









 本文深入探讨Zookeeper作为分布式协调服务的重要性和特点,包括其解决部分失败问题的能力、高可用性和高性能表现,以及数据一致性保障。同时,文章详细介绍了Zookeeper的写数据流程和数据结构,帮助读者理解其工作原理。
本文深入探讨Zookeeper作为分布式协调服务的重要性和特点,包括其解决部分失败问题的能力、高可用性和高性能表现,以及数据一致性保障。同时,文章详细介绍了Zookeeper的写数据流程和数据结构,帮助读者理解其工作原理。
Zookeeper概述
为什么要用zookeeper
zookeeper是分布式协调服务,分布式应用难免会出现部分失败,假设一条消息在两个节点中间传输,如果出现网络错误,发送者无法知道接收者是否已经拿到消息,接收者可能拿到了,也可能没有拿到,发送者要知道真实情况只能重新连接接收者,并向它发出询问,我们不知道一个操作是否成功,这种情况部分失败。zookeeper的出现使得我们可以对出现部分失败的情况进行相应的处理。
zookeeper特点
- 使用起来十分的简便,它的核心是一个简化的文件系统,与linux的文件系统类似,并且提供了一些简单的操作和一些额外的抽象操作(排序和通知)
- 在设计上具有高可用性,如果使用复制模式的 话,当一台leader节点挂点,马上选举出一个新的leader,整个选举过程只有200ms左右
- 使用了松耦合的交互方式,在双方都不了解的情况下进行数据的交换,双方甚至都不需要知道对方是否存在
- 具有高性能,对于以写操作为主的工作中,基准吞吐量超过每秒10000个操作,对于常规的以读操作为主的工作中,吞吐量可以高出好几倍。
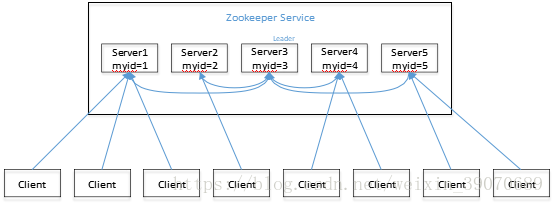
- 上图为一个领导者(leader),多个跟随者(follower)组成的集群。
- Leader 负责进行投票的发起和决议,更新系统状态。通过自动选举产生
- Follower 用于接收客户请求并向客户端返回结果,在选举 Leader 过程中参与投票
- 集群中只要有半数以上节点存活,Zookeeper 集群就能正常服务。如果有5台节点,只需要3台节点存活即可,如果有4台也需要3台,所以一般部署奇数的台数的节点
- 全局数据一致:每个 server 保存一份相同的数据副本,client 无论连接到哪个 server,数据都是一致的。
- 更新请求顺序进行,来自同一个 client 的更新请求按其发送顺序依次执行
- 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,client 能读到最新数据,下面的写数据流程解释原因
写数据流程
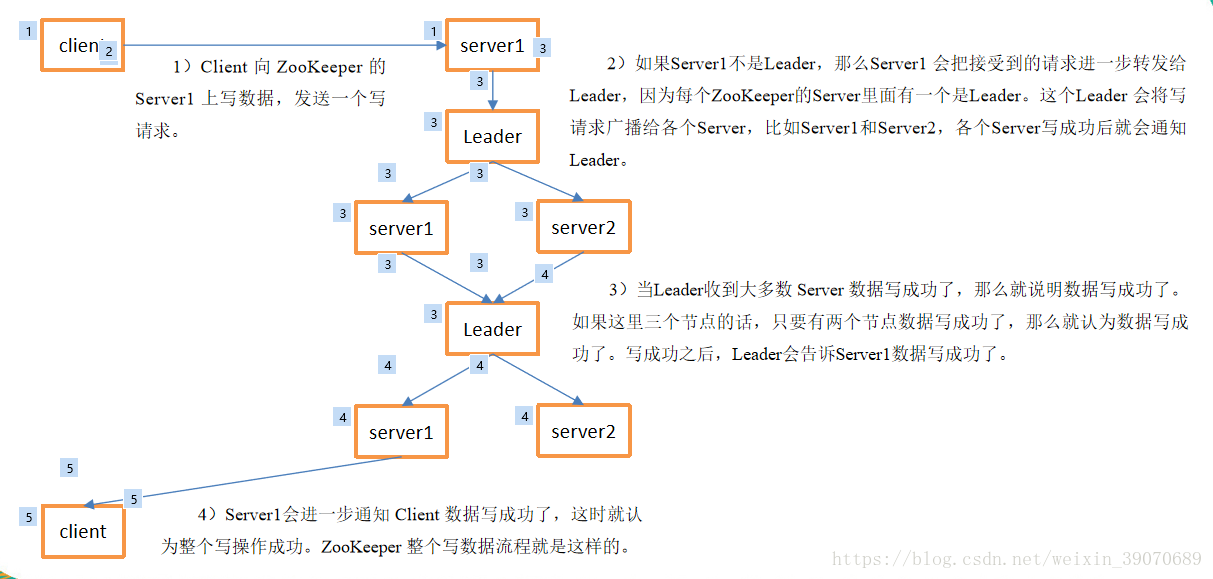
由上图可以看出当有半数以上的数据写成功后,leader就会通知某个server,server就会通知客户端写入数据成功,此时有部分未同步的节点,当其他的客户端读取时会出现滞后的系统视图,为了避免这种情况,应该在读取之前进行sync操作,该操作会强制服务器与leader的服务器视图保持一致。
zookeeper数据结构
可以把它理解为一个具有高可用的文件系统,但是里面没有文件合目录,统一使用节点znode的概念,znode中可> 以保存数据也可以保存其他的znode

四种类型的znode:
- PERSISTENT-持久化目录节点 ,客户端与zookeeper断开连接后,该节点依旧存在
- PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点 ,客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
- EPHEMERAL-临时目录节点,客户端与zookeeper断开连接后,该节点被删除
- EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点,客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号

















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









