







本次要爬取的是糗事百科,地址如下:http://www.qiushibaike.com/8hr/page/1
1.思路分析:
url地址的规律非常明显,一共只有13页url地址
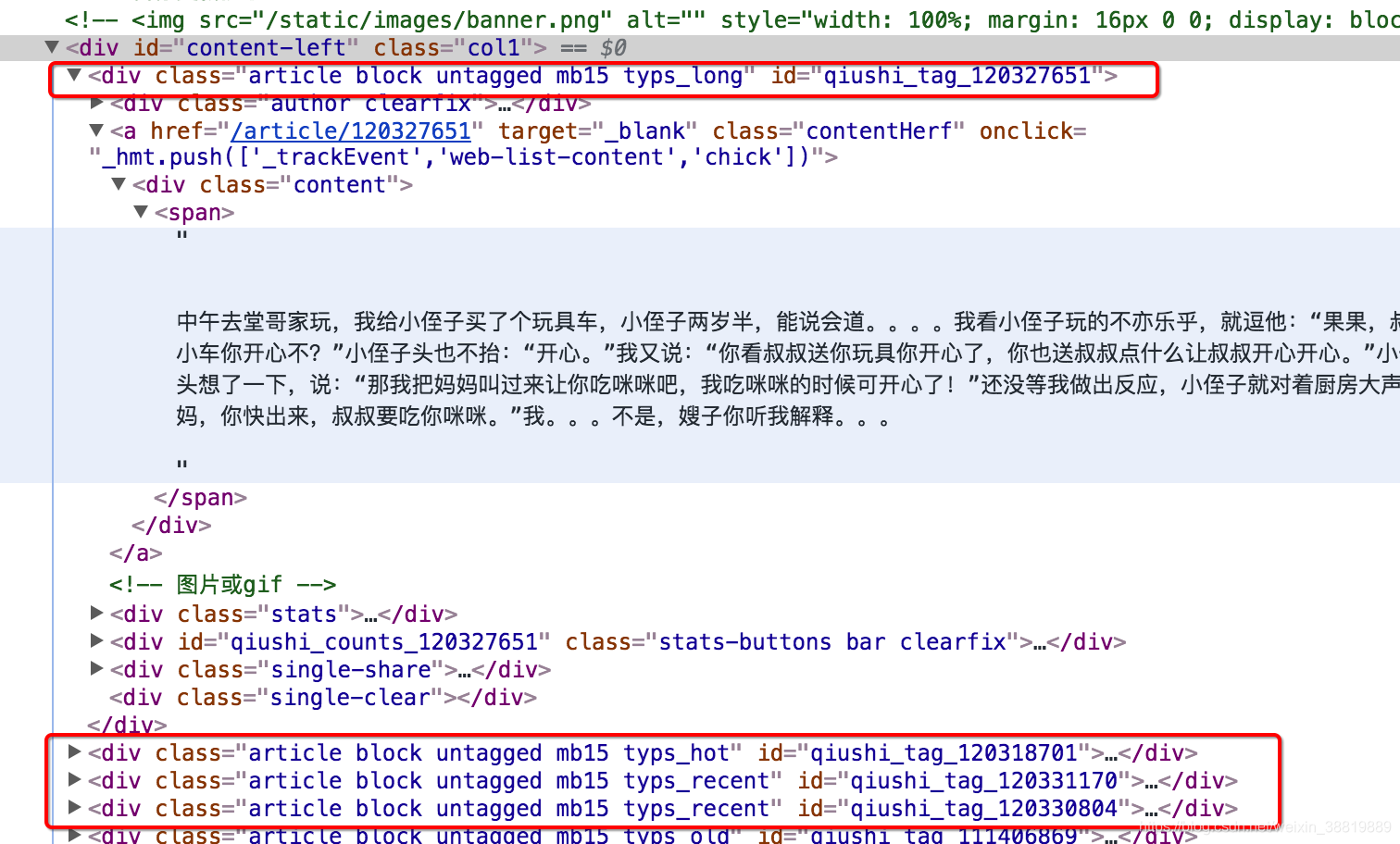
2.确定数据的位置
数据都在id='content-left’的div下的div中,在这个区域,url地址对应的响应和elements相同
3.糗事百科代码实现
import requests
from lxml import etree
import time
class QiuBai:
def __init__(self):
self.temp_url = "http://www.qiushibaike.com/8hr/page/{}"
self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
def get_url_list 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









