






MySQL主从同步延迟案例分析:一次误操作引发的思考。
一、事件背景
上周五接到用户提供的34行核心数据查询需求,为避免使用IN查询的性能瓶颈,我选择创建临时表进行JOIN查询。通过Navicat导入包含34万行记录的临时表,但是后面用户又发了一版最新的,于是我选择了导入向导的Copy。该操作最终导致基于MHA搭建的MySQL主从架构出现4小时同步延迟,造成依赖从库的报表系统服务中断。
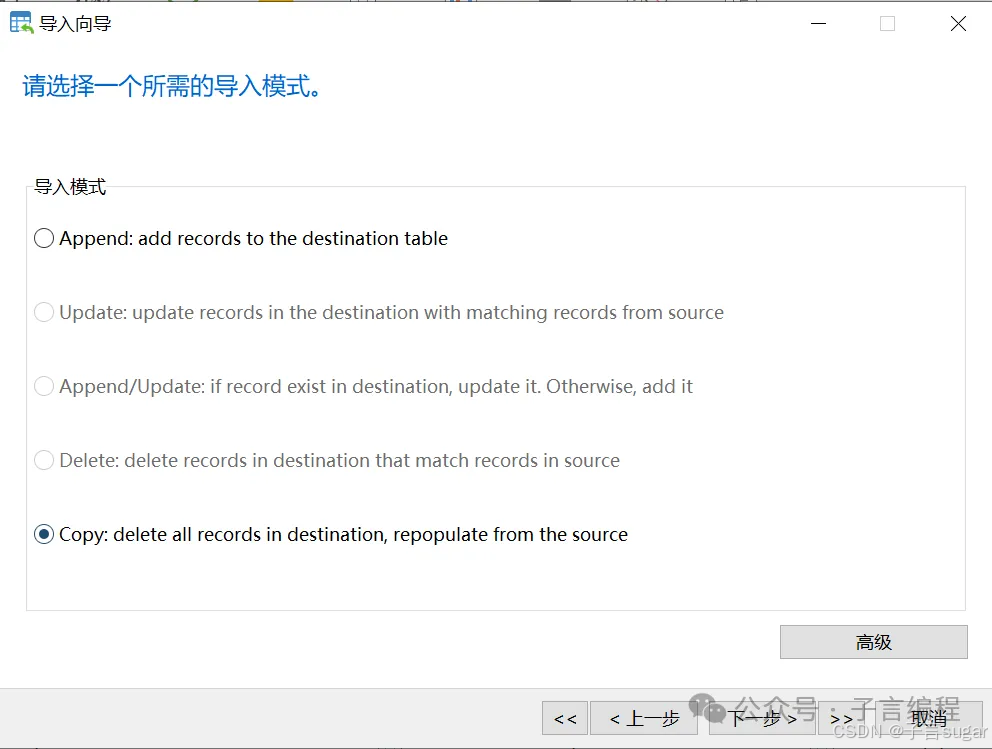
二、问题定位与分析
-
Row格式复制特性:MySQL在row模式下记录每行数据的变更详情
-
服务器性能
-
存在其他瓶颈(如锁竞争、索引缺失等)
三、解决方案
联系了总部DBA,因为是生产环境,生产线还在操作,为防止数据丢失,总部DBA也不敢操作,主库正常,因此临时将报表的数据库连接改到了主库,等待从库的语句执行完成,最终4个小时后恢复正常
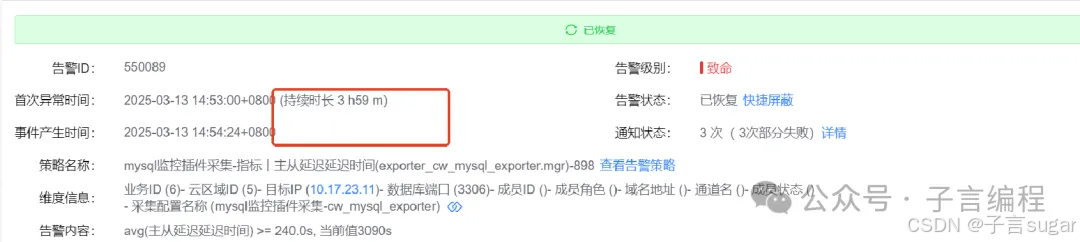
四、延伸思考
出现事故后,第一时间我也在思考,为什么会出现这样的问题。以前用Oracle也没这样啊,问问deepseek吧,恍然大悟。
| 场景 | MySQL(ROW模式) | Oracle(逻辑/物理备库) |
|---|---|---|
| 全表删除 | 从库逐行删除,耗时长,延迟高。 | 直接批量删除,耗时与主库接近。 |
| 锁竞争 | 逐行删除可能加剧行锁或表锁竞争。 | 物理备库无锁竞争;逻辑备库批量操作锁竞争小。 |
| 网络/IO压力 | Binlog体积大(记录所有行数据),传输和回放压力大。 | Redo日志或高效SQL传输,资源占用低。 |
总部dba为了保持数据一致,用的就是mysql的row模式
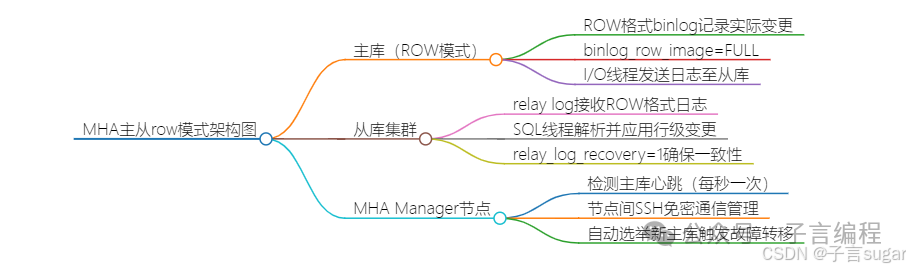
五、经验总结
-
机制认知差异:不同数据库的复制实现需要深入理解
-
批量操作原则:
-
单事务操作不超过50万行
- 大事务拆分为批次处理
-
-
环境隔离:报表系统应使用独立从库,设置延迟阈值告警
-
变更管理:执行DDL前必须进行影响评估


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









