







HubServing则提供了模型的部署和在线预测服务。
环境准备:https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7/deploy/hubserving
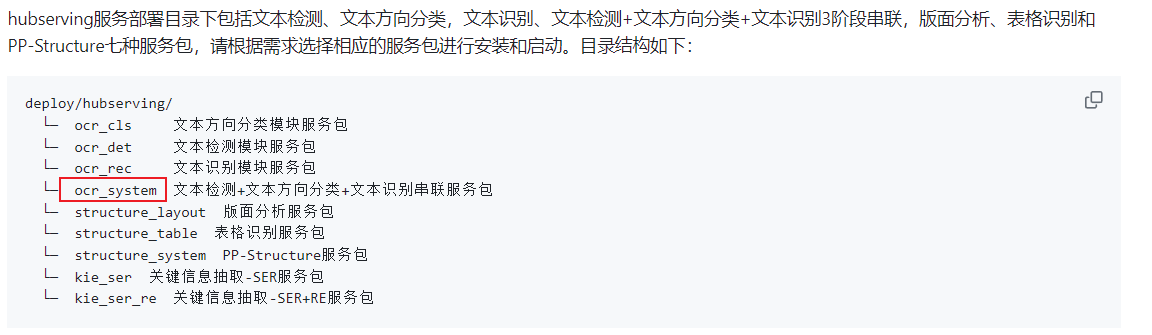
服务器启动命令
hub serving start -c deploy/hubserving/ocr_system/config.json
gpu与多线程不能同时开启
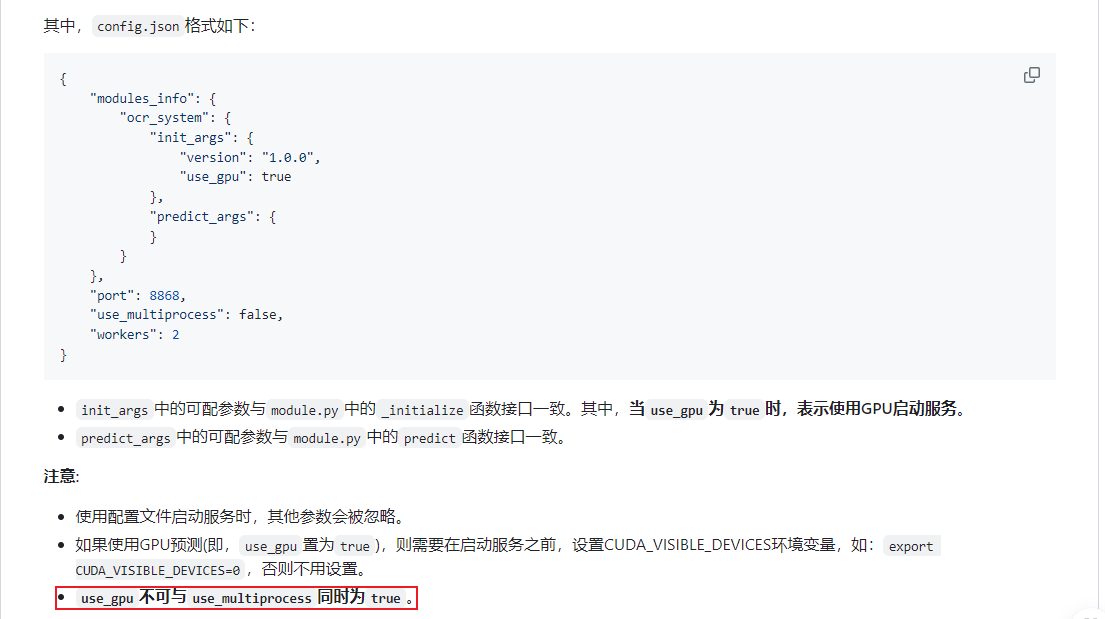
启动:

客户端请求
python tools/test_hubserving.py --server_url=server_url --image_dir=image_path
python tools/test_hubserving.py --server_url=http://127.0.0.1:8868/predict/ocr_system --image_dir=./doc/imgs/ --visualize=false
主程序代码
import base64
import sys
import time
import requests
import json
import asyncio
import aiohttp
import pandas as pd
from sqlalchemy import create_engine, text
import time
from PIL import Image
from io import BytesIO
import cv2
import numpy as np
import io
time1 = time.time()
def cv2_to_base64(image):
return base64.b64encode(image).decode('utf8')
def save_data(results, file_name):
df = pd.DataFrame([[i['text'] for i in x] for x in results])
df.to_csv(file_name, index=False)
def process_image_(img_str):
binary = base64.b64decode(img_str)
image = Image.open(BytesIO(binary))
# 创建一个新的RGB图像,将Alpha通道设置为0
rgb_image = Image.new('RGB', image.size, (255, 255, 255))
# 将RGBA图像的颜色信息复制到RGB图像
rgb_image.paste(image, (0, 0), mask=image)
# 裁剪图片
left = 535
top = 0
right = left + 240
bottom = image.size[1]
cropped_image = rgb_image.crop((left, top, right, bottom))
# 创建一个BytesIO对象
image_bytes = io.BytesIO()
# 将图像保存到BytesIO对象中
cropped_image.save(image_bytes, format='JPEG')
return image_bytes
def main():
results = []
img_strs_list = []#图像bas64_str的列表
for i, img_str in enumerate(img_strs_list):
image_bytes = process_image_(img_str)
data = {'images': [cv2_to_base64(image_bytes.getvalue())]}
headers = {
'Content-Type': 'application/json'
}
response = requests.post("http://192.168.0.189:8868/predict/ocr_system", data=json.dumps(data), headers=headers)
if response.status_code == 200:
res = response.json()["results"][0]
results.append(res)
else:
print('Error:', response.status_code)
save_data(results, 'normal.csv')
async def process_image(img_str):
image_bytes = process_image_(img_str)
headers = {
'Content-Type': 'application/json'
}
# 发送 OCR 请求
data = {'images': [cv2_to_base64(image_bytes.getvalue())]}
async with aiohttp.ClientSession() as session:
async with session.post("http://192.168.0.189:8868/predict/ocr_system", data=json.dumps(data),
headers=headers) as response:
if response.status == 200:
res = (await response.json())["results"][0]
return res
else:
print(f'Error: {response.status}')
return None
async def process_images(img_strs_list):
tasks = []
sem = asyncio.Semaphore(1) # 限制并发数为5 当创建过多session时就会报错
async with sem:
for img_str in img_strs_list:
task = asyncio.create_task(process_image(img_str))
tasks.append(task)
results = await asyncio.gather(*tasks)
return results
main()
print(f'当前页 共花费--> ', round(time.time() - time1, 3), '\n') # 1.813
(异步与非异步结果差不多)
结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









