







 本文介绍了如何使用Python爬取糗事百科,重点在于筛选出无图片的段子。通过正则表达式匹配发布人、日期、内容和点赞数,并过滤掉含有图片的条目。最终,程序将生成txt和xls文件,存储爬取的数据。
本文介绍了如何使用Python爬取糗事百科,重点在于筛选出无图片的段子。通过正则表达式匹配发布人、日期、内容和点赞数,并过滤掉含有图片的条目。最终,程序将生成txt和xls文件,存储爬取的数据。
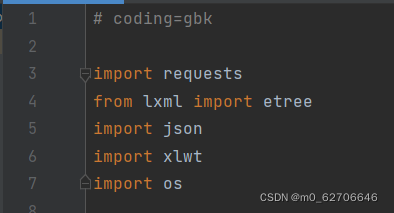
所需要引入的库,python版本号不同,加入#coding=gbk,避免正文中出现中文时报错。
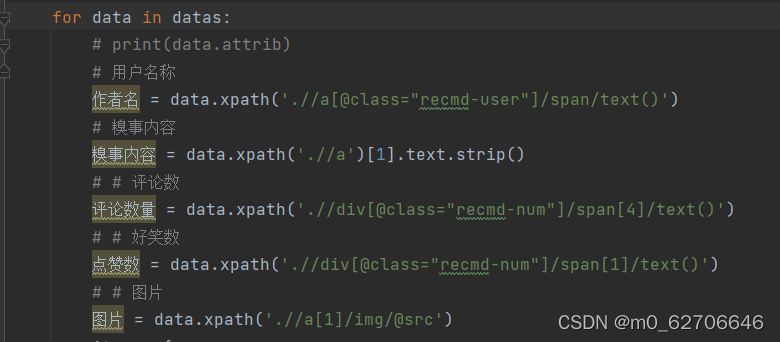
爬取的内容,跟路径在开发者模式中选择

包裹的内容。 现在我们想获取发布人,发布日期,段子内容,以及点赞的个数。不过另外注意的是,段子有些是带图片的,如果我们想在控制台显示图片是不现实的,所以我们直接把带有图片的段子给它剔除掉,只保存仅含文本的段子。 所以我们加入如下正则表达式来匹配一下,用到的方法是 re.findall 是找寻所有匹配的内容。方法的用法详情可以看前面说的正则表达式的介绍。 好,我们的正则表达式匹配语句书写如下,在原来的基础上追加如下代码

现在正则表达式在这里稍作说明 1).? 是一个固定的搭配,. 和代表可以匹配任意无限多个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









