




 Apache Hudi旨在将Mysql中的实时数据以近实时方式映射到大数据平台,如Hive。本文介绍了Hudi的使用,包括数据实时处理、业务场景和技术选型、Hudi表数据结构、COW和MOR的区别,以及基于Hudi的代码实现和遇到的问题。通过Spark Streaming消费Kafka中的Binlog数据并写入Hudi表,同步历史数据至Hudi及Hive,解决数据实时分析需求。
Apache Hudi旨在将Mysql中的实时数据以近实时方式映射到大数据平台,如Hive。本文介绍了Hudi的使用,包括数据实时处理、业务场景和技术选型、Hudi表数据结构、COW和MOR的区别,以及基于Hudi的代码实现和遇到的问题。通过Spark Streaming消费Kafka中的Binlog数据并写入Hudi表,同步历史数据至Hudi及Hive,解决数据实时分析需求。
Apache Hudi使用简介
文章目录
数据实时处理和实时的数据
实时分为处理的实时和数据的实时
即席分析是要求对数据实时的处理,马上要得到对应的结果
Flink、Spark Streaming是用来对实时数据的实时处理,数据要求实时,处理也要迅速
数据不实时,处理也不及时的场景则是我们的数仓T+1数据
而本文探讨的Apache Hudi,对应的场景是数据的实时,而非处理的实时。它旨在将Mysql中的时候以近实时的方式映射到大数据平台,比如Hive中。
业务场景和技术选型
传统的离线数仓,通常数据是T+1的,不能满足对当日数据分析的需求
而流式计算一般是基于窗口,并且窗口逻辑相对比较固定。
而笔者所在的公司有一类特殊的需求,业务分析比较熟悉现有事务数据库的数据结构,并且希望有很多即席分析,这些分析包含当日比较实时的数据。惯常他们是基于Mysql从库,直接通过Sql做相应的分析计算。但很多时候会遇到如下障碍
- 数据量较大、分析逻辑较为复杂时,Mysql从库耗时较长
- 一些跨库的分析无法实现
因此,一些弥合在OLTP和OLAP之间的技术框架出现,典型有TiDB。它能同时支持OLTP和OLAP。而诸如Apache Hudi和Apache Kudu则相当于现有OLTP和OLAP技术的桥梁。他们能够以现有OLTP中的数据结构存储数据,支持CRUD,同时提供跟现有OLAP框架的整合(如Hive,Impala),以实现OLAP分析
Apache Kudu,需要单独部署集群。而Apache Hudi则不需要,它可以利用现有的大数据集群比如HDFS做数据文件存储,然后通过Hive做数据分析,相对来说更适合资源受限的环境
###Apache hudi简介
使用Aapche Hudi整体思路
Hudi 提供了Hudi 表的概念,这些表支持CRUD操作。我们可以基于这个特点,将Mysql Binlog的数据重放至Hudi表,然后基于Hive对Hudi表进行查询分析。数据流向架构如下

Hudi表数据结构
Hudi表的数据文件,可以使用操作系统的文件系统存储,也可以使用HDFS这种分布式的文件系统存储。为了后续分析性能和数据的可靠性,一般使用HDFS进行存储。以HDFS存储来看,一个Hudi表的存储文件分为两类。

- 包含
_partition_key相关的路径是实际的数据文件,按分区存储,当然分区的路径key是可以指定的,我这里使用的是_partition_key - .hoodie 由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。 .hoodie文件夹中存放了对应的文件合并操作相关的日志文件。
数据文件
Hudi真实的数据文件使用Parquet文件格式存储

.hoodie文件
Hudi把随着时间流逝,对表的一系列CRUD操作叫做Timeline。Timeline中某一次的操作,叫做Instant。Instant包含以下信息
- Instant Action 记录本次操作是一次数据提交(COMMITS),还是文件合并(COMPACTION),或者是文件清理(CLEANS)
- Instant Time 本次操作发生的时间
- state 操作的状态,发起(REQUESTED),进行中(INFLIGHT),还是已完成(COMPLETED)
.hoodie文件夹中存放对应操作的状态记录
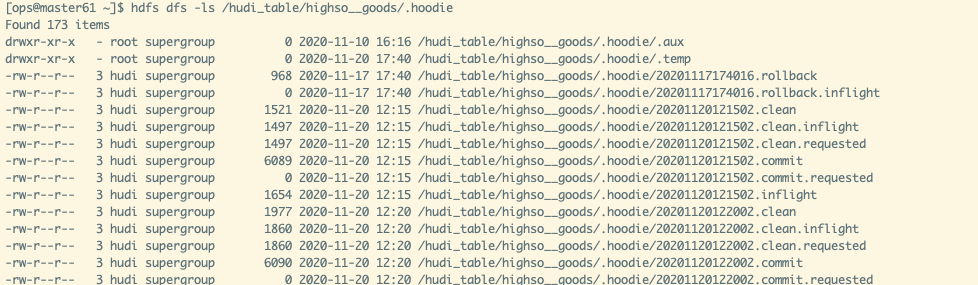
Hudi记录Id
hudi为了实现数据的CRUD,需要能够唯一标识一条记录。hudi将把数据集中的唯一字段(record key ) + 数据所在分区 (partitionPath) 联合起来当做数据的唯一键
COW和MOR
基于上述基础概念之上,Hudi提供了两类表格式COW和MOR。他们会在数据的写入和查询性能上有一些不同
Copy On Write Table
简称COW。顾名思义,他是在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。正在读数据的请求,读取的是是近的完整副本,这类似Mysql 的MVCC的思想。
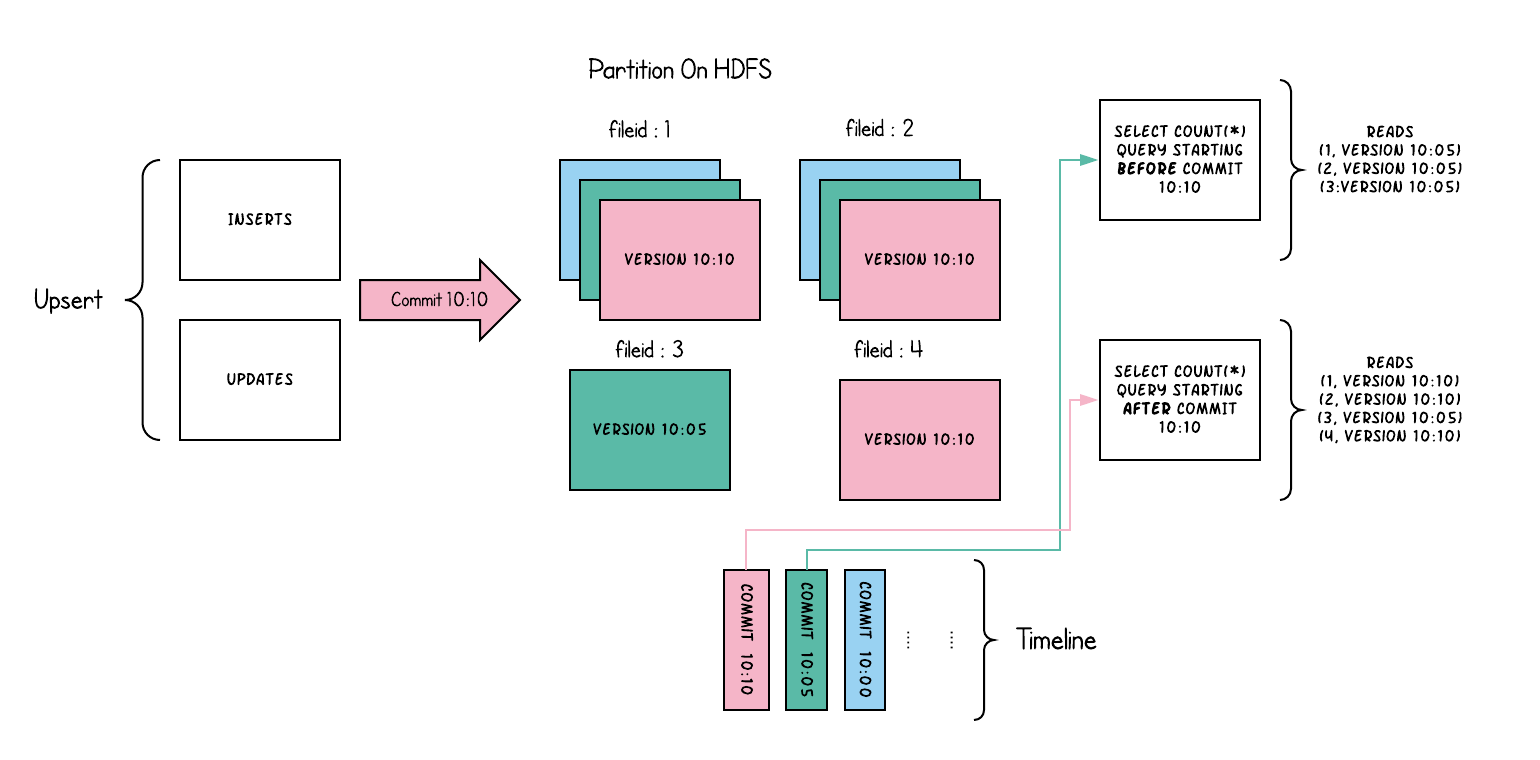
上图中,每一个颜色都包含了截至到其所在时间的所有数据。老的数据副本在超过一定的个数限制后,将被删除。这种类型的表,没有compact instant,因为写入时相当于已经compact了。
- 优点 读取时,只读取对应分区的一个数据文件即可,较为高效
- 缺点 数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。且由于耗时,读请求读取到的数据相对就会滞后
Merge On Read Table
简称MOR。新插入的数据存储在delta log 中。定期再将delta log合并进行parquet数据文件。读取数据时,会将delta log跟老的数据文件做merge,得到完整的数据返回。当然,MOR表也可以像COW表一样,忽略delta log,只读取最近的完整数据文件。下图演示了MOR的两种数据读写方式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G3QT2Ni5-1609071988730)(./1609054767451.png)]](https://i-blog.csdnimg.cn/blog_migrate/3898b3c4ac56f9e39c6e68dc913a399d.png)
- 优点 由于写入数据先写delta log,且delta log较小,所以写入成本较低
- 缺点 需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log 和 老数据文件合并
基于hudi的代码实现
我在github上放置了基于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5038
5038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









