







文章目录
6.1什么是支持向量机
一个二分类模型,寻找决策边界最宽的一个超平面将数据进行分割
解决问题的步骤:
*把所有样本和其对应的分类标记交给算法进行训练
*如果发现线性可分,那么直接找出超平面
*如果发现线性不可分,那么先进行映射到高维(接近无限高)再找超平面 事实上并没有映射只是将其计算结果映射到相应维度(因为得出的值是相同的)
*最后得到的超平面就是分类函数的表达式
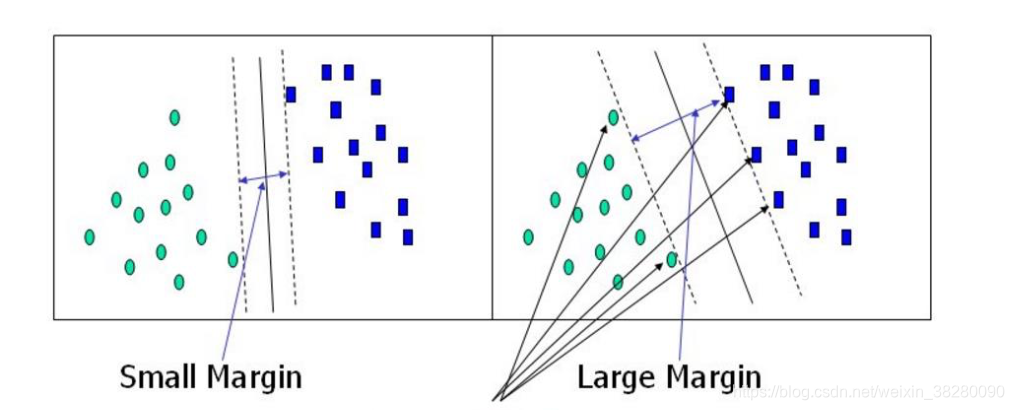
显然第二个比第一个好一些
6.2 推导过程
6.2.1距离和目标函数
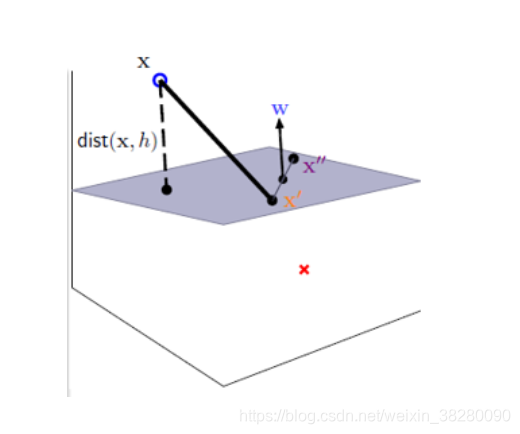
距离
有这样一个平面,如何求点X到该平面的距离呢?
求点到平面的距离,只要求点到点在方向量上的映射即可
设平面 w T X + b = 0 w^{T}X+b=0 wTX+b=0上有点X’ X’’ 可以求出向量
X ′ X ′ ′ ⃗ = ( X ′ ′ − X ′ ) \vec{{X'X''}}=(X''-X') X′X′′=(X′′−X′)
w T X ′ = − b , w T X ′ ′ = − b w^{T}X' = -b,w^{T}X'' = -b wTX′=−b,wTX′′=−b
则可以求出平面法向量 W T W^{T} WT
( w T ( x ′ ′ − x ′ ) ) = 0 \left(w^{T}(x''-x') \right)=0 (wT(x′′−x′))=0
距离表达式如下:
d = ∣ w T ∣ w ∣ ( X − X ′ ) ∣ = 1 ∣ w ∣ ∣ w T x + b ∣ d=\left|\frac {w^{T}}{|w|}(X-X') \right|=\frac {1}{|w|}|w^{T}x+b| d=∣∣∣∣∣w∣wT(X−X′)∣∣∣∣=∣w∣1∣wTx+b∣
目标
有这样的数据集:(X1,Y1)(X2,Y2)… (Xn,Yn)
Y为样本类别:
当X为正时 Y=+1
当Y为负时 Y=-1
决策方程为 y ( x ) = w T Φ ( x i ) + b y_(x)=w^{T}\Phi(x_i)+b y(x)=wTΦ(xi)+by ( x i ) > 0 < = > y i = + 1 y_{(x_i)>0} <=>y_{i}=+1 y(xi)>0<=>yi=+1
y ( x i ) < 0 < = > y i = − 1 y_{(x_i)<0} <=>y_{i}=-1 y(xi)<0<=>yi=−1
推出 y i ∗ y ( x i ) > 0 y_{i}*y_(x_i)>0 yi∗y(xi)>0
优化目标
通俗的讲:找到一个条件(w和b),使得离该平面最近的点最远
点到直线的距离简化为:
y i ∗ ( w T Φ ( x i ) + b ) ∣ ∣ W ∣ ∣ \frac{y_{i}*(w^{T}\Phi(x_i)+b)}{||W||} ∣∣W∣∣yi∗(wTΦ(xi)+b)
则目标为
m a x { 1 ∣ ∣ W ∣ ∣ m i n { y i ∗ ( w T Φ ( x i ) + b ) } } max\lbrace\frac{1}{||W||}min\lbrace{y_{i}*(w^{T}\Phi(x_i)+b)}\rbrace\rbrace max{∣∣W∣∣1min{yi∗(wTΦ(xi)+b)}}
将 y ( i ) ∗ y ( x i ) > 0 y_{(i)}*y_{(x_i)}>0 y(i)∗y(xi)>0放缩变换得到:
y ( i ) ∗ y ( x i ) ≥ 1 y_{(i)}*y_{(x_i)}≥1 y(i)∗y(xi)≥1
y i ∗ ( w T Φ ( x i ) + b ) ≥ 1 y_{i}*(w^{T}\Phi(x_i)+b)≥1 yi∗(wTΦ(xi)+b)≥1
那么 y i ∗ ( w T Φ ( x i ) + b ) y_{i}*(w^{T}\Phi(x_i)+b) yi∗(wTΦ(xi)+b)的最小值为1
只需要考虑
m a x 1 ∣ ∣ W ∣ ∣ max\frac{1}{||W||} max∣∣W∣∣1
约束条件
y i ∗ ( w T Φ ( x i ) + b ) ≥ 1 y_{i}*(w^{T}\Phi(x_i)+b)≥1 yi∗(wTΦ(xi)+b)≥1
然后将求极大值问题转化为求极小值问题
m i n w , b 1 2 w 2 min_{w,b}\frac{1}{2}w^2 minw,b21w2
然后使用拉格朗日乘子法求解
6.2.2使用拉格朗日乘子法解SVM
先转化
带约束的优化问题:
m i n x f 0 ( x ) min_{x} f_{0}(x) minxf0(x)
约束为
f i ( x ) ≤ 0 , i = 1 , . . . m f_i(x)≤0,i=1,...m fi(x)≤0,i=1,...m
h i ( x ) ≤ 0 , i = 1 , . . . q h_i(x)≤0,i=1,...q hi(x)≤0,i=1,...q
原式转化为:
m i n L ( x , λ , v ) = f ( x ) + ∑ i = 1 m λ i f i ( x ) + ∑ i = 1 q v i h i ( x ) min L_{(x,λ,v)}=f_{(x)}+\sum_{i=1}^{m}λ_{i}f_{i}(x)+\sum_{i=1}^{q}v_{i}h_{i}(x) minL(x,λ,v)=f(x)+i=1∑mλifi(x)+i=1∑qvihi(x)
套下这个式子那么咱们的式子为:
L ( w , b , a ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 n α i ( y i ( w T ∗ Φ ( x i ) + b ) − 1 ) L(w,b,a)=\frac{1}{2}||w||^2-\sum_{i=1}^{n}α_i(y_i(w^T*Φ_{(x_i)+b})-1) L(w,b,a)=21∣∣w∣∣2−i=1∑nαi(yi(wT∗Φ(xi)+b)−1)
约束条件 y i ∗ ( w T Φ ( x i ) + b ) ≥ 1 y_{i}*(w^{T}\Phi(x_i)+b)≥1 yi∗(wTΦ(xi)+b)≥1
SVM求解
分别对w和b求偏导,分别得到两个条件(基于对偶性质)
m i n w , b m a x a L ( w , b , a ) = m a x a m i n w , b L ( w , b , a ) min_{w,b}max_{a}L_{(w,b,a)}=max_{a}min_{w,b}L_{(w,b,a)} minw,bmaxaL(w,b,a)=maxaminw,bL(w,b,a)
对w求偏导:
δ L δ W = 0 = > w = ∑ i = 1 n α i y i Φ ( x n ) \frac{δL}{δW}=0 => w=\sum_{i=1}^{n}α_iy_iΦ_{(x_n)} δWδL=0=>w=i=1∑nαiyiΦ(xn)
对b求偏导: \frac{δL}{δW}=0 =>0=\sum_{i=1}^{n}α_iy_iKaTeX parse error: Can't use function '$' in math mode at position 9: 带入原始公式:$̲L(w,b,a)=\frac{…\frac{1}{2}*w{T}*w-wT\sum_{i=1}{n}α_iy_iΦ_{(x_i)}-b\sum_{i=1}{n}α_iy_i+\sum_{i=1}^{n}α_iKaTeX parse error: Can't use function '$' in math mode at position 2: $̲=\sum_{i=1}{n}α…min_α \frac{1}{2}\sum_{i=1}{n}\sum_{j=1}{n}α_iα_jy_iy_jΦ_(x_i)Φ_(y_i)-\sum_{i=1}^{n}Φ_i$$
条件:
∑ i = 1 n α i y i = 0 \sum_{i=1}^{n}α_iy_i=0 ∑i=1nαiyi=0
α i ≥ 0 α_i≥0 αi≥0
6.2.3 SVM求解实例
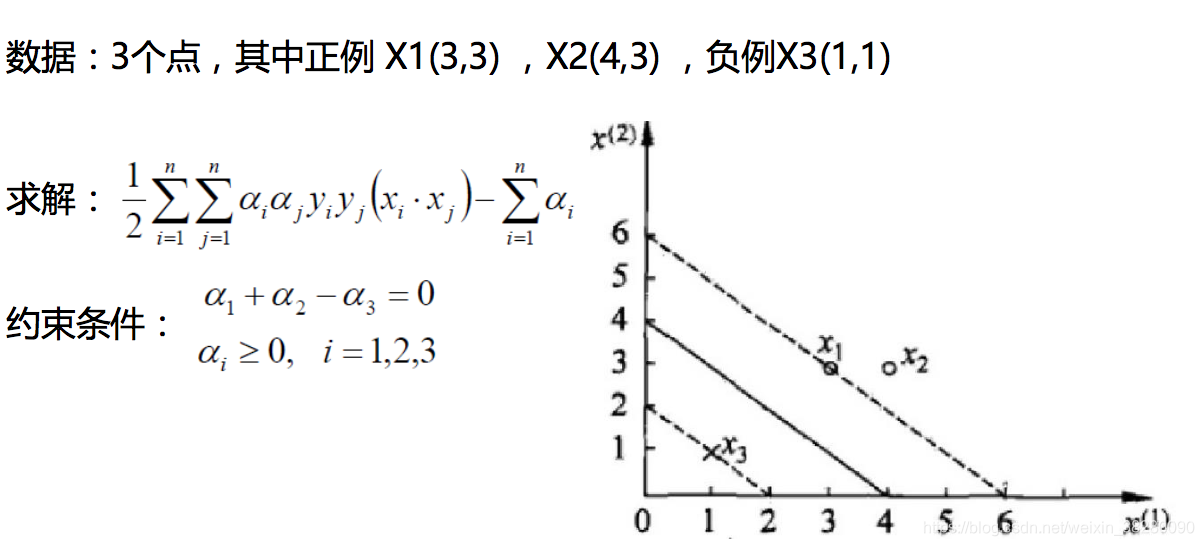


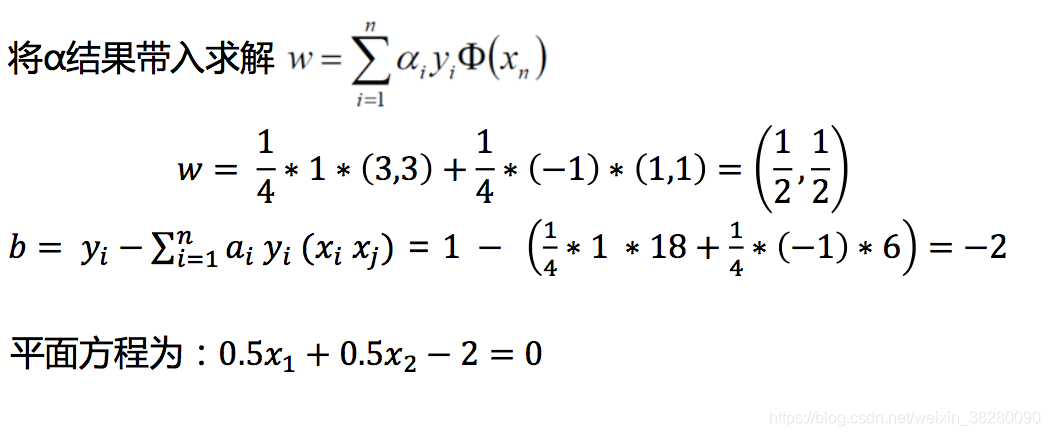
6.3 软间隔
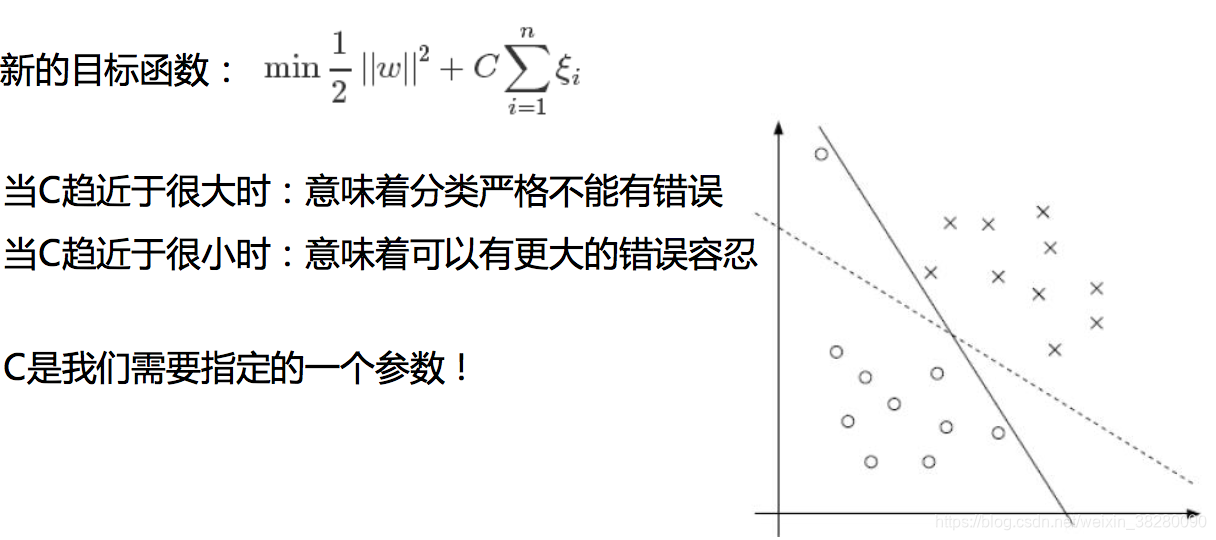
要使整体很小当C大时
ξ
i
ξ_i
ξi就越小,则意味着不能容忍错误

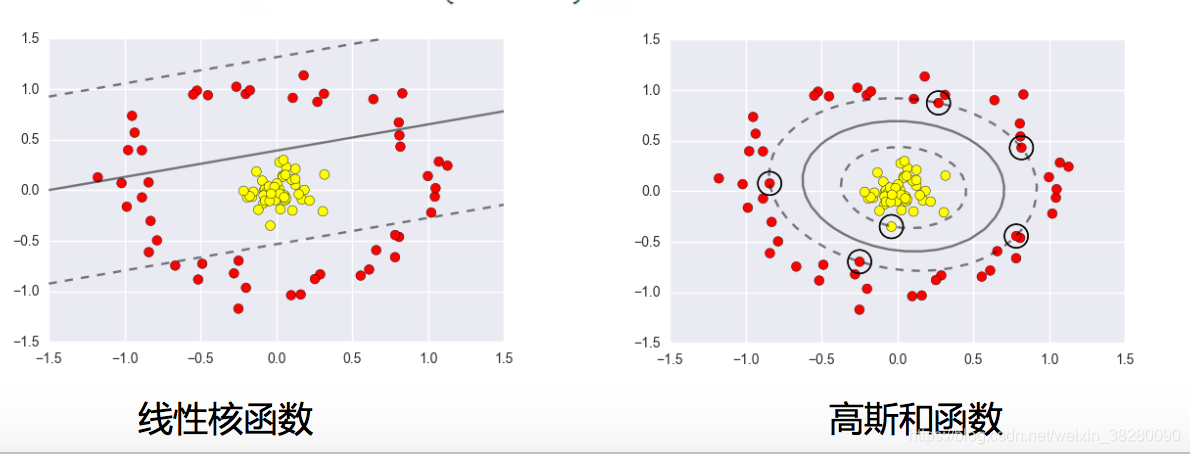
6.4 低维不可分或者难分解时
需要映射到高维实际上并没有映射到高维,还是在低维计算将结果映射到高维
例如

6.7 高斯核函数
可以认为转化到一个无穷高的维度
k
(
x
,
y
)
=
e
x
p
−
∣
∣
x
−
y
∣
∣
2
2
σ
2
k_{(x,y)}=exp{-\frac{||x-y||^2}{2σ^2}}
k(x,y)=exp−2σ2∣∣x−y∣∣2

















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









