






量化覆盖
如果在模型转换过程中的选项 --quantization_overrides 被提供,用户可以提供一个 JSON 文件,其中包含用于量化的参数。这些参数将与模型一起缓存,并可以用于覆盖从转换中携带的任何量化数据(例如 TF 假量化)或在 snpe-dlc-quantize 的正常量化过程中计算的量化数据。要在 snpe-dlc-quantize 中覆盖参数,必须传递选项 --override_params,将使用缓存的值。JSON 格式按照 AIMET 规格定义,具体如下。
JSON 中有两个部分,一个是用于覆盖操作输出编码的“activation_encodings”部分,另一个是用于覆盖参数(权重和偏置)编码的“param_encodings”部分。两者必须都存在于文件中,但如果不需要覆盖,可以留空。
目前支持的选项示例:
{
"activation_encodings": {
"Conv1:0": [
{
"bitwidth": 8,
"max": 12.82344407824954,
"min": 0.0,
"offset": 0,
"scale": 0.050288015993135454
}
],
"input:0": [
{
"bitwidth": 8,
"max": 0.9960872825108046,
"min": -1.0039304197656937,
"offset": 127,
"scale": 0.007843206675594112
}
]
},
"param_encodings": {
"Conv2d/weights": [
{
"bitwidth": 8,
"max": 1.700559472933134,
"min": -2.1006477158567995,
"offset": 140,
"scale": 0.01490669485799974
}
]
}
}
在“activation_encodings”下,名称(例如“Conv1:0”)代表输出张量的名称,量化应在此处被覆盖。在“param_encodings”下,名称代表权重或偏置,将为其指定编码。以下是常见参数的简要说明:
- bitwidth (int, required) - 用于量化的位宽。请注意,这必须与模型将运行的运行时所支持的现有位宽匹配。
- max (float, required) - 分布或期望范围内的最大值。
- min (float, required) - 分布或期望范围内的最小值。
- offset (int) - 表示零点的整数偏移量(即0被精确表示的点)。
- scale (float) - 表示整数大小除以期望分布范围的值。
请注意,虽然不必提供scale(也称为delta)和offset(零点),但必须提供bitwidth、min和max。无论是否提供,scale和offset将根据提供的bitwidth、min和max参数进行计算。
注意:激活的量化位宽为16,仅在某些运行时的Snapdragon 865/765及之后的版本上支持,目前并非所有操作均启用。
Float16(半精度)还允许将整个模型转换为FP16,或在混合精度图中选择FP16和FP32数据类型,以便在浮点和整数操作之间混合。混合精度的不同使用模式如下所述。
- 无覆盖:如果没有使用编码文件提供–quantization_overrides标志,则所有激活按照–act_bitwidth(默认8)进行量化,参数则按–weight_bitwidth/–bias_bitwidth(默认8/8)进行量化。
- 完全覆盖:如果提供了–quantization_overrides标志和编码文件,指定模型中所有操作的编码。在这种情况下,所有操作的位宽将根据JSON文件设置,定义为整数/浮点(在编码文件中dtype=’int’或dtype=’float’)。
- 部分覆盖:如果提供了–quantization_overrides标志和编码文件,指定了部分编码(即某些操作缺少编码),则会发生以下情况:
- 在json文件中未提供编码的层将以与无覆盖情况相同的方式编码,即定义为整数,位宽根据–act_bitwidth/–weight_bitwidth/–bias_bitwidth(或其默认值8/8/8)进行定义。对于某些操作(Conv2d、Conv3d、TransposeConv2d、DepthwiseConv2d、FullyConnected、MatMul),即使在编码文件中将任何输出/权重/偏置指定为浮点,所有三者也将被覆盖为浮点。使用的浮点位宽将与编码文件中覆盖张量的浮点位宽相同。如果在编码json中缺少偏置张量的编码而输出/权重的编码存在,则我们还可以使用–float_bias_bitwidth(16/32)标志手动控制偏置张量的位宽。
- 在json中可用的编码的层将以与完全覆盖情况相同的方式编码。
我们展示一个包含3个Conv2d操作的网络示例json。第一个和第三个Conv2d操作为INT8,而第二个Conv2d操作标记为FP32。FP32操作(即conv2_1)位于两个INT8操作之间,因此将在FP32操作之前和之后插入转换操作。conv2_1的相应权重和偏置在“param_encodings”的JSON中也标记为浮点。
{
"activation_encodings": {
"data_0": [
{
"bitwidth": 8,
"dtype": "int"
}
],
"conv1_1": [
{
"bitwidth": 8,
"dtype": "int"
}
],
"conv2_1": [
{
"bitwidth": 32,
"dtype": "float"
}
],
"conv3_1": [
{
"bitwidth": 8,
"dtype": "int"
}
]
},
"param_encodings": {
"conv1_w_0": [
{
"bitwidth": 8,
"dtype": "int"
}
],
"conv1_b_0": [
{
"bitwidth": 8,
"dtype": "int"
}
],
"conv2_w_0": [
{
"bitwidth": 32,
"dtype": "float"
}
],
"conv2_b_0": [
{
"bitwidth": 32,
"dtype": "float"
}
],
"conv3_w_0": [
{
"bitwidth": 8,
"dtype": "int"
}
],
"conv3_b_0": [
{
"bitwidth": 8,
"dtype": "int"
}
]
}
}
在json中不存在的操作将被视为定点,位宽将分别根据–act_bitwidth/–weight_bitwidth/–bias_bitwidth进行选择。
{
"activation_encodings": {
"conv2_1": [
{
"bitwidth": 32,
"dtype": "float"
}
]
},
"param_encodings": {
"conv2_w_0": [
{
"bitwidth": 32,
"dtype": "float"
}
],
"conv2_b_0": [
{
"bitwidth": 32,
"dtype": "float"
}
]
}
}
根据上面显示的JSON,将生成以下量化混合精度图。请注意,转换操作已适当添加,以在浮点和整数类型之间进行转换,反之亦然。
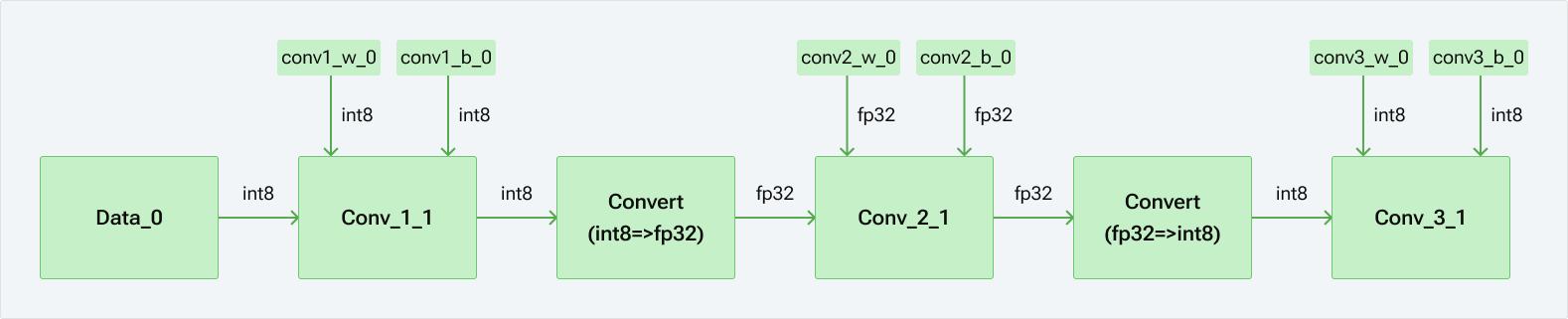
每通道量化覆盖
每通道量化应用于Conv消费者(Conv2d、Conv3d、TransposeConv2d、DepthwiseConv2d)的权重输入张量。本节提供示例以手动覆盖这些基于Conv操作的权重张量的每通道编码。每通道量化将在我们为给定张量提供多个编码(等于通道数量)时使用。我们看到以下情况的卷积权重示例。
-
案例1:没有每通道量化的非对称编码
{ "features.9.conv.3.weight": [ { "bitwidth": 8, "is_symmetric": "False", "max": 3.0387749017453665, "min": -2.059169834735364, "offset": -103, "scale": 0.019991940143061618 } ] } -
案例2:具有3个输出通道的每通道量化编码
{ "features.8.conv.3.weight": [ { "bitwidth": 8, "is_symmetric": "True", "max": 0.7011175155639648, "min": -0.7066381259227362, "offset": -128.0, "scale": 0.005520610358771377 }, { "bitwidth": 8, "is_symmetric": "True", "max": 0.5228064656257629, "min": -0.5269230519692729, "offset": -128.0, "scale": 0.004116586343509945 }, { "bitwidth": 8, "is_symmetric": "True", "max": 0.7368279099464417, "min": -0.7426297045129491, "offset": -128.0, "scale": 0.005801794566507415 } ] }
注意:每通道量化必须使用对称表示,offset == -2^(bitwidth-1)。每通道始终具有is_symmetric = True。
INT32覆盖
INT32覆盖也可以提供,以将操作覆盖为运行在INT32精度下。为了支持以INT32精度运行操作,应该为其所有输入和输出提供INT32覆盖。这将会在操作的输入处插入一个Dequantize操作,后跟一个Cast(到:INT32)操作,并在操作的输出处插入一个Cast(到:FP32)操作,后接一个Quantize操作,以适应量化模型。我们在下面展示一个示例图,其中“Op2”通过使用外部覆盖将其输入和输出张量覆盖为INT32。这反过来会生成第二个图以支持通过使用Dequantize、Cast(到:INT32)、Cast(到:FP32)和Quantize操作的INT32覆盖。
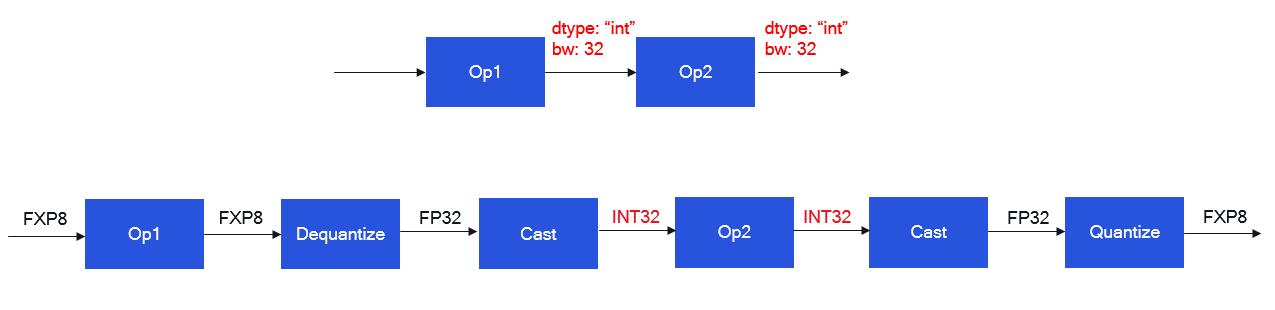
注意:仅支持没有权重和偏置的操作的INT32覆盖。

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









