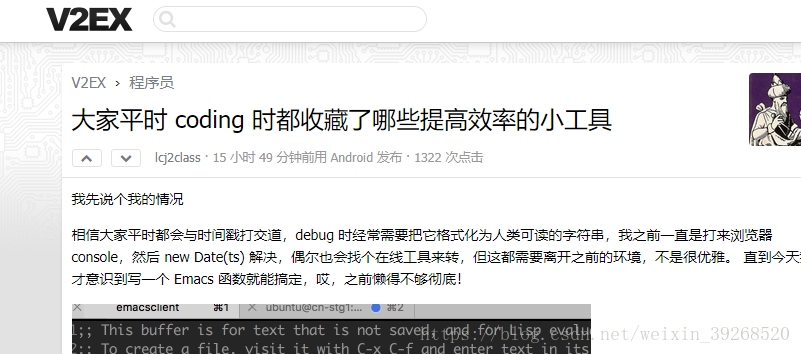
要爬取他的标题和内容,分析详情页面的标签
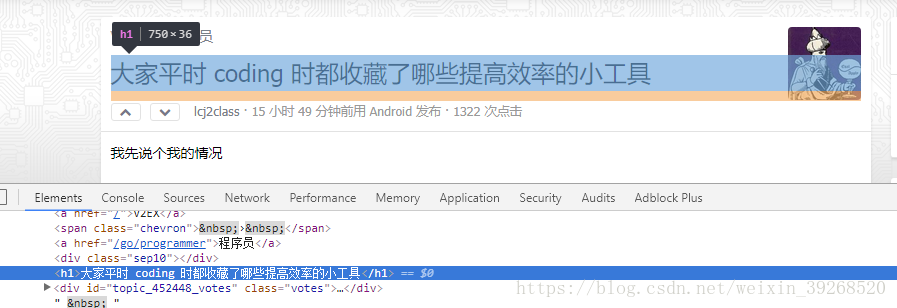
标题为<h1>标签
@config(priority=2)
def detail_page(self, response):
title = response.doc('h1').text()
content = response.doc('div.topic_content')
return {
"url": response.url,
"title": response.doc('title').text(),
}这样的话就把每个detail取了出来:
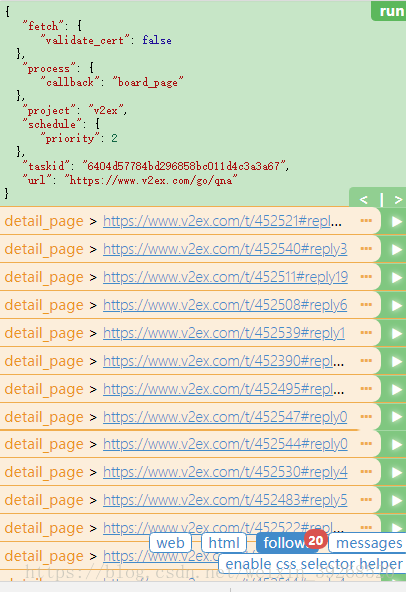
tips:做一些优化

reply指的是回复量,若回复量变了url就变了,可能后台就不更新了,所以把reply屏蔽掉
@config(priority=2)
def board_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/t/"]').items():
url = each.attr.href #取出href
if url.find('#reply') > 0: #若包含#reply
url = url[0:url.find('#')] #去掉reply
self.crawl(url, callback=self.detail_page, validate_cert=False) 
改进后就没有reply了
爬取效果:

总体代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-05-06 15:41:13
# Project: v2ex
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://www.v2ex.com/?tab=tech', callback=self.index_page,validate_cert=False)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/?tab="]').items():
self.crawl(each.attr.href, callback=self.tab_page, validate_cert=False)
@config(priority=2)
def tab_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/go/"]').items():
self.crawl(each.attr.href, callback=self.board_page, validate_cert=False)
@config(priority=2)
def board_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/t/"]').items():
url = each.attr.href
if url.find('#reply') > 0:
url = url[0:url.find('#')]
self.crawl(url, callback=self.detail_page, validate_cert=False)
@config(priority=2)
def detail_page(self, response):
title = response.doc('h1').text()
content = response.doc('div.topic_content')
return {
"url": response.url,
"title": response.doc('title').text(),
}

















 1847
1847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









