







 本文介绍了如何爬取10个类别假新闻的数据,进行数据预处理,包括文件合并和分词去停,然后利用gensim的word2vec工具训练模型,并展示了测试效果。
本文介绍了如何爬取10个类别假新闻的数据,进行数据预处理,包括文件合并和分词去停,然后利用gensim的word2vec工具训练模型,并展示了测试效果。
爬取语料库
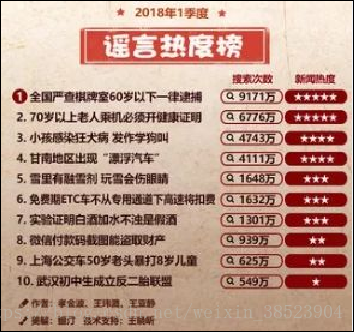
利用爬虫爬取百度网页每个类别假新闻10页,共1000篇文章。爬取的类别如下:
数据预处理
汇总
把爬取到的10个txt文件都放在同一个文件夹下,利用程序将这10个txt文件合并在一起。
把汇总的txt文件命名为result.txt。
程序如下:
file: FileMerage.py
# os模块中包含很多操作文件和目录的函数
import os
# 获取目标文件夹的路径
meragefiledir = os.getcwd() + '\\MerageFiles'
# 获取当前文件夹中的文件名称列表
filenames = os.listdir(meragefiledir)
# 打开当前目录下的result.txt文件,如果没有则创建
file = open('result.txt', 'w')
# 先遍历文件名
for filename in filenames:
filepath = meragefiledir + '\\' + filename
&nb
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4964
4964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









