






Title
题目
Semi-supervised medical image segmentation via weak-to-strong perturbation consistency and edge-aware contrastive representation
通过从弱到强的扰动一致性和边缘感知的对比表示实现半监督医学图像分割
01
文献速递介绍
自动语义分割在医学图像分析中起着至关重要的作用,它在各种分割任务中都展现出了卓越的性能,处于该领域的前沿水平(杨和法西乌,2023年;卢等人,2023年;古普塔等人,2022年;黄等人,2022年;陈等人,2023b;庄等人,2023年)。尽管全监督学习方法在语义分割中取得令人满意的性能方面至关重要,但它们对大量准确标注数据的依赖带来了挑战。获取带有逐像素标注的大规模数据集通常很困难,因为这既成本高昂又耗时。半监督学习为克服医学图像分析中标注数据稀缺所带来的挑战提供了一种潜在的解决方案。这些方法综合利用有限数量的带标注样本和足够大量的未标注样本,来有效地训练模型。 深度学习中主流的半监督学习方法主要包括一致性正则化(拉斯穆斯等人,2015年;塔尔瓦伊宁和瓦尔波拉,2017年;李等人,2022年)以及使用伪标签的自训练(范等人,2020年;白等人,2017年)。这些方法可以概括为:利用有限的带标注数据来训练一个初始网络,然后该网络用于为未标注数据生成伪标签,并对这些伪标签应用适当的约束,以提取隐藏在未标注数据中的丰富语义信息。这种策略同时利用了未标注数据和有限的强标注样本,来训练分割网络。 这些方法存在一个局限性。在引入图像级扰动后,它们对多次预测施加了适当的约束(例如一致性正则化)。然而,图像级扰动需要精心设计数据增强方式,并且所提供的增强数据的多样性有限(李等人,2021a)。相比之下,特征级扰动有助于在特征空间内进行更广泛的探索,使模型能够更好地利用未标注数据(杨等人,2023a)。因此,出现了一个明显的现象,即大多数半监督框架能够准确分割对象的主体区域,但在边缘区域的表现却不尽如人意。 为了克服这一局限性,许多现有的基于一致性的方法通过设计如多个解码器、金字塔结构或蒙特卡罗 dropout 等网络架构来生成多次预测,以便更好地利用未标注数据,但这些方法忽略了特征级有意义扰动的重要性,而这种扰动可以提高模型输出的可靠性和性能。受近期研究(瓦利等人,2020年;宫户等人,2018年;吴等人,2022年)的启发,这些研究表明特征的随机变化会导致不一致和不准确的预测,我们进一步观察到,对未标注数据引入扰动会在边缘区域引起显著变化。基于这一现象,我们提出了一种新颖的半监督学习框架,该框架结合了从弱到强的扰动用于一致性正则化,以及边缘感知对比学习,以有效地利用未标注数据实现准确的分割。具体而言,我们设计了一个共享编码器和多个解码器,每个解码器都配备了专门的从弱到强的扰动模块。这些语义层面的从弱到强的扰动模块在解码器的预测中引入细微的变化。然后,与这些预测相关的像素/体素级不确定性被用于获得一个不确定性加权聚合标签。为了引导模型学习可靠的预测区域,在解码器生成的预测与聚合标签之间施加特征扰动一致性。我们还为未标注数据定义了一个边缘感知对比损失,以提高在边缘区域的性能。这种对比损失通过不确定性排序精心选择正样本对,将模型的注意力引导到边缘区域。它促使边缘区域中属于同一类语义标签的像素的表示具有相似性,同时确保它们与不同类像素的表示具有差异性。 具体来说,我们的贡献总结如下: - 我们开发了一种从弱到强的特征扰动一致性方案,该方案促进了不同预测之间可靠区域的一致性。该方案由从弱到强的特征级扰动和特征扰动一致性组成。受先前工作(杨等人,2023b)的启发,所提出的特征扰动在通道维度上纳入了额外的统计信息,并在模型中采用了不同的集成方式。该方案使我们的模型能够专注于学习可靠的预测,并减轻不可靠区域的负面影响,从而实现更有效的训练。 - 我们提出了一种新颖的边缘感知对比损失,它有效地利用了类判别性表示,尤其是在边缘区域。这个损失函数通过在不确定性的引导下从对象边缘采样正样本像素,提高了类边缘之间的判别力,从而在边缘区域实现了令人瞩目的分割性能。 - 在二维和三维数据集上针对病变和器官分割进行的大量评估表明了我们方法的优越性,在半监督分割方面取得了新的最先进的性能。
Abatract
摘要
Despite that supervised learning has demonstrated impressive accuracy in medical image segmentation, itsreliance on large labeled datasets poses a challenge due to the effort and expertise required for data acquisition. Semi-supervised learning has emerged as a potential solution. However, it tends to yield satisfactorysegmentation performance in the central region of the foreground, but struggles in the edge region. In thispaper, we propose an innovative framework that effectively leverages unlabeled data to improve segmentationperformance, especially in edge regions. Our proposed framework includes two novel designs. Firstly, weintroduce a weak-to-strong perturbation strategy with corresponding feature-perturbed consistency loss toefficiently utilize unlabeled data and guide our framework in learning reliable regions. Secondly, we proposean edge-aware contrastive loss that utilizes uncertainty to select positive pairs, thereby learning discriminativepixel-level features in the edge regions using unlabeled data. In this way, the model minimizes the discrepancyof multiple predictions and improves representation ability, ultimately aiming at impressive performance onboth primary and edge regions. We conducted a comparative analysis of the segmentation results on thepublicly available BraTS2020 dataset, LA dataset, and the 2017 ACDC dataset. Through extensive quantificationand visualization experiments under three standard semi-supervised settings, we demonstrate the effectivenessof our approach and set a new state-of-the-art for semi-supervised medical image segmentation.
尽管监督学习在医学图像分割方面已经展现出了令人瞩目的准确性,但其对大量带标注数据集的依赖构成了一个挑战,因为数据采集需要耗费大量精力且要求具备专业知识。半监督学习已成为一种潜在的解决方案。然而,半监督学习往往在前景区的中心区域能够产生令人满意的分割性能,但在边缘区域却表现不佳。 在本文中,我们提出了一个创新的框架,该框架能够有效地利用未标注数据来提升分割性能,尤其是在边缘区域。我们提出的框架包含两项新颖的设计。首先,我们引入了一种从弱到强的扰动策略,并结合相应的特征扰动一致性损失,以便高效地利用未标注数据,并引导我们的框架学习可靠的区域。其次,我们提出了一种边缘感知对比损失,它利用不确定性来选择正样本对,从而利用未标注数据在边缘区域学习具有判别性的像素级特征。 通过这种方式,该模型能够最小化多次预测之间的差异,并提高表征能力,最终旨在在主要区域和边缘区域都取得优异的性能。我们对公开可用的BraTS2020数据集、LA数据集以及2017年ACDC数据集上的分割结果进行了对比分析。通过在三种标准半监督设置下进行的大量量化和可视化实验,我们证明了我们方法的有效性,并为半监督医学图像分割树立了新的最先进水平。
Method
方法
The objective of this study is to present a comprehensive semisupervised learning framework that effectively utilizes unlabeled dataand learns discriminative pixel-wise representations, especially in edgeregions. To achieve it, we introduce a novel weak-to-strong featurelevel perturbation strategy with consistency loss and edge-aware contrastive loss. These components enable the model to leverage sufficient semantic information from the unlabeled dataset during thesemi-supervised learning process.
本研究的目的是提出一个全面的半监督学习框架,该框架能够有效地利用未标注数据,并学习具有判别性的逐像素表示,尤其是在边缘区域。为了实现这一目标,我们引入了一种新颖的从弱到强的特征级扰动策略,同时结合了一致性损失和边缘感知对比损失。这些组成部分使模型能够在半监督学习过程中,从无标注数据集中充分利用语义信息。
Conclusion
结论
Deploying high-performance deep learning models for medical image segmentation, especially in edge regions, presents a formidablechallenge due to the requirement for a large number of annotations. Inthis study, we propose a semi-supervised approach that addresses thisissue by utilizing a substantial amount of unlabeled images alongsidea limited set of annotations. Initially, we introduce a weak-to-strongperturbation module that effectively exploits the semantic informationfrom the unlabeled data. To ensure learning from reliable regionsof multiple predictions, we further develop a feature-perturbed consistency loss with an uncertainty-weighted aggregation strategy thatautomatically filters out unreliable regions. Additionally, we definean edge-aware contrastive loss to guide our framework to learn morediscriminative representations in edge regions. By incorporating thiscontrastive loss, our framework achieves superior accuracy in identifying edge regions compared to other baseline methods on threedatasets. We extensively evaluate our approach on three open-sourcedatasets in both 2D and 3D, achieving the highest segmentation performance across various limited annotation scenarios. Furthermore, wedemonstrate the robustness of our method to hyperparameter settingsfrom different perspectives. However, our framework has the limitationthat the number of parameters of the model increases dramatically asthe number of decoders gradually increases. In the future, we aim tooptimize the negative sample selection strategy and apply our proposedmethod to a broader range of medical image segmentation tasks.
部署用于医学图像分割的高性能深度学习模型,尤其是在边缘区域,是一项艰巨的挑战,因为这需要大量的标注数据。在本研究中,我们提出了一种半监督方法来解决这一问题,该方法在利用有限标注数据的同时,还使用了大量的未标注图像。 首先,我们引入了一个从弱到强的扰动模块,该模块能有效地利用未标注数据中的语义信息。为了确保从多次预测的可靠区域中进行学习,我们进一步开发了一种特征扰动一致性损失函数,并结合了不确定性加权聚合策略,该策略可自动过滤掉不可靠的区域。此外,我们定义了一种边缘感知对比损失,以引导我们的框架在边缘区域学习更具判别性的表示。 通过引入这种对比损失,与其他基线方法相比,我们的框架在三个数据集上识别边缘区域时实现了更高的准确性。我们在三个二维和三维开源数据集上对我们的方法进行了广泛评估,在各种有限标注的场景下都取得了最高的分割性能。此外,我们还从不同角度证明了我们的方法对超参数设置的鲁棒性。 然而,我们的框架存在一个局限性,即随着解码器数量的逐渐增加,模型的参数数量会急剧增多。未来,我们的目标是优化负样本选择策略,并将我们提出的方法应用于更广泛的医学图像分割任务中。
Figure
图
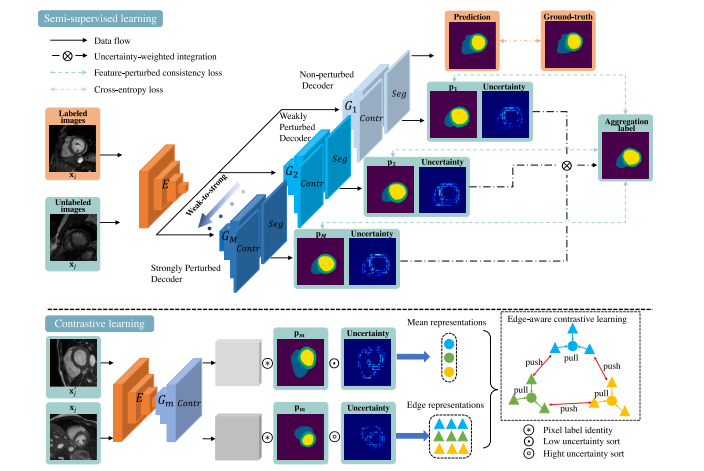
Fig. 1. Overview of our weak-to-strong perturbation and edge-aware semi-supervised segmentation framework, visualized with 2D inputs for improved clarity. In the semi-supervisedlearning branch (𝐸◦𝐺𝑚 with 𝑆𝑒𝑔 block), the labeled images 𝐱𝑖 are exclusively fed into the Non-perturbed decoder for better initialization of 𝐺1 . The unlabeled images 𝐱𝑗 areprocessed by weak-to-strong perturbed decoders, including the Non-perturbed decoder, to generate multi-predictions and the aggregation label. In the contrastive learning branch(𝐸◦𝐺𝑚 with 𝐶𝑜𝑛𝑡𝑟 block), predictions and uncertainty maps are employed to select discriminative features, facilitating better representation learning. Skip connection between eachstage of the encoder and the corresponding stage of each decoder is omitted for simplicity
图1:我们所提出的从弱到强扰动以及边缘感知半监督分割框架的概述,为了更清晰地展示,使用二维输入进行可视化。在半监督学习分支(带有“分割(𝑆𝑒𝑔)”模块的𝐸◦𝐺𝑚)中,带标注的图像𝐱*𝑖仅被输入到无扰动解码器中,以便对𝐺1进行更好的初始化。未标注的图像𝐱𝑗则由从弱到强的扰动解码器(包括无扰动解码器)进行处理,以生成多种预测结果和聚合标签。在对比学习分支(带有“对比(𝐶𝑜𝑛𝑡𝑟)”模块的𝐸◦𝐺𝑚)中,预测结果和不确定性图被用于选择具有判别性的特征,从而有助于更好地进行表示学习。为简化起见,编码器每个阶段与每个解码器相应阶段之间的跳跃连接被省略了。
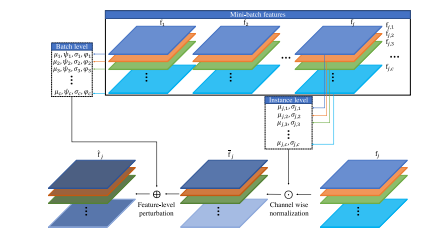
Fig. 2. The feature-level perturbation module incorporated in decoders. Means andstandard deviations at both the instance and batch levels are applied to each featuremap at convolutional layers for each image within a mini-batch.
图2:整合在解码器中的特征级扰动模块。对于小批量数据中的每一张图像,在卷积层上,实例层面和批量层面的均值与标准差会被应用于每一个特征图。
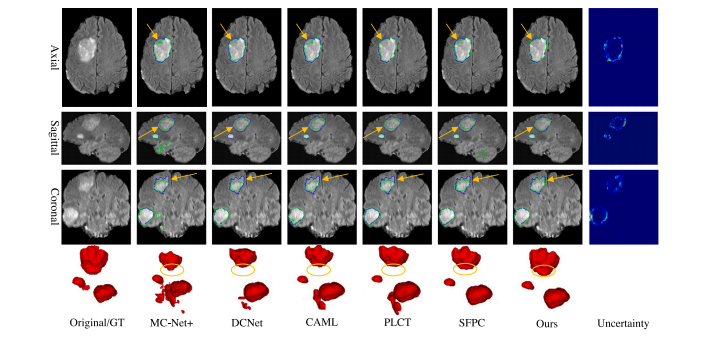
Fig. 3. Visual comparisons between the proposed method and strong baseline methods (second to sixth column) on one image from BraTS2020 dataset. During training, 5% ofthe training samples were annotated. Green and blue contours denote prediction and ground-truth edges, respectively. Fourth row (in red): view of the 3D segmentation lesions.Last column: pixel-wise uncertainty of the aggregation prediction using entropy
图3:在BraTS2020数据集中的一张图像上,我们所提出的方法与强基线方法(从第二列到第六列)之间的可视化比较。在训练过程中,仅对5%的训练样本进行了标注。绿色轮廓表示预测的边缘,蓝色轮廓表示真实的边缘。第四行(红色):三维分割病变的视图。最后一列:使用熵计算得到的聚合预测的逐像素不确定性。
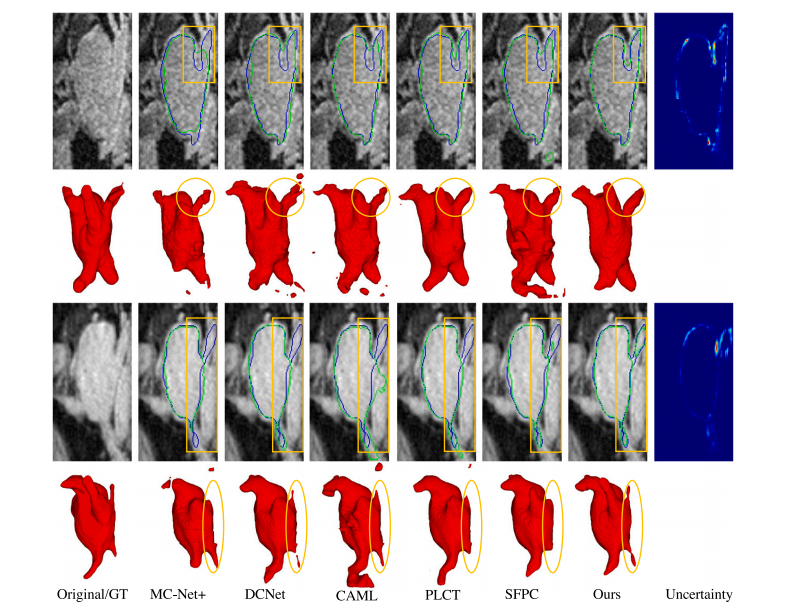
Fig. 4. Visual comparisons between the proposed method and strong baseline methods (second to sixth column) on two representative images from LA dataset. During training,5% of training samples were annotated. Green and blue contours denote prediction and ground-truth edges, respectively. Second and fourth row (in red): view of the segmentation3D organ. Last column: pixel-wise uncertainty of the aggregation prediction using entropy
图4:在LA数据集的两张具有代表性的图像上,所提出的方法与强基线方法(从第二列到第六列)之间的可视化比较。在训练期间,仅对5%的训练样本进行了标注。绿色轮廓表示预测的边缘,蓝色轮廓表示真实情况的边缘。第二行和第四行(以红色显示):分割后的三维器官视图。最后一列:使用熵计算得到的聚合预测的逐像素不确定性。
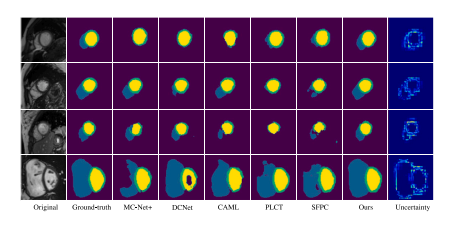
Fig. 5. Visual comparisons between the proposed method (last two columns) and strongbaselines (third to seventh column) on four representative images from 2017 ACDCdataset. 5% training samples were annotated for model training. Second to eighthcolumn: different colors indicate different types of segmented regions. Last column:pixel-wise uncertainty of the aggregation prediction using entropy
图5:在2017年ACDC数据集的四张具有代表性的图像上,所提出的方法(最后两列)与强基线方法(第三列至第七列)之间的可视化比较。为进行模型训练,仅对5%的训练样本进行了标注。第二列至第八列:不同颜色表示不同类型的分割区域。最后一列:使用熵计算得到的聚合预测的逐像素不确定性。
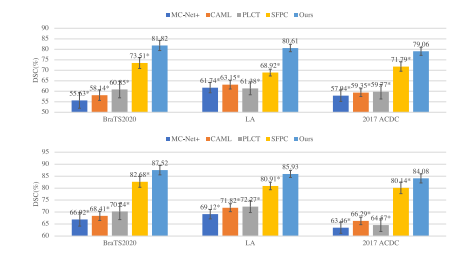
Fig. 6. Performance on edge regions from our method and strong baselines onBraTS2020, LA 2017 ACDC datasets, with 5% (upper) and 10% (lower) labeled imagesused for training. ∗ means our method is significantly better than the compared methodwith 𝑝 < 0.05 via paired t-test
图6:在BraTS2020、LA以及2017 ACDC数据集上,我们的方法和强基线方法在边缘区域的性能表现,其中用于训练的标注图像比例分别为5%(上半部分)和10%(下半部分)。“∗”表示通过配对t检验,我们的方法显著优于对比方法,且𝑝 < 0.05 。
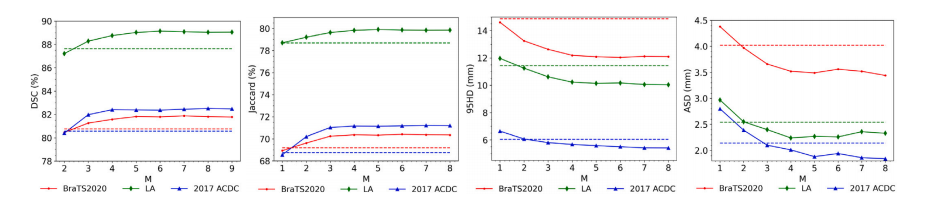
Fig. 7. Performance of our method on BraTS2020, LA and 2017 ACDC datasets with different decoder number of 𝑀, where 5% labeled images were used for model training.Dashed lines represent the performance of the strongest baselines
图7:在BraTS2020、LA以及2017 ACDC数据集上,我们的方法在不同解码器数量𝑀 情况下的性能表现,其中用于模型训练的标注图像比例为5%。虚线表示最强基线方法的性能。
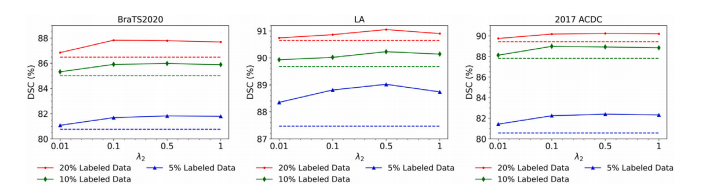
Fig. 8. Performance of our method on the BraTS2020, LA and 2017 ACDC datasets with different contrastive loss weights 𝜆2 , where 5%, 10% and 20% labeled images were usedfor model training, respectively. Dashed lines represent the performance of the strongest baselines.
图8:在BraTS2020、LA以及2017 ACDC数据集上,当使用不同的对比损失权重λ₂ 时,我们的方法的性能表现,其中分别使用了5%、10%和20%的标注图像用于模型训练。虚线表示最强基线方法的性能。
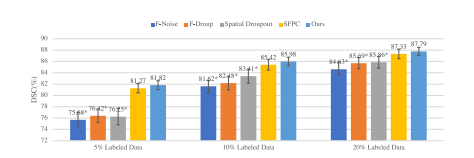
Fig. 9. Segmentation performance with different perturbation strategies on theBraTS2020 dataset, where 5%, 10% and 20% labeled images were used for modeltraining, respectively. ∗ means our method is significantly better than the comparedmethod with 𝑝 < 0.05 via paired t-test
图9:在BraTS2020数据集上,采用不同扰动策略时的分割性能表现,其中分别使用了5%、10%和20%的标注图像用于模型训练。“∗”表示通过配对t检验,我们的方法显著优于对比方法,且𝑝 < 0.05 。
Table
表
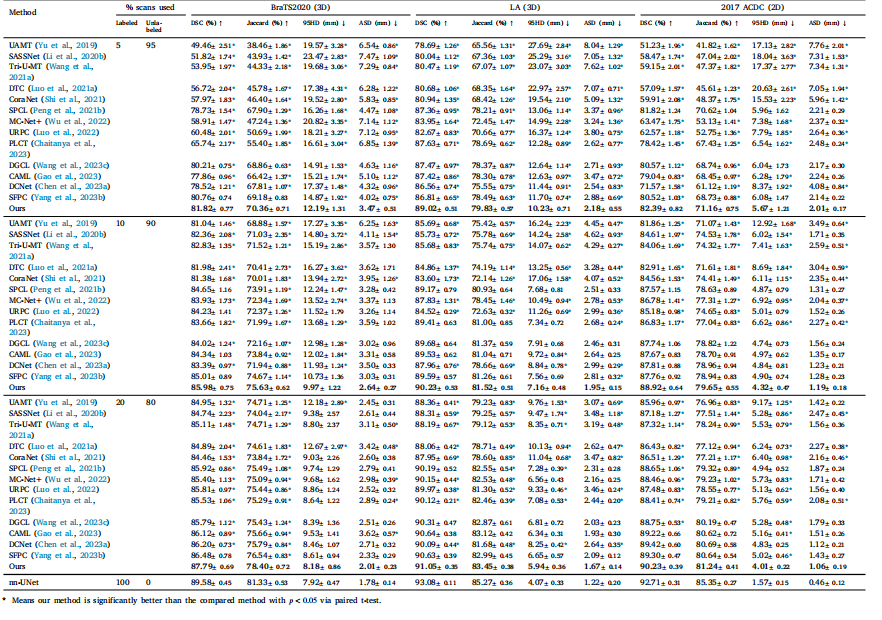
Table 1Quantitative comparisons with other state-of-the-art methods on the BraTS2020, LA and 2017 ACDC datasets. ↑ indicates that larger values are better and ↓ indicates that smaller values are better
表1 在BraTS2020、LA以及2017年ACDC数据集上,与其他最先进方法的定量比较。“↑”表示数值越大越好,“↓”表示数值越小越好
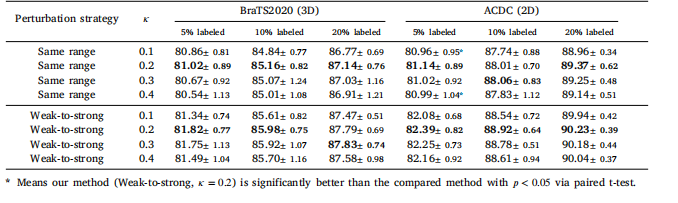
Table 2Effects analysis of the weak-to-strong perturbation strategy on the BraTS2020 and 2017 ACDC datasets with 5%, 10% and 20%labeled images for training. DSC is used as the evaluation metric to assess the performance
表2:在BraTS2020和2017 ACDC数据集上,针对从弱到强扰动策略的效果分析,分别使用5%、10%和20%的标注图像用于训练。使用Dice相似系数(DSC)作为评估指标来衡量性能表现。
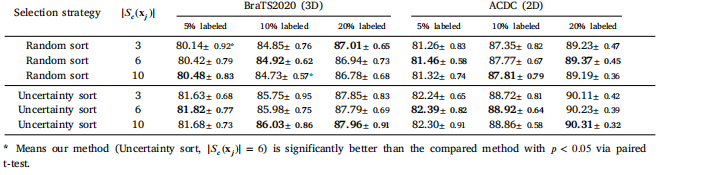
Table 3Effects analysis of the contrastive pixel selection strategy on the BraTS2020 and 2017 ACDC datasets with 5%, 10% and 20% labeledimages for training. DSC is used as the evaluation metric to assess the performance.
表3:在BraTS2020和2017 ACDC数据集上,对于对比像素选择策略的效果分析,分别使用5%、10%和20%的标注图像用于训练。使用Dice相似系数(DSC)作为评估指标来衡量性能表现。
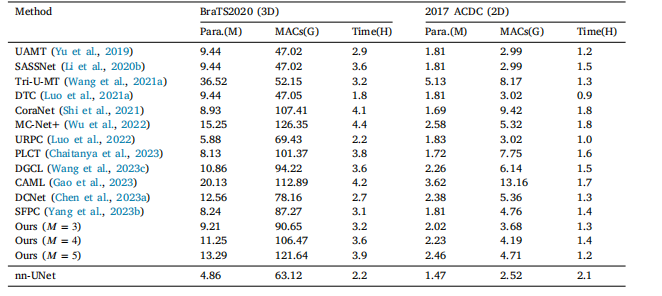
Table 4Quantitative comparisons with other state-of-the-art methods in computational complexity. 𝑀 denotes the number of decodersin our method.
表4:与其他最先进的方法在计算复杂度方面的定量比较。“𝑀”表示我们方法中解码器的数量。

Table 5Effects analysis of our proposed ensemble strategies on the BraTS2020 and 2017 ACDC datasets, where 5% and 10% labeled images were used for model training. WSP, ECL andFPC+ denote the Weak-to-Strong Perturbation, Edge-aware Contrastive Loss and Feature-Perturbed Consistency with uncertaintyweighted aggregation, respectively
表5:在BraTS2020和2017 ACDC数据集上,对我们所提出的集成策略的效果分析,其中分别使用了5%和10%的标注图像用于模型训练。WSP、ECL和FPC+分别表示从弱到强扰动、边缘感知对比损失以及带有不确定性加权聚合的特征扰动一致性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









