







 本文详细介绍了Flink中的StateBackends,包括keyed和非keyed状态管理,RocksDB和Heap状态存储的优缺点,以及Checkpoint机制。重点讨论了不同版本的Flink中StateBackend与CheckpointStorage的关系,以及如何配置和启用检查点功能。
本文详细介绍了Flink中的StateBackends,包括keyed和非keyed状态管理,RocksDB和Heap状态存储的优缺点,以及Checkpoint机制。重点讨论了不同版本的Flink中StateBackend与CheckpointStorage的关系,以及如何配置和启用检查点功能。
State Backends
由 Flink 管理的 keyed state 是一种分片的键/值存储,每个 keyed state 的工作副本都保存在负责该键的 taskmanager 本地中。另外,Operator state 也保存在机器节点本地。Flink 定期获取所有状态的快照,并将这些快照复制到持久化的位置,例如分布式文件系统。
如果发生故障,Flink 可以恢复应用程序的完整状态并继续处理,就如同没有出现过异常。
Flink 管理的状态存储在 state backend 中。Flink 有两种 state backend 的实现:
- 一种基于 RocksDB 内嵌 key/value 存储将其工作状态保存在磁盘上的,将其状态快照持久化到(分布式)文件系统;
- 另一种基于堆的 state backend,将其工作状态保存在 Java 的堆内存中。这种基于堆的 state backend 有两种类型:
- FsStateBackend,将其状态快照持久化到(分布式)文件系统;
- MemoryStateBackend,它使用 JobManager 的堆保存状态快照。
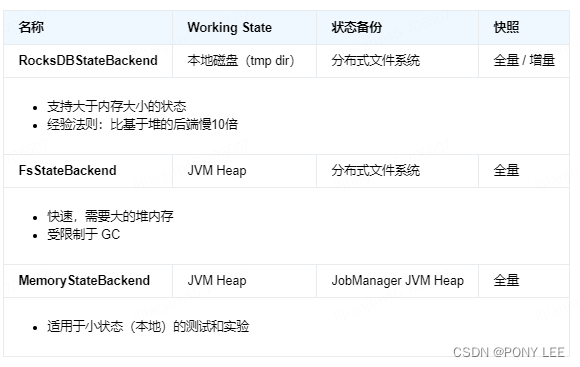
当使用基于堆的 state backend 保存状态时,访问和更新涉及在堆上读写对象。但是对于保存在 RocksDBStateBackend 中的对象,访问和更新涉及序列化和反序列化,所以会有更大的开销。但 RocksDB 的状态量仅受本地磁盘大小的限制。还要注意,只有 RocksDBStateBackend 能够进行增量快照,这对于具有大量变化缓慢状态的应用程序来说是大有裨益的。
所有这些 state backends 都能够异步执行快照,这意味着它们可以在不妨碍正在进行的流处理的情况下执行快照。
Checkpoint
Flink 定期对每个算子的所有状态进行持久化快照,并将这些快照复制到更持久的地方,例如分布式文件系统。 如果发生故障,Flink 可以恢复应用程序的完整状态并恢复处理,就好像没有出现任何问题一样。
这些快照的存储位置是通过作业_checkpoint storage_定义的。 有两种可用检查点存储实现:一种持久保存其状态快照 到一个分布式文件系统,另一种是使用 JobManager 的堆。

Flink不同版本StateBackend(状态)与Checkpoint Storage(快照) 关系
在Flink1.14之前StateBackend与Checkpoint Storage 耦合在一起,但在Flink1.14之后把StateBackend与Checkpoint Storage 实现了解耦,使逻辑更加清晰。
Flink1.14之前
- 基于 RocksDB state backend,状态快照持久化到(分布式)文件系统;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:8020/data/rocksdb/ck", true));//true: 增量checkpoint; false:全量checkpoint
env.setStateBack 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









