






下面介绍几种业界常见的弱监督算法
一、PI model和Temporal Ensembling弱监督算法
原文地址:https://arxiv.org/pdf/1610.02242v1.pdf
这两个算法出自《Temporal Ensembling for Semi-Supervised Learning》,在这篇文章中作者提出了两种弱监督算法,分别为PI model算法和Temporal Ensembling算法,分别为双输入模型和时序组合模型。
1、PI model算法
(1)模型算法流程图:
让同一个图片输入网络两次,由于有一些随机的因素(dropout, augmentation等),会使得两次的隐藏层的输出(也就是z)会不一样,作者把两个不同的z做差,然后求l2,作为loss的一部分,当然loss的另一部分就是那些有标签数据的交叉熵(cross entropy)。另外,由于模型最开始时是很不准确的,所以产生的z可能没有多大意义,所以需要先对有label的数据进行训练,也就是需要把两次不同的z比较的loss进行屏蔽。作者这里设置了一个随时间变化的变量w(t),在t=0时,设置w(t)为0,也是z比较的loss权重为0,然后w(t)随着时间增大而增大。

(2)算法原理: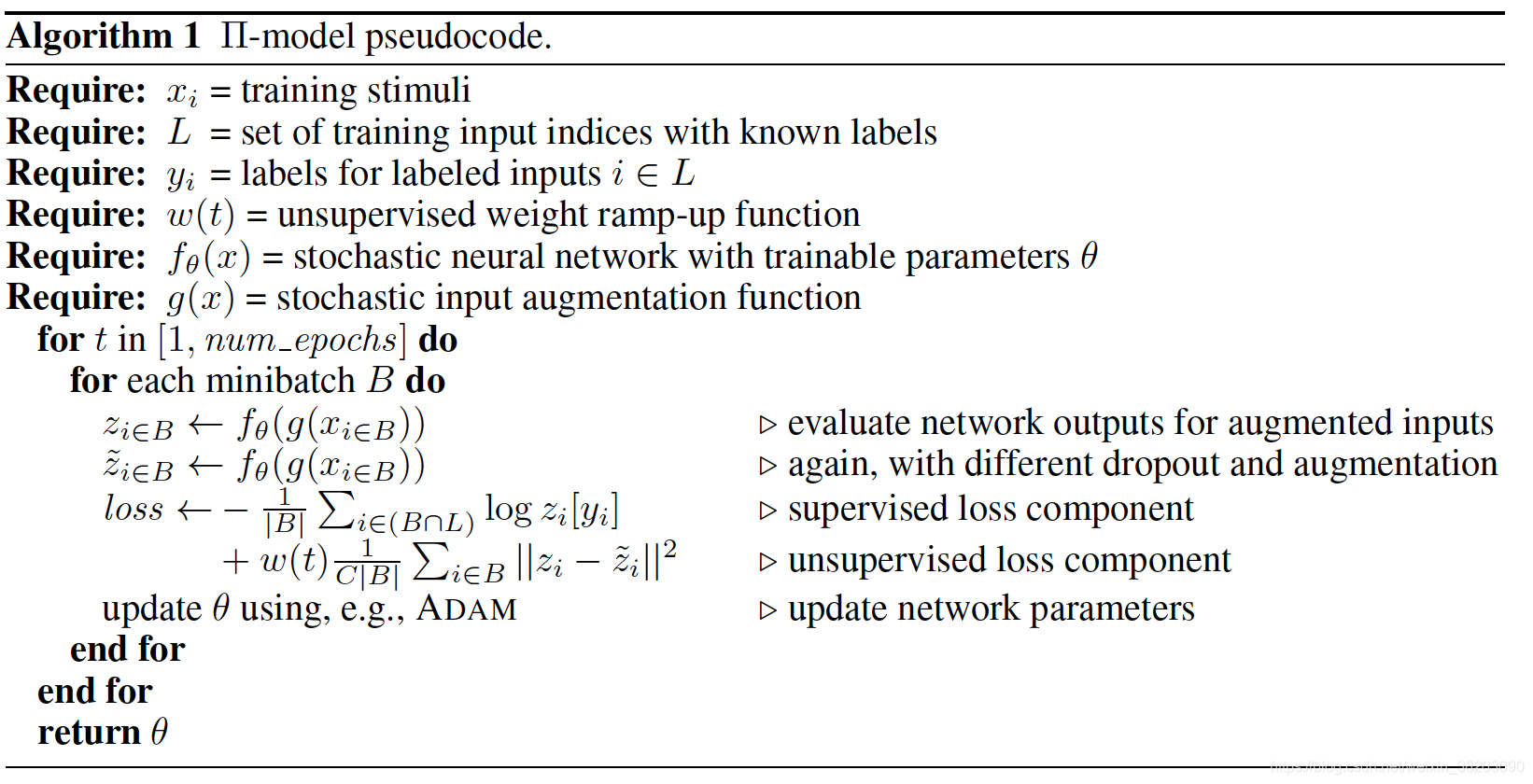
2、Temporal Ensembling算法
(1)算法流程图
时序组合模型和双模型的不同点在于,比较的z来源不同。在双模型中,两个z都是来自同一迭代时间内产生的两次结果。但在时序组合模型中,一个z来自上次迭代周期产生的结果,一个z来自当前迭代时间内产生的结果,也就是比较了两次不同时间内产生的z。在时序组合模型中,由于一次迭代期间内,只用产生一次z,那么相比于双模型,它就有了两倍的加速。作者在论文中说,他们使用的以前的z,并不是恰恰上次迭代的z,而是历史z的加权和,即(这个看着和reinforcement learning 中的reward的更新类似)。这样做的好处是能够保留历史信息,衰减长远历史信息和稳定当前值。

(2)算法原理

二、mean-teacher算法
1、算法流程图
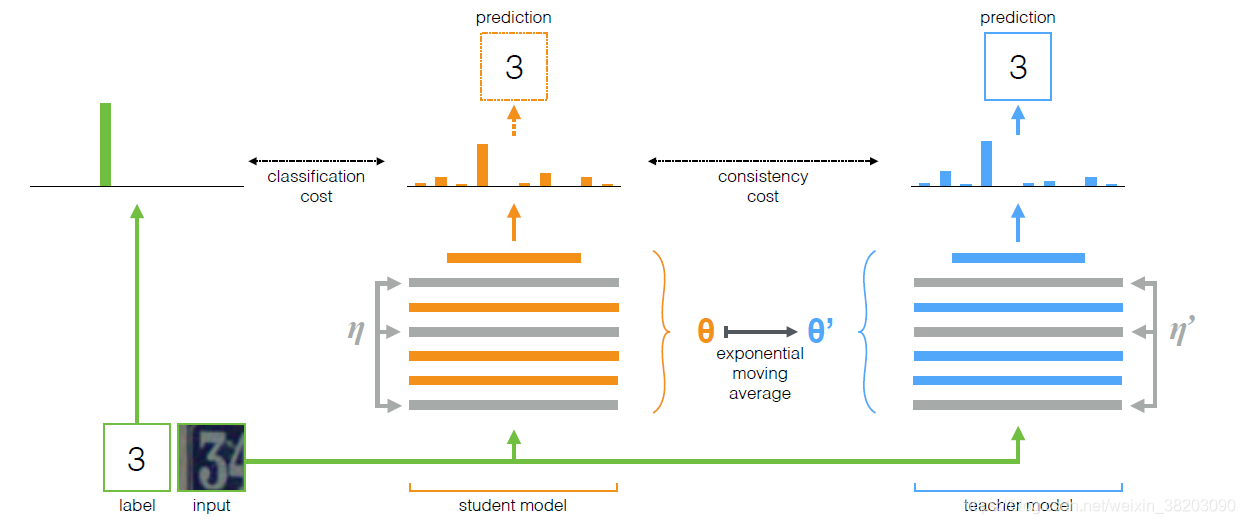
算法的整体包括两个网络,teacher网络和student网络,其中teacher网络是student网络的一份复制,因此网络结构相同,但是网络更新的方式不同,因此是两个独立的网络。student通过梯度下降更新参数,teacher通过student的参数更新。
2、算法loss计算细节
student和teacher模型都接收同一个输入x分别加上不同的噪声η、η′,然后student模型的softmax输出 ,首先和one-hot label做交叉熵(classification cost function),同时和teacher模型做一致性cost function。 这样student的权重更新以后,根据其权重,指数滑动平均EMA来更新teacher。s和t都可以用于预测,但是t可能更好。在u集(无label数据集)上的训练类似,除了没有classification cost function。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









