



 本文深入解析Druid的查询机制,包括broker节点如何分发查询请求,以及历史节点的处理流程。介绍了查询链的构建过程,针对线上业务中小查询速度慢的问题,提出了动态优先级查询的解决方案,并评估了其效果。
本文深入解析Druid的查询机制,包括broker节点如何分发查询请求,以及历史节点的处理流程。介绍了查询链的构建过程,针对线上业务中小查询速度慢的问题,提出了动态优先级查询的解决方案,并评估了其效果。
一、查询原理介绍
1、Druid broker节点的总体流程
Druid的broker节点是直接提供对外数据查询服务的,它把查询请求分发到实时节点和历史节点,将他们返回的数据做进一步的合并加工然后返回给调用方。它充当着查询路由角色,它存储了每个datasource的每个segment的列表 以及在集群节点meta信息,以便于将查询路由至正确的节点。
用户只需要提供固定格式的查询json,向broker 发生http请求,就可以获得broker的查询服务:
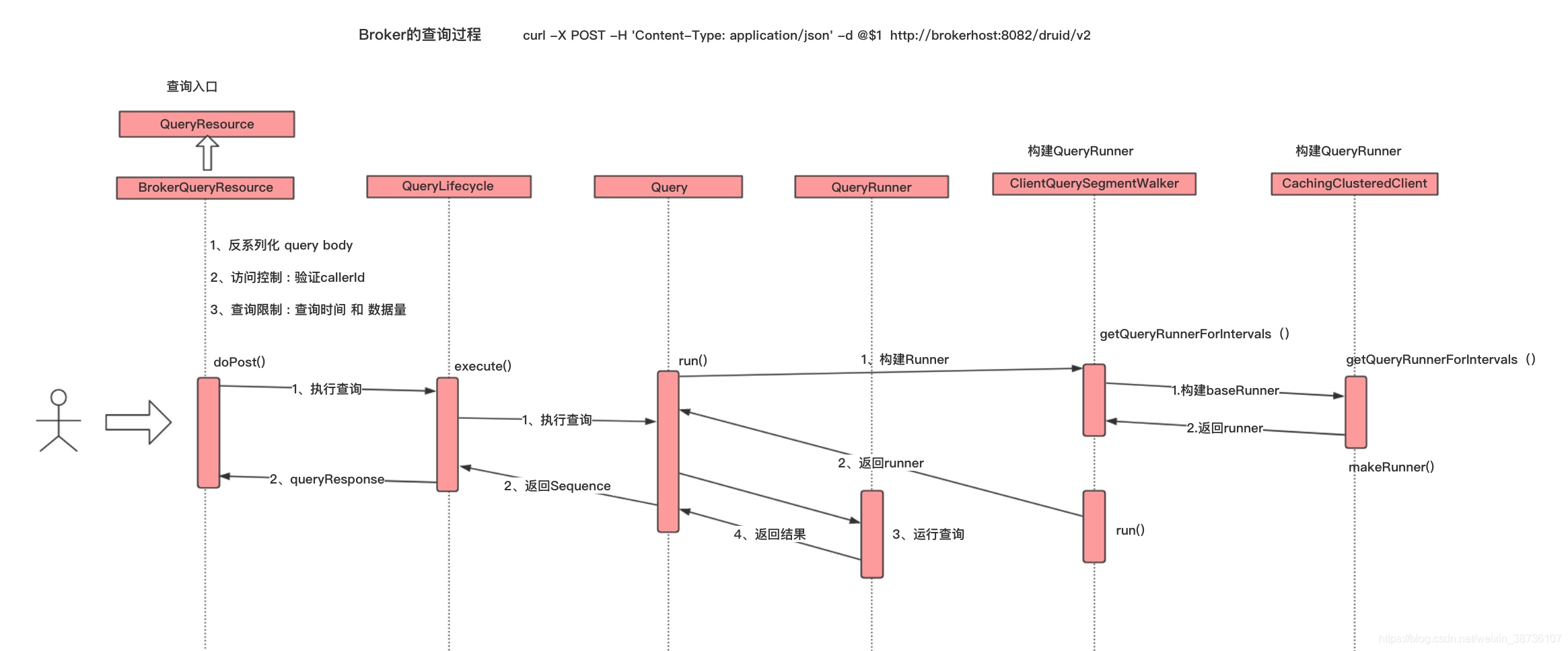
上图展示Druid的关键查询过程,其中的主要组件包括:
QueryResource 作为查询的入口,我们在QueryResource上继承一个BrokerQueryResource类用于查询的一些权限控制。
ClientQuerySegmentWalker,根据查询的interval 或者segment构建QueryRunner
QueryRunner 采用了调用链和装饰设计模式,通过嵌套方式实现责任链,每一个最终被转换为一个查询QueryRunner的链表,每一个QueryRunner只负责一段查询。
2、查询链的构建
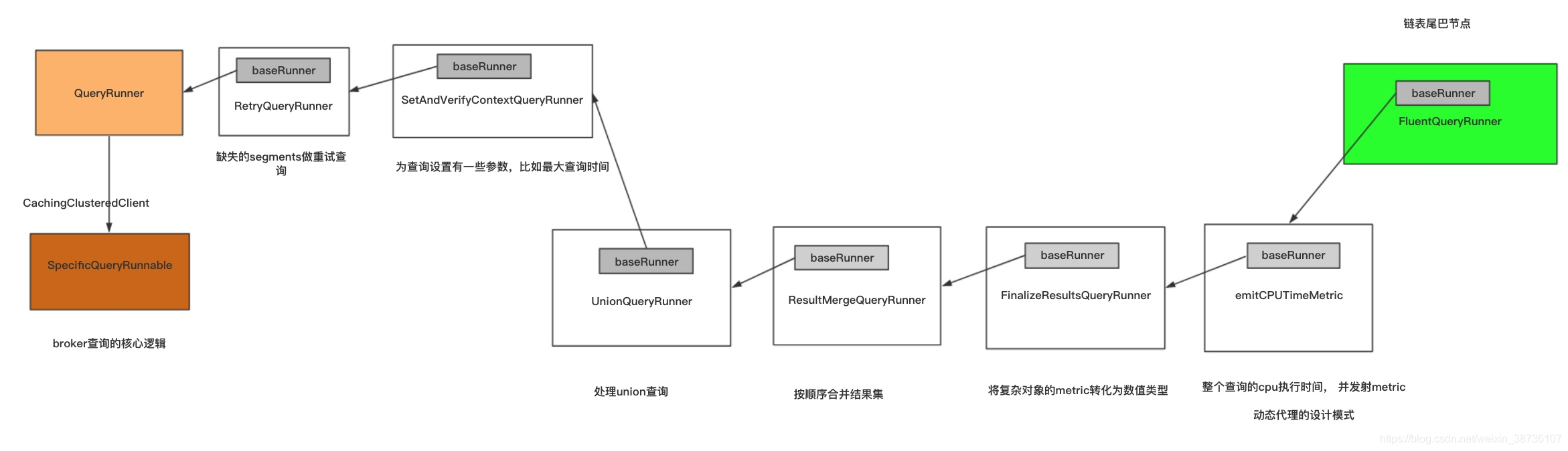 上图所示,展示broker构建的一个查询链表,每一个查询对应的核心Runner不同(最左端的SpecificQueryRunnable),但是每一个查询还有很多相同的逻辑,比如Metric性能 指标的收集,缓存的使用,结果的合并,这些共同的功能被封装在QueryRunner责任链的一个个节点中去处理(如上图中的左边的一些列白色的节点)。
上图所示,展示broker构建的一个查询链表,每一个查询对应的核心Runner不同(最左端的SpecificQueryRunnable),但是每一个查询还有很多相同的逻辑,比如Metric性能 指标的收集,缓存的使用,结果的合并,这些共同的功能被封装在QueryRunner责任链的一个个节点中去处理(如上图中的左边的一些列白色的节点)。
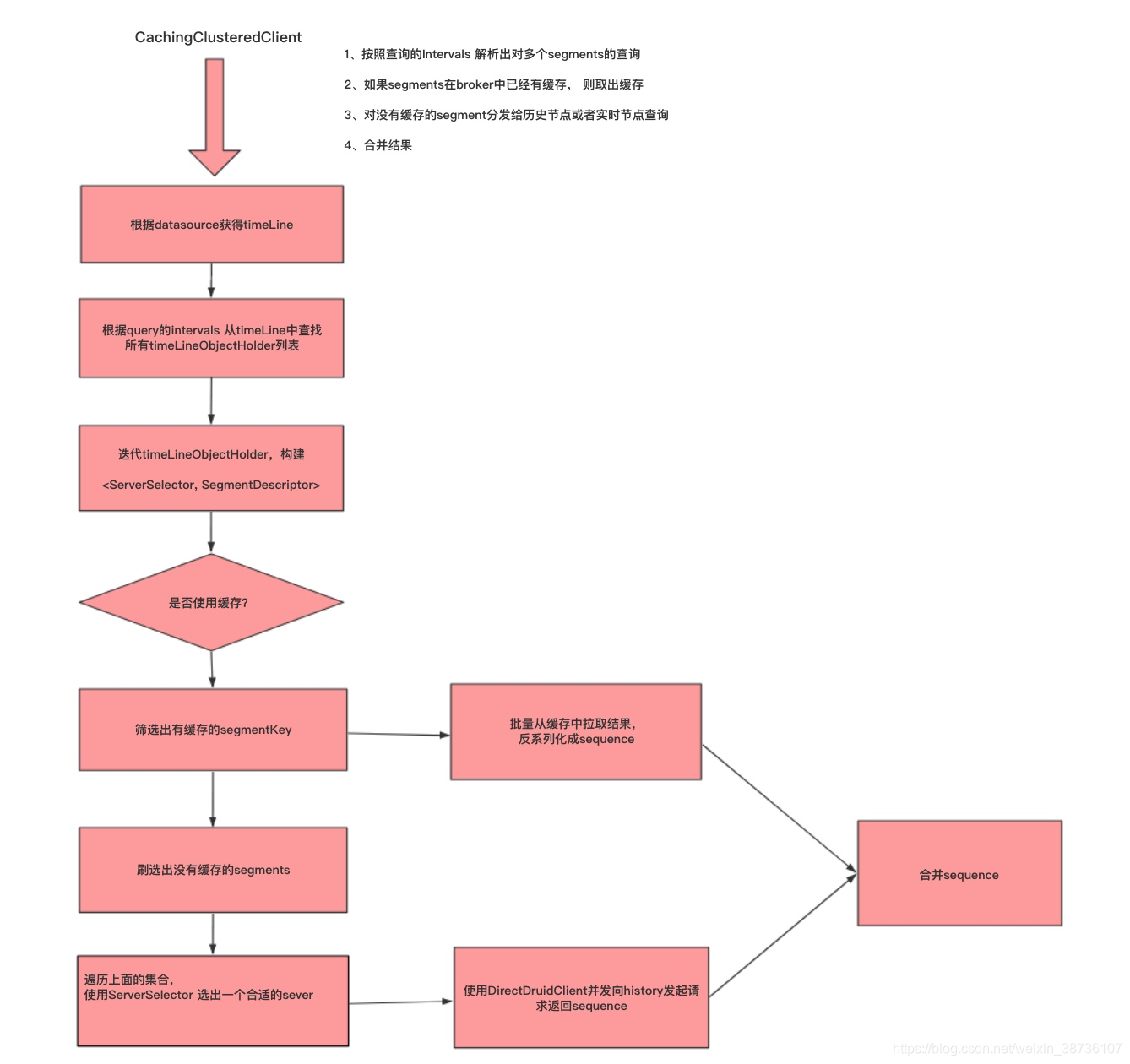
CachingClusteredClient 是broker查询的核心类,broker 能够把一个query拆分成一个个不同的segments的查询,并分发到对应的history或者实时节点上 进行查询,然后合并返回的结果,具体的执行流程如下图所示:
3、Druid histroy节点的总体流程
下图从源码层面分析histroy端接收到query之后的处理流程:
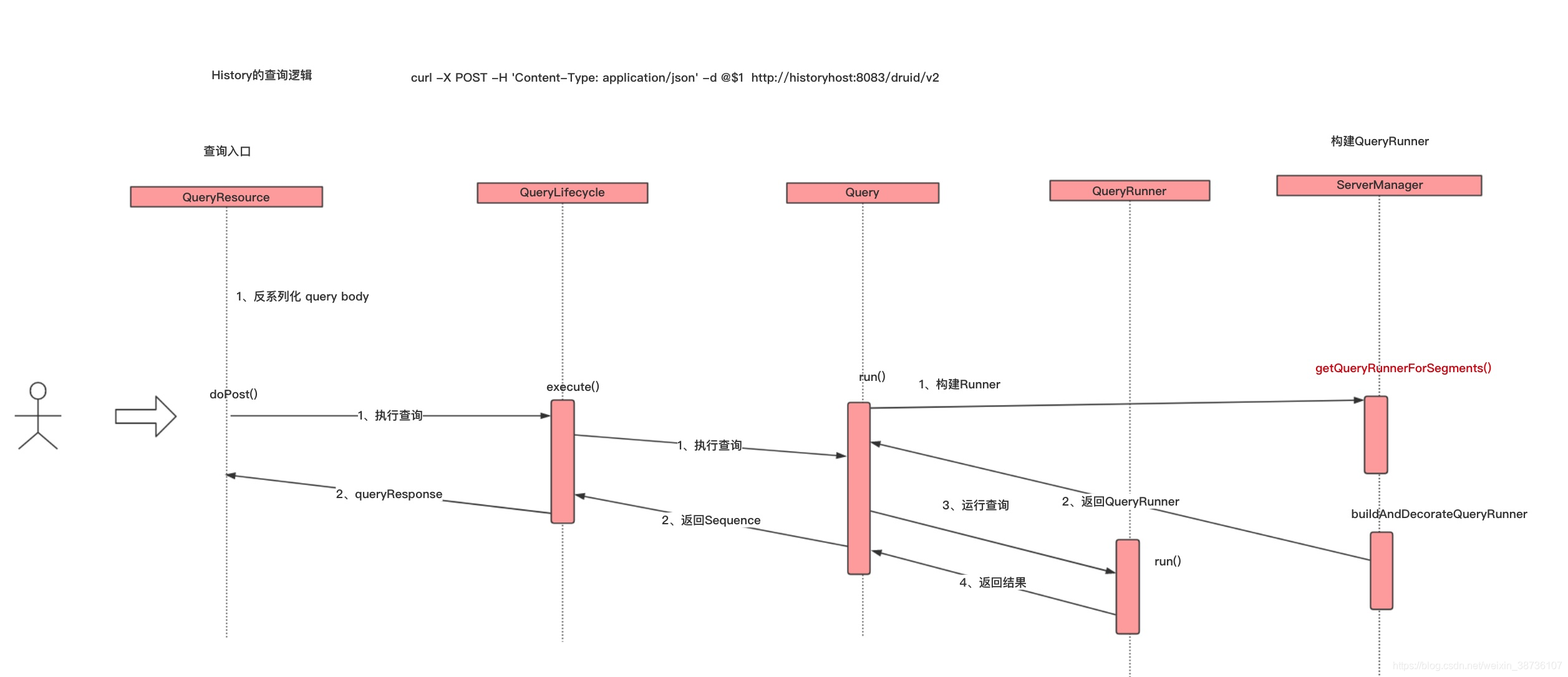
4、查询链的构建
histroy接收到query之后的也要经历一次QueryRunner链的构建过程:
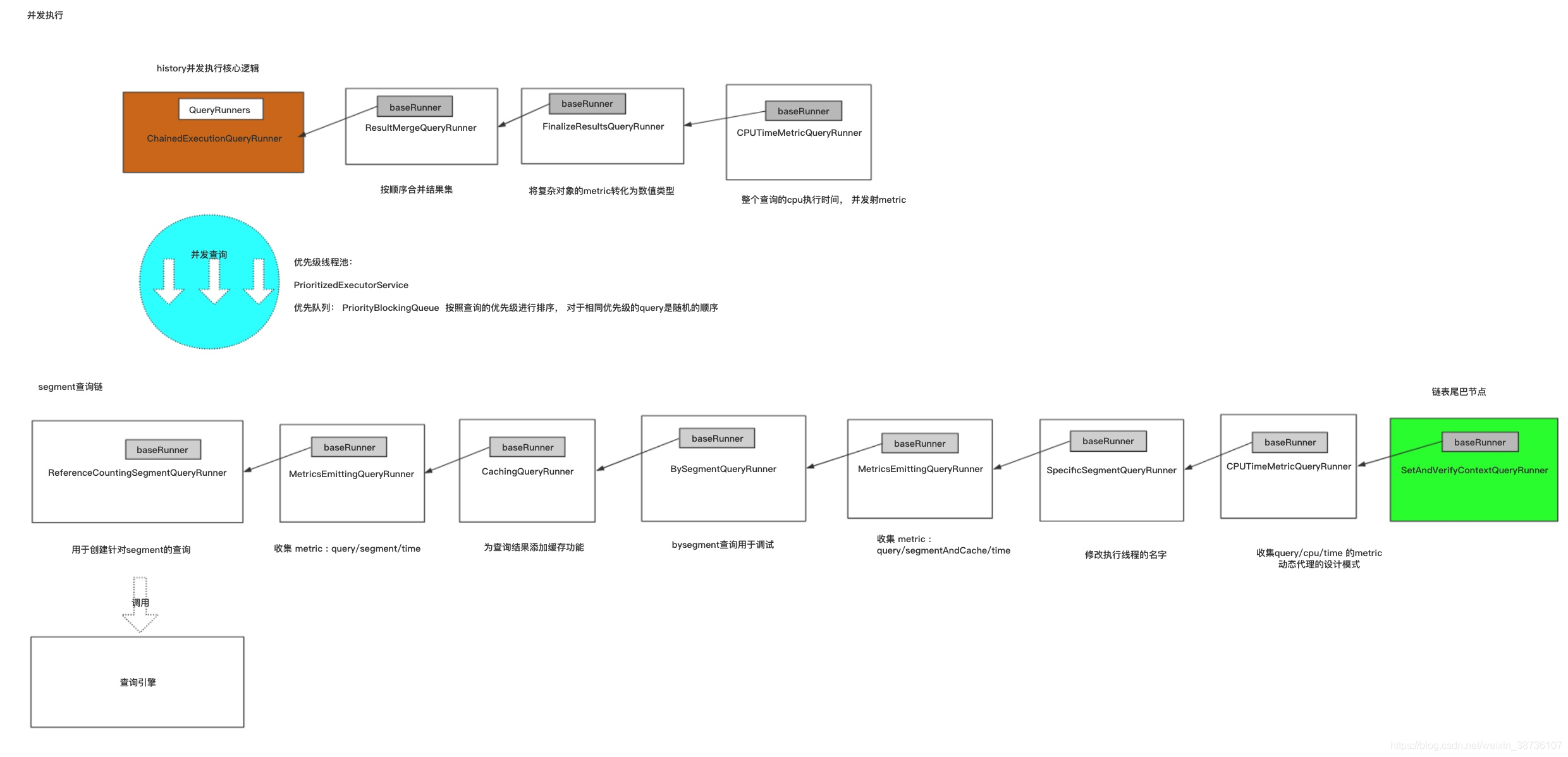
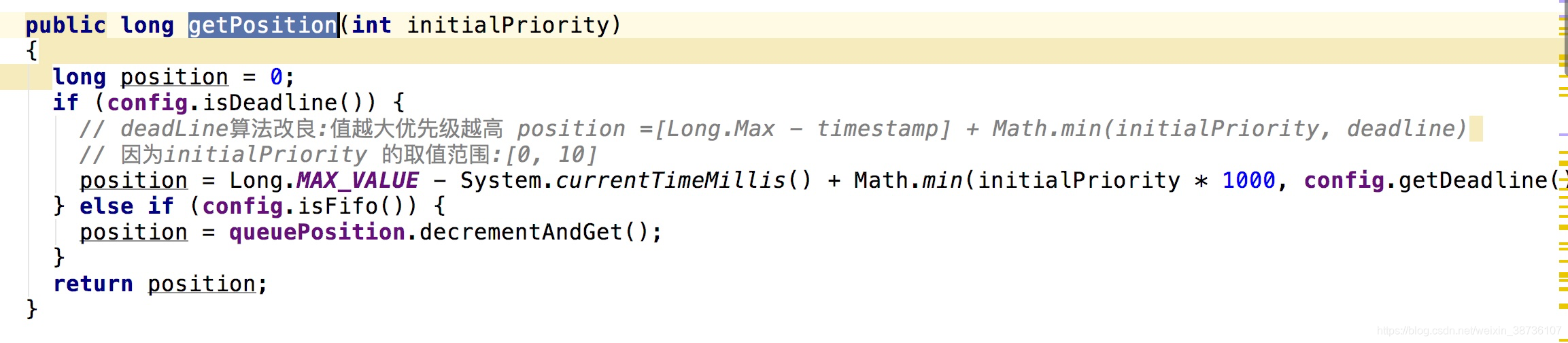
ChainedExecutionQueryRunner作为history的核心类,其中有一个优先级线程池,队列里面对不同的优先级的查询进行了排序。为了预防优先级低的查询产生饥饿现象,我们对该优先级线程池进行了改造
deadLine算法改良: 值越大优先级越高 position =[Long.Max - timestamp] + Math.min(initialPriority, deadline)
5、实践中出现的问题
线上业务经常发现很多小查询速度很慢,严重要甚至把一个history查挂的地步。
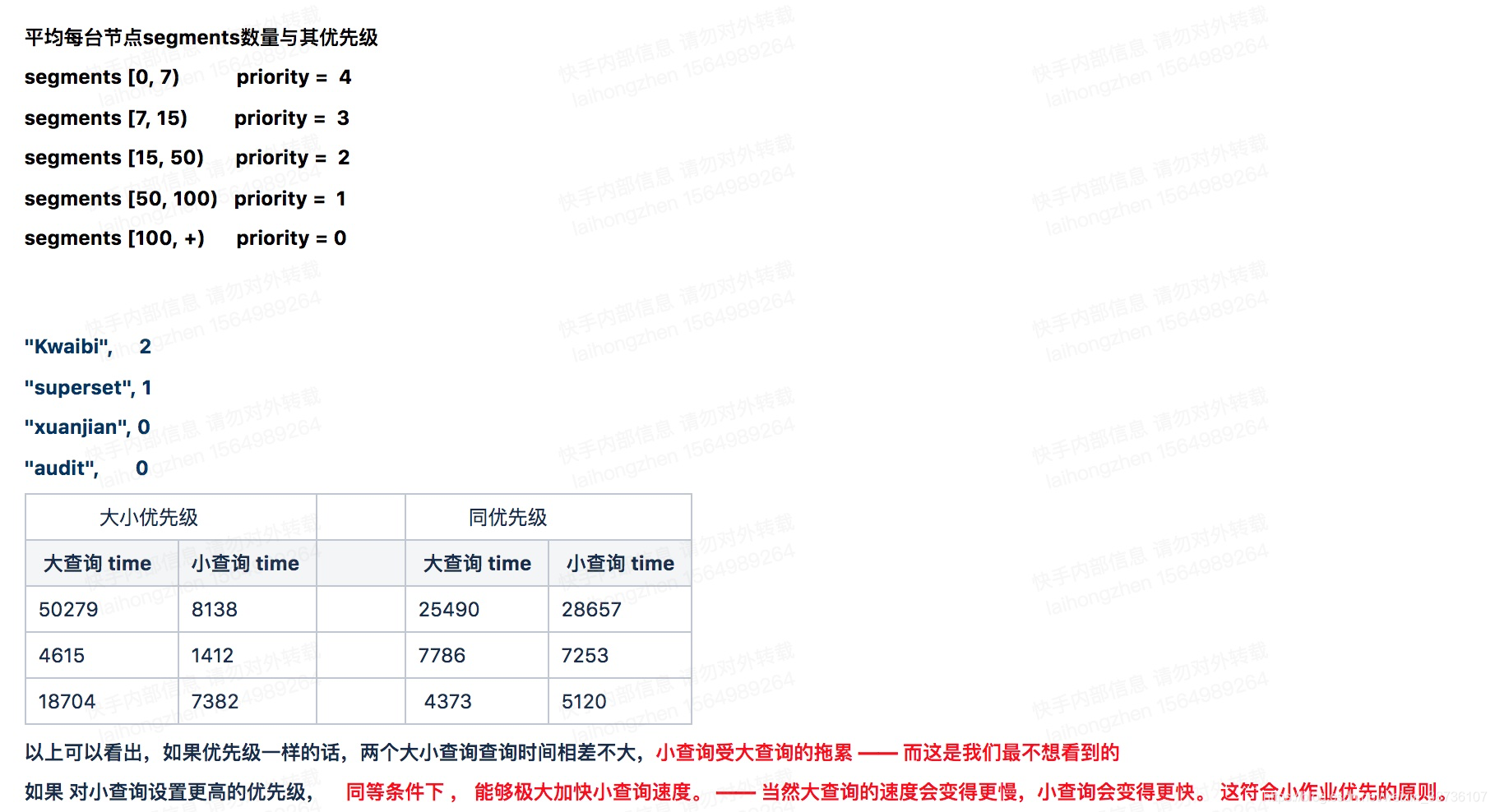
6、Druid动态优先级查询的设计与实现
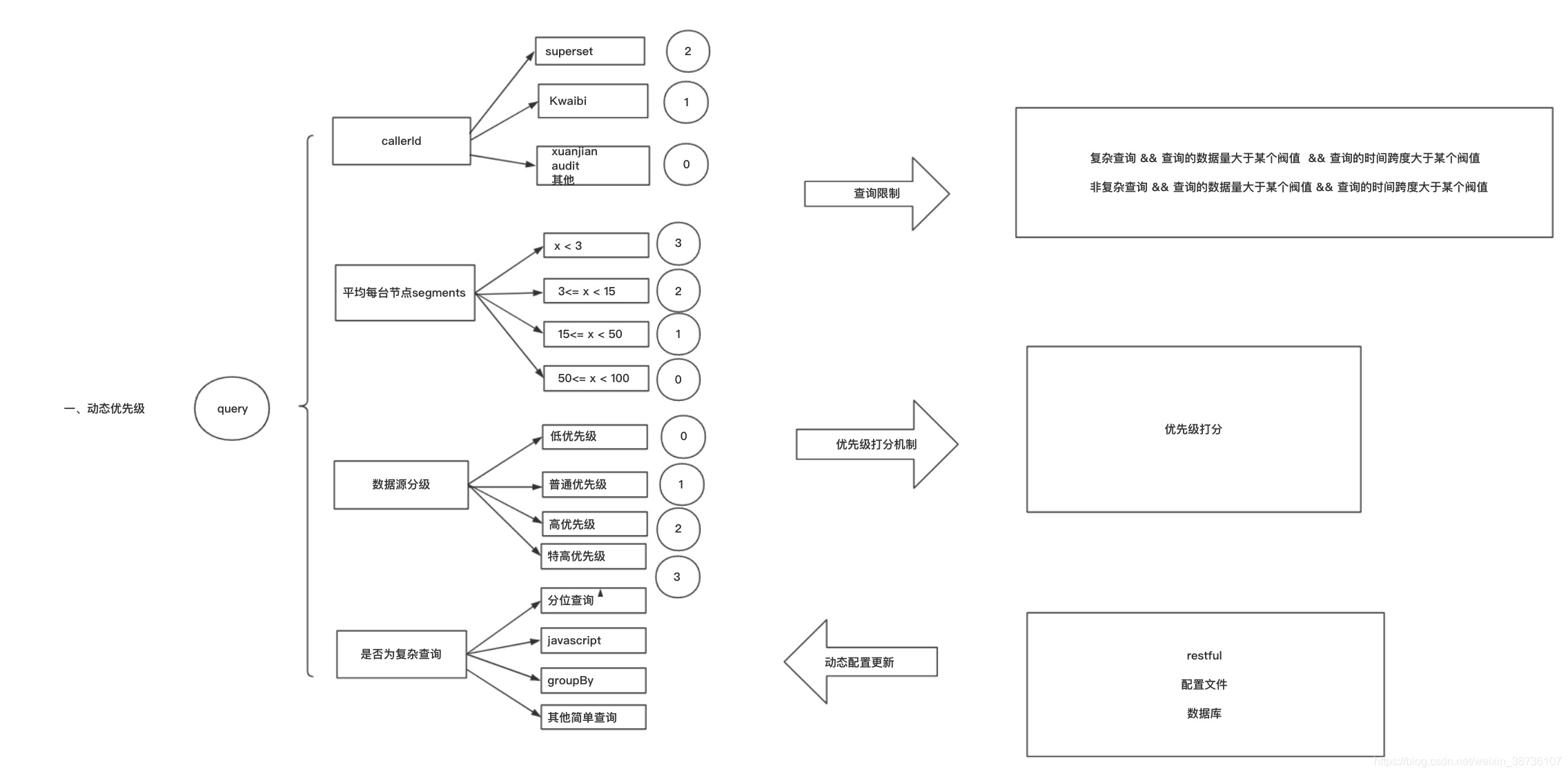
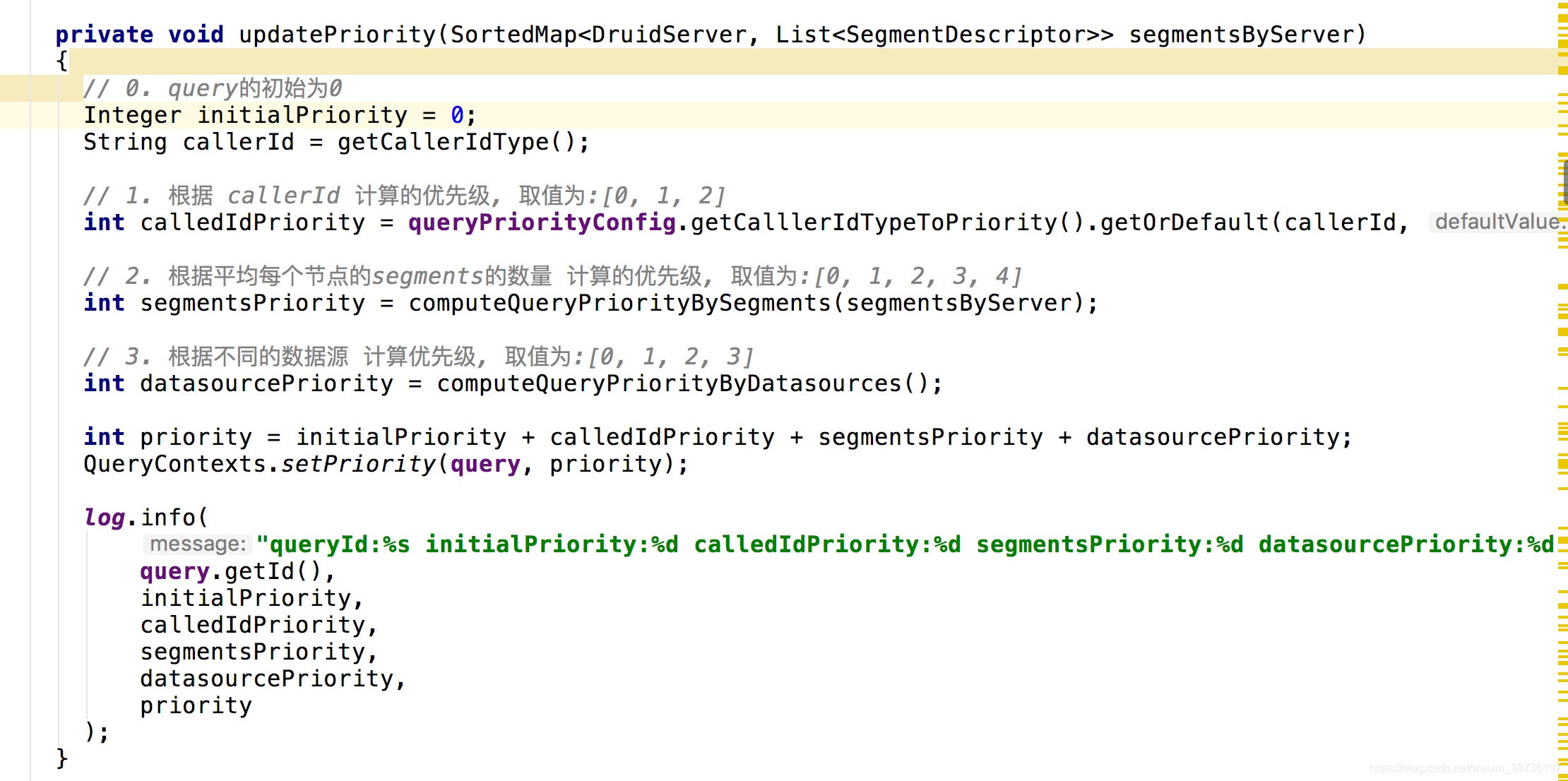
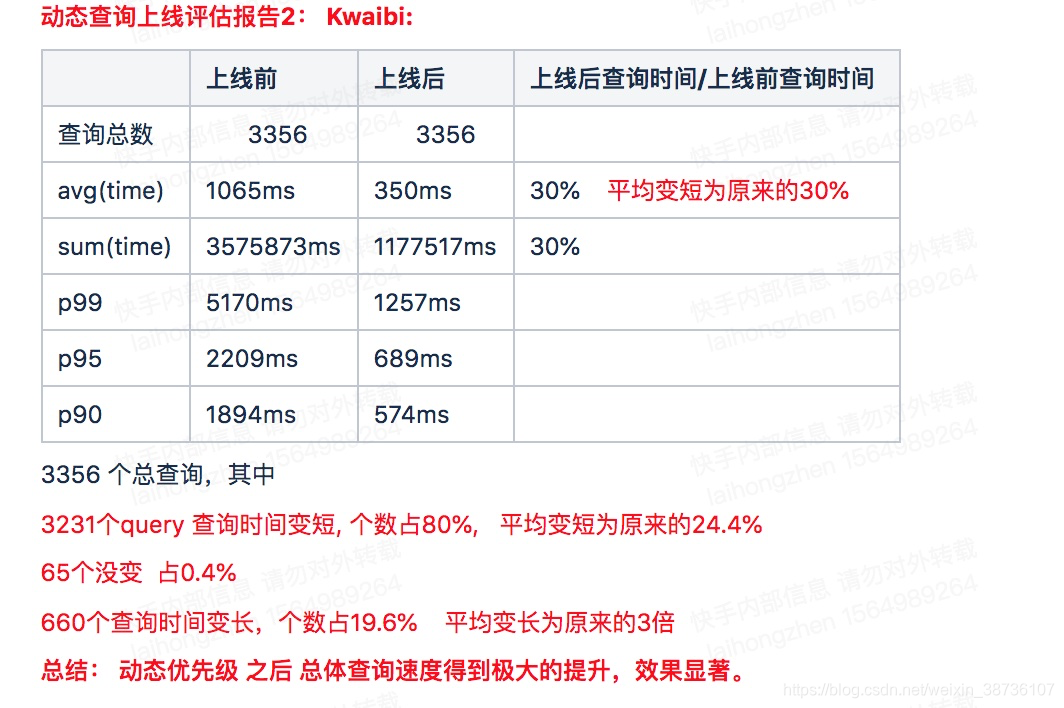
7、效果评估

















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









