










1、数据集制作
1.1数据文件夹创建
创建如图下所示的文件夹:
VOCdevkit
VOC2007
Annotations ----> Annotations用于存放使用labelImg生成的标记(XML)文件
JPEGImages ----> 存放对应的图片(jpg)文件
labels ----> 存放XML文件中类别标记和归一话的矩形框坐标
ImageSetsMain
test.txt
train.txt
trainval.txt
val.txt
文件夹Main下四个文本文件用来提取图片名作为训练集或测试集
1.2 训练集与测试集划分
使用以下的python脚本为Main文件夹下的四个文本文件填充内容
##get.py()##
#encoding=utf-8
import os
import random
xmlfilepath='/home/user/darknet/scripts/VOCdevkit/VOC2007/Annotations' #改成自己的Annotations目录
saveBasePath='/home/user/darknet/scripts/VOCdevkit/VOC2007/ImageSets' #改成自己的ImageSets目录用于寻找Main目录保存之前提到的四个txt文件
trainval_percent=0.7 # 根据自己的数据集设置划分比例
train_percent=0.7
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'Main/val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
执行以上python脚本,相应的图片名就会写入以上四个文本文件中。
1.3 运行脚本voc_label.py生成绝对路径及标注信息
将VOCdevkit文件夹移动至darknet目录下的scripts目录下。目录下默认有一个voc_label.py文件,该文件用于将Main目录下的txt的图片名的绝对路径保存到scripts目录下的train.txt、2007_train.txt 、2007_val.txt、 2007_test.txt、train.all.txt文件中来。同时,将xml文件转换为labels文件夹中对应的txt文件,txt文件中存放的是每个标记的类别下标,以及归一化的标记矩形框的坐标。
运行voc_label.py脚本之前的修改:
- 将sets=[(‘2012’, ‘train’), (‘2012’, ‘val’),(‘2007’, ‘train’), (‘2007’, ‘val’), (‘2007’, ‘test’)]改为:sets=[(‘2007’, ‘train’), (‘2007’, ‘val’), (‘2007’, ‘test’)],因为我们这里只使用了2007数据集。
- 将classes = [" "] 改为自己的类别名,作者这里只使用了一类标签所以改为:classes = [“insulator”]
- 将os.system(“cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt> train.txt”)改为:os.system(“cat 2007_train.txt 2007_val.txt > train.txt”)
- 将os.system(“cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_val.txt 2012_test.txt > train.all.txt”)改为:os.system(“cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt”)
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["insulator"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt")
2 修改配置文件
- 修改data/voc.names
- 修改cfg/yolov3-tiny.cfg
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=2
######################
batch=64
subdivisions=2
width=52
height=52
#根据显存调节这几个
#################
#每一个yolo层和其前面的卷积曾都要修改
[convolutional]
filters=18 # 改成3*(classes + 5),# 该处只有一种类别
[yolo]
classes=1
random=0 # 显存不够改成0
- 修改cfg/voc.data
classes= 1 # 实际需要识别的类
train = /home/ubuntu/darknet/scripts/2007_train.txt # 指向刚刚生成的文件2007_train.txt
valid = /home/ubuntu/darknet/scripts/2007_val.txt # 指向刚刚生成的文件2007_val.txt
names = data/voc.names
backup = backup
- 修改examples文件夹下的detector.c、darknet.c
void validate_detector_flip(char *datacfg, char *cfgfile, char *weightfile, char *outfile)
{
int j;
list *options = read_data_cfg(datacfg);
char *valid_images = option_find_str(options, "valid", "data/train.list");
// char *name_list = option_find_str(options, "names", "data/names.list");
char *name_list = option_find_str(options, "names", "data/voc.names");
char *prefix = option_find_str(options, "results", "results");
char **names = get_labels(name_list);
char *mapf = option_find_str(options, "map", 0);
int *map = 0;
if (mapf) map = read_map(mapf);
float thresh = find_float_arg(argc, argv, "-thresh", .5);
char *filename = (argc > 4) ? argv[4]: 0;
char *outfile = find_char_arg(argc, argv, "-out", 0);
int fullscreen = find_arg(argc, argv, "-fullscreen");
// test_detector("cfg/coco.data", argv[2], argv[3], filename, thresh, .5, outfile, fullscreen);
test_detector("cfg/voc.data", argv[2], argv[3], filename, thresh, .5, outfile, fullscreen);
} else if (0 == strcmp(argv[1], "cifar")){
run_cifar(argc, argv);
3 模型编译及训练
sudo vi Makefile
修改Makefile如下:
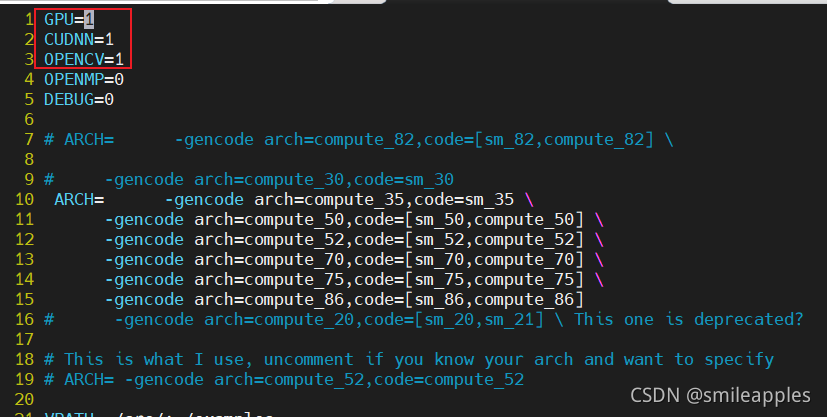
根据自己的环境修改Makefile,其中CUAD和OPENCV必须安装配置好,修改Makefile才能成功编译
make -j8
模型训练命令
./darknet detector test <data_cfg> <models_cfg> <weights> <test_file> [-thresh] [-out]
./darknet detector train <data_cfg> <models_cfg> <weights> [-thresh] [-gpu] [-gpus] [-clear]
./darknet detector valid <data_cfg> <models_cfg> <weights> [-out] [-thresh]
./darknet detector recall <data_cfg> <models_cfg> <weights> [-thresh]
'< >'必选项,’[ ]‘可选项
- data_cfg:数据配置文件,eg:cfg/voc.data
- models_cfg:模型配置文件,eg:cfg/yolov3-voc.cfg
- weights:权重配置文件,eg:weights/yolov3.weights
- test_file:测试文件,eg://*/test.txt
- -thresh:显示被检测物体中confidence大于等于 [-thresh] 的bounding-box,默认0.005
- -out:输出文件名称,默认路径为results文件夹下,eg:-out “” //输出class_num个文件,文件名为class_name.txt;若不选择此选项,则默认输出文件名为comp4_det_test_“class_name”.txt
- -i/-gpu:指定单个gpu,默认为0,eg:-gpu 2
- -gpus:指定多个gpu,默认为0,eg:-gpus 0,1,2
根据以上命令格式,训练自己的模型
./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









