







 本文通过Python机器学习库sklearn实现DBSCAN聚类算法,对网络使用数据进行聚类分析,详细展示了数据预处理、模型训练、结果评估及可视化过程。
本文通过Python机器学习库sklearn实现DBSCAN聚类算法,对网络使用数据进行聚类分析,详细展示了数据预处理、模型训练、结果评估及可视化过程。
**
基于《Python机器学习》——北京理工大学 学习笔记
import numpy as np #引入相关工程包
import sklearn.cluster as skc
from sklearn import metrics
import matplotlib.pyplot as plt
mac2id=dict()
onlinetimes=[]
f=open('TestData.txt',encoding='utf-8') #加载数据
for line in f:
mac=line.split(',')[2]
onlinetime=int(line.split(',')[6])
starttime=int(line.split(',')[4].split(' ')[1].split(':')[0]) #读取每条数据的MAC地址,开始上网时间,上网时长
if mac not in mac2id:
mac2id[mac]=len(onlinetimes)
onlinetimes.append((starttime,onlinetime))
else:
onlinetimes[mac2id[mac]]=[(starttime,onlinetime)]
real_X=np.array(onlinetimes).reshape((-1,2)) #形成一个二维矩阵
X=real_X[:,0:1] #提取每行第一列元素
db=skc.DBSCAN(eps=0.01,min_samples=20).fit(X) #调用DBSCAN进行训练,labels为每个簇的标签
labels = db.labels_
print('Labels:') #打印数据被记上的标签,噪声数据的标签为-1
print(labels)
raito=len(labels[labels[:] == -1]) / len(labels) #计算标签为-1的比例,即噪声数据比例
print('Noise raito:',format(raito, '.2%'))
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) #簇的个数
print('Estimated number of clusters: %d' % n_clusters_)
print("Silhouette Coefficient: %0.3f"% metrics.silhouette_score(X, labels)) # 打印聚类效果
for i in range(n_clusters_): #打印簇类标号以及各簇数据
print('Cluster ',i,':')
print(list(X[labels == i].flatten()))
plt.hist(X,24)
plt.show()
个别函数用法说明:
- flatten( ) :flatten是numpy.ndarray.flatten的一个函数,即返回一个一维数组。flatten只能适用于numpy对象,即array或者mat,普通的list列表不适用。例如:
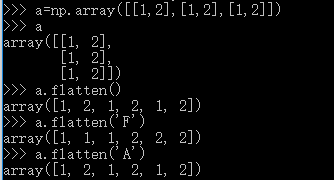
a.flatten():按默认方向降维
a.flatten(‘F’):按列方向降维
a.flatten(‘A’):按行方向降维
https://www.jb51.net/article/150035.htm
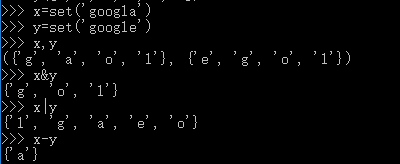
- set():set函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。例如:
个别参数说明
1.eps:两个样本被看作邻居节点的最大距离
2.min_sample:簇的样本数
3.metrics:距离计算方式(默认欧几里得距离)
4.轮廓系数(Silhouette Coefficient)的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优

















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









