







ImageNet Classification with Deep Convolutional Neural Networks
在过去的几天,看了一下Alexnet的论文。在这里提一下重点。
论文原文:https://www.cs.toronto.edu/~fritz/absps/imagenet.pdf;
论文翻译:https://blog.youkuaiyun.com/hit2015spring/article/details/53649183
网络结构
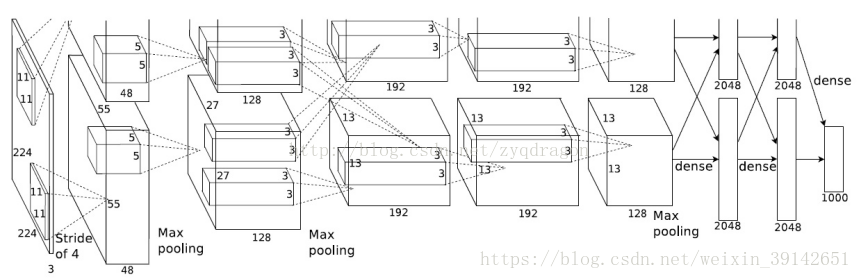
输入:
我们在论文的4.1章节的第二段,可以看到如下阐述:
The first form of data augmentation consists of generating image translations and horizontal reflec- tions. We do this by extracting random 224 × 224 patches (and their horizontal reflections) from the 256×256 images and training our network on these extracted patches
可见,输入的数据是n*224 * 224 * 3的图像。然后,我们来重点看看3.5章节的阐述。

结合4.2章节,我们大概可以了解框架的流程了。论文中的整个神经网络框架流程如上图2所示。
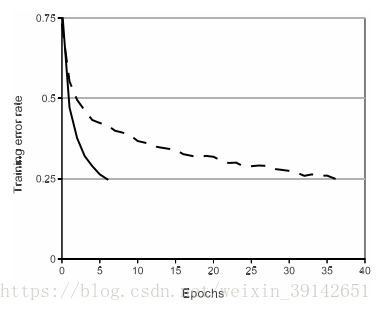
ReLU非线性激活函数
ReLU函数形式:f(x)=max(0,x)。
论文中指出,训练带ReLUs的深度卷积神经网络比带tanh单元的同等网络要快好几倍。如图3所示,它显示出对于特定的四层卷积网络,在CIFAR-10数据集上达到25%的训练误差所需的迭代次数。此图显示,如果我们使用了传统的饱和神经元模型,就不能用如此大的神经网络来对该工作完成实验。
局部响应归一化(LRN)
局部响应归一化公式: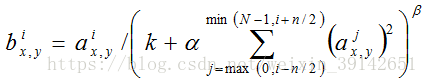 。
。
a表示第i个核在位置(x,y)运用ReLU非线性化神经元输出,n是同一个位置上临近的kernel map的数目,N是kernal的总数。而k,n,alpha,beta是超参数,一般取K=2,n=5,alpha=1*e-4,beta=0.75。
使用LRN的好处:有利于提高模型的泛化能力,做了平滑处理,识别率提高了1%~2%。
但是在在2015年 Very Deep Convolutional Networks for Large-Scale Image Recognition的2.1章节中提到LRN基本没什么用。
All hidden layers are equipped with the rectification (ReLU (Krizhevsky et al., 2012)) nonlinearity. We note that none of our networks (except for one) contain Local Response Normalisation(LRN) normalisation (Krizhevsky et al., 2012): as will be shown in Sect. 4, such normalisationdoes not improve the performance on the ILSVRC dataset, but leads to increased memory consumption and computation time. Where applicable, the parameters for the LRN layer are thoseof (Krizhevsky et al., 2012).
(参考文章:https://blog.youkuaiyun.com/hduxiejun/article/details/70570086)
Overlapping Pooling
论文中采用大小为3*3,步长为2*2的池化核对图像进行池化操作。对比传统的不重叠池化,论文指出这种方法将TOP-1和TOP-5的错误率降低0.4%和0.3%。
数据增强
减少图像数据过拟合最简单最常用的方法,是使用标签-保留转换,人为地扩大数据集(例如,[25,4,5])。使用数据增强的两种不同形式,这两种形式都允许转换图像用很少的计算量从原始图像中产生,所以转换图像不需要存储在磁盘上。在实现中,转换图像是由CPU上的Python代码生成的,而GPU是在之前那一批图像上训练的。所以这些数据增强方案实际上是计算自由。
数据增强的第一种形式由生成图像转化和水平反射组成。为此,从256×256的图像中提取随机的224×224的碎片(还有它们的水平反射),并在这些提取的碎片上训练我们的网络(这就是输入图像是224×224×3维的原因)。这使得训练集规模扩大了2048倍,但是由此产生的训练样例一定高度地相互依赖。如果没有这个方案,网络会有大量的过拟合,这将迫使使用小得多的网络。在测试时,该网络通过提取五个224×224的碎片(四个边角碎片和中心碎片)连同它们的水平反射(因此总共是十个碎片)做出了预测,并在这十个碎片上来平均该网络的softmax层做出的预测。
数据增强的第二种形式包含改变训练图像中RGB通道的强度。具体来说,在遍及整个ImageNet训练集的RGB像素值集合中执行PCA。对于每个训练图像,成倍增加已有主成分,比例大小为对应特征值乘以一个从均值为0,标准差为0.1的高斯分布中提取的随机变量。这样一来,对于每个RGB图像像素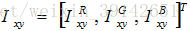 ,增加下面这项:
,增加下面这项:
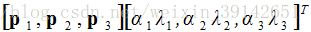
其中 <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









