







 本文深入解析数据库索引的重要性和工作原理,包括索引类型如主键、唯一键、普通键,以及索引的数据结构如B+tree、hash、bitmap等。通过对比聚集索引和非聚集索引,阐述了索引如何大幅提升查询效率,同时讨论了索引带来的写入性能影响。
本文深入解析数据库索引的重要性和工作原理,包括索引类型如主键、唯一键、普通键,以及索引的数据结构如B+tree、hash、bitmap等。通过对比聚集索引和非聚集索引,阐述了索引如何大幅提升查询效率,同时讨论了索引带来的写入性能影响。
1、为什么要使用索引?
索引是数据库查询的一种高效方式,避免全表扫描,快速查询数据。
2、什么样的信息可以成为索引?
主键、唯一键、普通键
3、索引的数据结构
- 二叉查找树索引
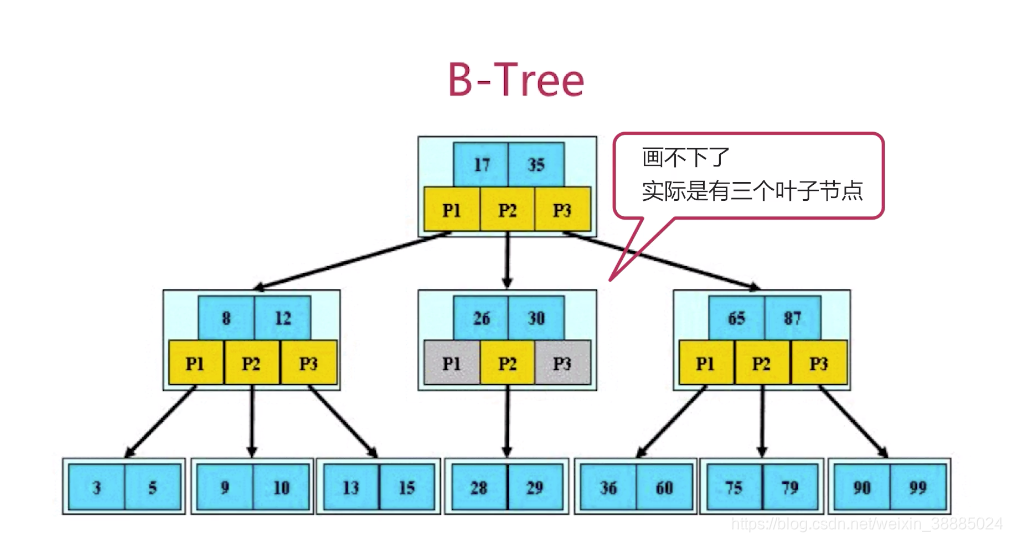
- B tree索引
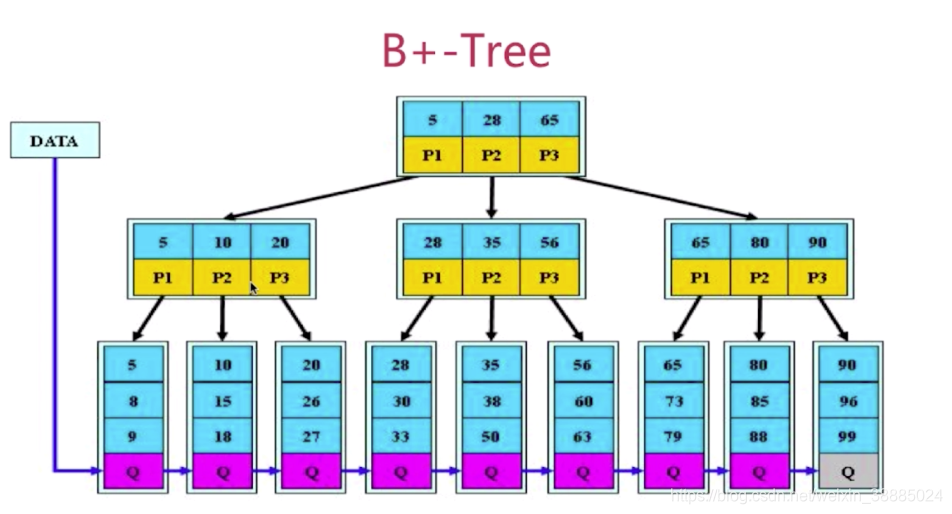
- B+ tree索引 【目前流行】
- hash索引
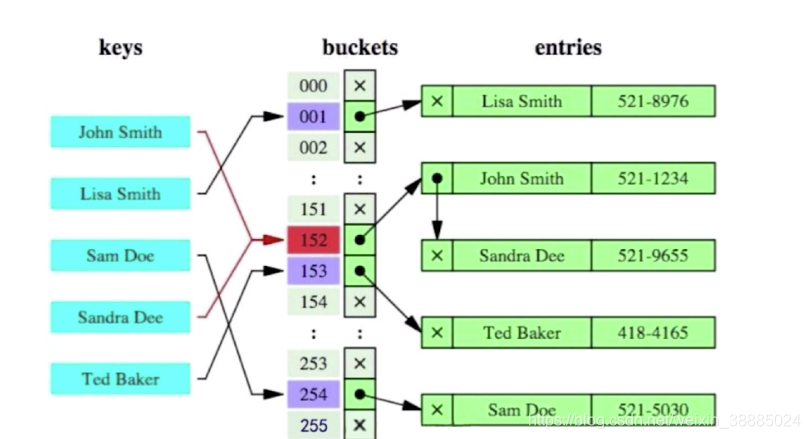
- bitmap索引 【位图索引】
平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。
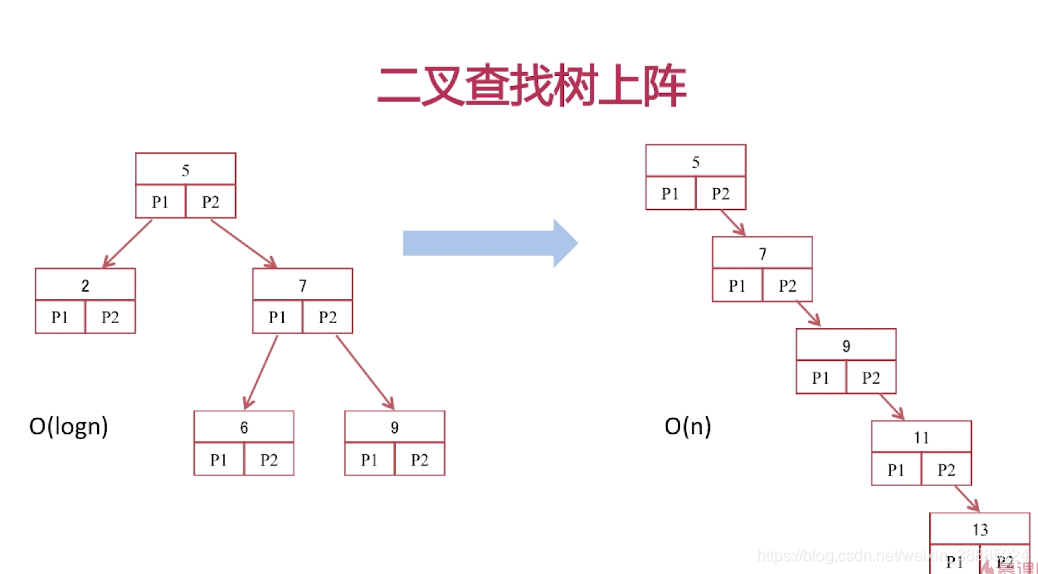
一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。
用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。
然而, 事物都是有两面的, 索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
二叉查找树
B Tree


B+ Tree


Hash

BitMap
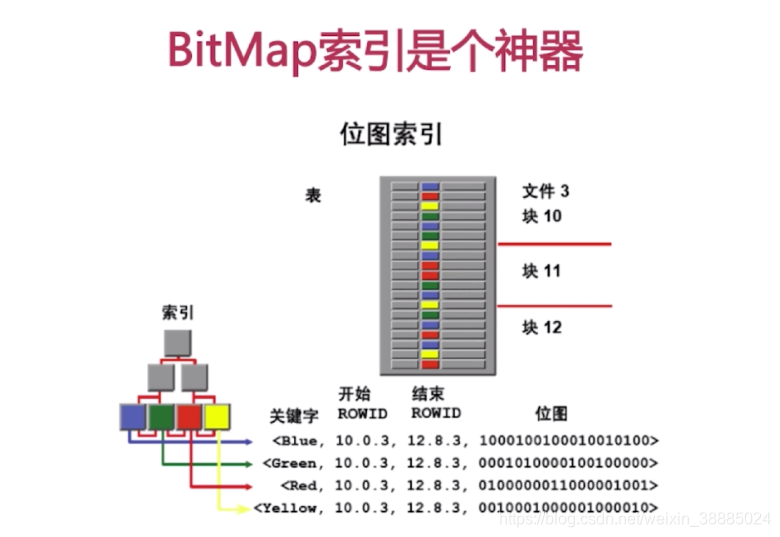
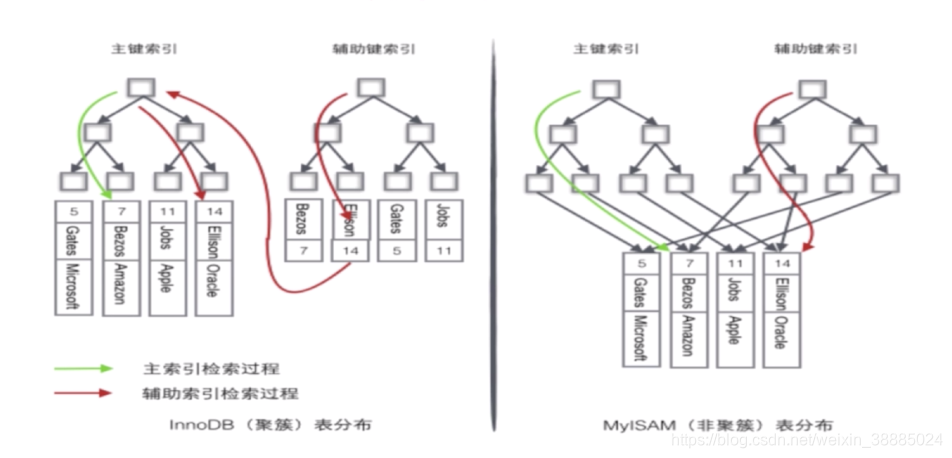
4、密集索引和稀疏索引的区别
| 区别 | 密集索引 | 稀疏索引 |
|---|---|---|
| 索引值 | 每一个搜索码对应一个索引值 | 只为索引码的某些值建立索引项 |
InnoDB 【密集索引】

MyISAM 【稀疏索引】

















 6041
6041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









