






 本文介绍Google研究的S2S端到端学习方法,用多层长短时记忆(LSTM)将输入序列映射到固定维数向量,再解码目标序列。在WMT 14英法翻译任务中表现出色,颠倒源句单词顺序可提升性能,该方法或能解决其他序列学习问题。
本文介绍Google研究的S2S端到端学习方法,用多层长短时记忆(LSTM)将输入序列映射到固定维数向量,再解码目标序列。在WMT 14英法翻译任务中表现出色,颠倒源句单词顺序可提升性能,该方法或能解决其他序列学习问题。
计划完成深度学习入门的126篇论文第二十五篇,Google的Ilya Sutskever领导研究一种S2S的end to end学习方法。
ABSTRACT&INTRODUCTION
摘要
深度神经网络(DNNs)是一种功能强大的模型,在困难的学习任务中取得了优异的性能。尽管DNNs在有大量标记训练集的情况下工作良好,但它们不能用于将序列映射到序列。在本文中,我们提出了一种对序列结构做最小假设的一般端到端序列学习方法。我们的方法使用多层长短时记忆(LSTM)将输入序列映射到一个固定维数的向量上,然后用另一个深度LSTM从向量上解码目标序列。我们的主要结果是,在WMT 14数据集的英法翻译任务中,LSTM生成的翻译在整个测试集上获得了34.8的BLEU分数,其中LSTMs BLEU的分数是对词汇表外的单词作为惩罚项。此外,LSTM在长句子上没有困难。作为比较,基于短语的SMT系统在同一数据集上的BLEU得分为33.3。当我们使用LSTM对上述SMT系统产生的1000个假设进行重新排序时,它的BLEU分数增加到36.5,接近于之前在这个任务中的最佳结果。LSTM还学习了对词序敏感sensible phrase、对主动语态和被动语态相对不变的有意义的短语和句子表示sentence representations。最后,我们发现颠倒所有源句(但不包括目标句)中的单词顺序显著地提高了LSTM的性能,因为这样做会在源句和目标句之间引入许多短期依赖关系,从而使优化问题变得更容易。
介绍
深度神经网络(DNNs)是一种功能极其强大的机器学习模型,在speech recognition[13,7]和visual object recognition[19,6,21,20]等困难问题上表现优异。DNNs功能强大,因为它们可以执行任意并行计算的步骤不多。DNNs强大功能的一个令人惊讶的例子是,它仅使用2个二次大小的隐藏层[27]对NN位数字排序。因此,虽然神经网络与传统的统计模型有关,但它们学习的是复杂的计算。此外,只要标记的训练集具有足够的信息来指定网络的参数,就可以使用监督反向传播对大型DNN进行训练。因此,如果存在一个大DNN的参数设置,并且取得了很好的效果(例如,因为人类可以非常快速地解决任务),监督反向传播就会找到这些参数并解决问题。
尽管DNNs具有灵活性和强大的功能,但它只适用于输入和目标可以用固定维数向量合理编码的问题。这是一个重要的限制,因为许多重要的问题最好用长度未知的序列来表示。例如,语音识别和机器翻译是顺序问题。同样,问题回答也可以看作是将表示问题的单词序列映射为表示答案的单词序列。因此,一个学习将序列映射到序列的独立于域的方法显然是有用的。
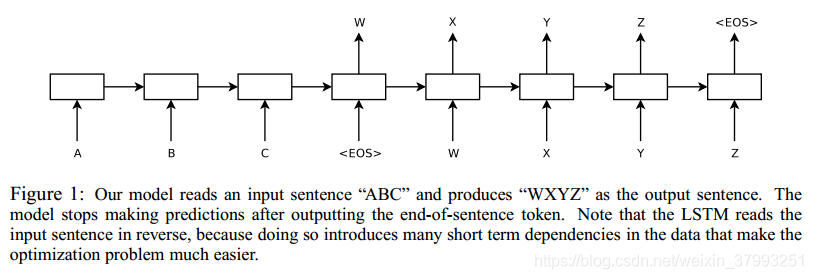
序列对DNNs是一个挑战,因为它们要求输入和输出的维数是已知的和固定的。在本文中,我们证明了长短时记忆(LSTM)结构[16]的直接应用可以解决一般序列到序列的问题。这个想法是使用一个LSTM阅读输入序列,一个步伐,获得大fixed dimensional向量表示,然后使用另一个LSTM从向量中提取的输出序列(图1)。第二个LSTM递归神经网络本质上是一个语言模型[30]28日,23日,除了它是条件输入序列。LSTM年代成功学习能力与远程数据时间依赖性使其自然选择对于这个应用程序,由于相当长的时间滞后之间的输入和相应的输出(图1)。
有很多相关的试图解决一般序列序列与神经网络的学习问题。我们的方法与Kalchbrenner和Blunsom[18]密切相关,他们是第一个将整个输入语句映射到向量的人,并且与Cho等人相关。[5]虽然后者仅用于重新提取基于短语的系统产生的假设。Graves[10]引入了一种新的可微注意机制,它允许神经网络将注意力集中到输入的不同部分,Bahdanau等人将这种思想的一个优雅的变体成功地应用到机器翻译中。连接序列分类是另一种常用的将序列映射到具有神经网络的序列的技术,但它假定输入和输出之间存在单调对齐[11]。
这项工作的主要结果如下。在WMT 14英法翻译任务中,我们使用一个简单的从左到右的波束搜索解码器,直接从5个深度LSTMs(每个LSTMs包含384M参数和8000维状态)中提取译文,获得了34.81的BLEU评分。这是迄今为止用大型神经网络直接翻译得到的最佳结果。作为比较,该数据集上SMT基线的BLEU评分为33.30[29]。34.81 BLEU的分数是通过词汇量为80k的LSTM获得的,所以当参考译文中包含不包含这80k的单词时,该分数就会被扣分。结果表明,相对于基于短语的SMT系统,一种相对未优化的小词汇量神经网络体系结构具有较大的改进空间。
最后,我们使用LSTM对同一任务[29]上的公共可用的1000个SMT基线的最佳列表重新进行了核心处理。通过这样做,我们获得了36.5的BLEU评分,这将基线提高了3.2个BLEU分,接近于之前在该任务中发表的最佳结果(37.0[9])。
令人惊讶的是,LSTM并没有在很长的句子中受到影响,尽管其他研究人员最近有使用相关架构[26]的经验。我们能够做的长句,因为我们逆转源句子中单词的顺序而不是目标句子训练集和测试集。通过这样做,我们介绍了许多短期依赖关系的优化问题更简单(见3.3)。因此,SGD可以学习没有长句子问题的LSTMs。在源句中颠倒单词的简单技巧是这项工作的关键技术贡献之一。
LSTM的一个有用特性是,它学会将一个可变长度的输入语句映射成一个固定维向量表示。考虑到翻译往往是原句的释义,翻译目标鼓励LSTM找到能够捕捉其含义的句子表示形式,因为具有相似含义的句子彼此接近,而含义不同句子的意义会很深远。定性评估支持这一观点,表明我们的模型能够识别词序,并且对主动语态和被动语态相当不变。
2 The model
递归神经网络(RNN)[31,28]是前馈神经网络对序列的一种自然推广。给定一个输入序列![]() ,标准RNN计算一个输出序列
,标准RNN计算一个输出序列![]() 通过迭代下面的方程:
通过迭代下面的方程:
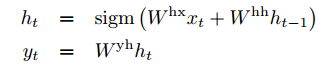
只要预先知道输入和输出之间的对齐,RNN就可以轻松地将序列映射到序列。然而,如何将RNN应用于输入和输出序列长度不同且关系复杂且非单调的问题,目前尚不清楚。
一般序列学习最简单的策略是使用一个RNN将输入序列映射到一个固定大小的向量,然后使用另一个RNN将向量映射到目标序列(Cho等人也采用了这种方法)。虽然它在原则上可以工作,因为RNN提供了所有相关的信息,但是由于由此产生的长期依赖关系(图1),很难训练rns(图1)[14,4,16,15]。然而,众所周知,长短时记忆[16]会学习具有长期时间依赖性的问题,因此LSTM可能在此设置中成功。
LSTM的目标是估计条件概率![]() 其中
其中![]() 是一个输入序列,
是一个输入序列,![]() 是对应的输出序列,其长度T'可能与T不同。LSTM首先获得输入序列
是对应的输出序列,其长度T'可能与T不同。LSTM首先获得输入序列![]() 由LSTM的最后一个隐藏状态给出,然后计算
由LSTM的最后一个隐藏状态给出,然后计算![]() 的概率,用标准LSTM-LM公式,初始隐藏状态设为v的表示
的概率,用标准LSTM-LM公式,初始隐藏状态设为v的表示![]() :
:
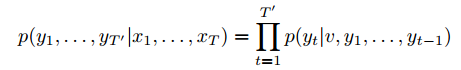
在这个方程中,每个![]() 分布用softmax表示词汇表中的所有单词。我们使用格雷夫斯[10]的LSTM公式。注意,我们要求每个句子都以一个特殊的句末符号<EOS>结束,这使模型能够定义所有可能长度序列上的分布。总体方案如图1所示,其中所示的LSTM计算A、B、C、<EOS>的表示,然后使用该表示计算W、X、Y、Z、<EOS>的概率。
分布用softmax表示词汇表中的所有单词。我们使用格雷夫斯[10]的LSTM公式。注意,我们要求每个句子都以一个特殊的句末符号<EOS>结束,这使模型能够定义所有可能长度序列上的分布。总体方案如图1所示,其中所示的LSTM计算A、B、C、<EOS>的表示,然后使用该表示计算W、X、Y、Z、<EOS>的概率。
我们的实际模型在三个重要方面与上述描述不同。
- 首先,我们使用了两种不同的LSTM:一种用于输入序列,另一种用于输出序列,因为这样做增加了数字模型参数,而计算成本可以忽略不计,并且可以很自然地同时在多个语言对上训练LSTM。
- 其次,我们发现深度LSTM明显优于浅层LSTM,因此我们选择了一个四层的LSTM。第三,我们发现颠倒输入句子的单词顺序非常有价值。
- 例如,LSTM需要映射c, b, a到α,β,γ,而不是映射句子a, b, c的句子α,β,γ,α,β,γ被翻译为a,b,c。这样,一个是在靠近α,b是相当接近β,这一事实使它容易SGD建立输入和输出之间的沟通。我们发现这种简单的数据转换可以极大地提高LSTM的性能。
3 Experiments
我们将我们的方法应用到WMT 14英语到法语的MT任务中,方法有两种。在不使用参考SMT系统的情况下,我们使用它直接翻译输入语句,并重新确定SMT基线的n-best列表。我们报告了这些翻译方法的准确性,给出了示例翻译,并将结果的句子表示可视化。
3.1 Dataset details
我们使用了从英语到法语的WMT 14数据集。我们将模型训练在一个由3.48亿个法语单词和3.04亿个英语单词组成的1200万个句子子集上,这是从[29]中挑选出来的一个干净的子集。我们之所以选择这个翻译任务和这个特定的培训集子集,是因为一个标记化的培训和测试集以及来自基线SMT[29]的1000个最佳列表是公开可用的。
由于典型的神经语言模型依赖于每个单词的向量表示,因此我们对这两种语言都使用了固定的词汇表。我们在源语言中使用了16万个最频繁的单词,在目标语言中使用了8万个最频繁的单词。每一个词汇表外的单词都被替换为一个特殊的扣篮标记。
3.2 Decoding and Rescoring
我们实验的核心是在许多句子对上训练一个大型的深度LSTM。我们通过最大化给定源句S的正确翻译的log概率来训练它,所以训练目标是:
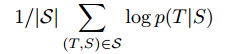
其中S为训练集,一旦训练完成,我们根据LSTM找到最可能的译文生成译文:
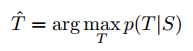
我们使用一个简单的从左到右beam search解码器来搜索最有可能的翻译,该解码器保留了少量的部分假设B,其中部分假设是一些翻译的前缀。在每个时间步长中,我们用词汇表中每个可能的单词来扩展梁中的每个部分假设。这大大增加了假设的数量,所以根据模型对数概率,我们抛弃了除B之外的所有最有可能的假设。一旦<EOS>符号被添加到一个假设中,它就从波束中移除,并添加到完整假设集中。虽然这个解码器是近似的,但实现起来很简单。有趣的是,即使波束大小为1,我们的系统也运行得很好,而beam大小为2的系统提供了beam search的大部分好处(表1)。
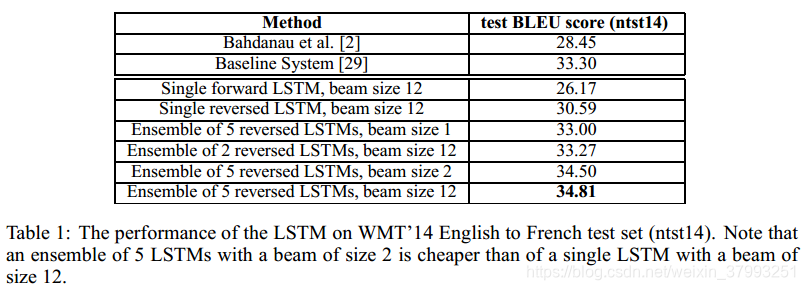
我们还使用LSTM对基线系统[29]生成的1000个最佳列表重新进行了核取。为了重新构建一个n-best列表,我们使用LSTM计算每个假设的log概率,并对它们的得分和LSTM的得分取平均。
3.3 Reversing the Source Sentences
虽然LSTM能够解决具有长期依赖关系的问题,但是我们发现,当源语句被反转(目标语句没有反转)时,LSTM学习得更好。通过这样做,LSTM的perplexity从5.8下降到4.7,其译码翻译的测试BLEU分数从25.9增加到30.6。
虽然我们对这一现象没有一个完整的解释,但我们认为这是由于对数据集引入了许多短期依赖关系造成的。通常,当我们把源句和目标句连接起来时,源句中的每个单词都与目标句中的对应单词相差很远。因此,该问题具有很大的最小时间延迟[17]。通过倒装源句中的单词,保持源语言中对应单词与目标语言的平均距离不变。然而,源语言的前几个单词现在与目标语言的前几个单词非常接近,因此问题的最小时间延迟大大减少。因此,反向传播更容易在源句和目标句之间建立通信,从而大大提高了整体性能。
一开始,我们认为把输入的句子倒过来只会在目标句的前半部分产生更自信的预测,在后半部分产生更不自信的预测。然而,经过反向源句训练的LSTMs在长句上的表现要比LSTMs好得多对原始源句进行训练(参见第3.7节),这表明反转输入句可以获得更好的内存利用率。
3.4 Training details
我们发现LSTM模型很容易训练。我们使用了4层的深度LSTMs,每层有1000个单元格和1000个维度的单词嵌入,输入词汇量为16万个,输出词汇量为8万个。因此,深层LSTM使用8000个实数表示一个句子。我们发现深层的LSTMs明显优于浅层的LSTMs,每增加一层LSTMs都会减少近10%的困惑,这可能是因为它们的隐藏状态要大得多。我们在每个输出中使用一个朴素的softmax超过80,000个单词。所得到的LSTM具有384M参数,其中64M是纯循环连接(编码器LSTM为32M,解码器LSTM为32M)。完整的培训详情如下
- 初始化所有LSTM s参数,其分布在-0.08和0.08之间,均为均匀分布
- 采用无动量随机梯度下降法,学习速度固定为0.7。经过5个epochs后,我们开始每半个epoch将学习速度减半。我们总共训练了7.5个epochs的模型。
- 使用128个序列的批次作为梯度,并将其划分为批次的大小(即128)。
- 虽然LSTMs往往不受消失梯度问题的困扰,但它们可以有爆炸梯度。因此,我们在梯度的范数超过阈值时对其进行缩放,从而对梯度的范数施加了一个硬约束[10,25]。对于每个训练批次,我们计算
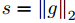 ,其中g是梯度除以128。如果s是> 5,我们设g = 5s/g。
,其中g是梯度除以128。如果s是> 5,我们设g = 5s/g。 - 不同的句子有不同的长度。大多数句子都很短(如长度20-30),但也有一些句子很长(如长度为> 100),所以随机选择的128个训练句子的小批量会有很多短句子和很少的长句子,因此在小批量中浪费了大量的计算量。为了解决这个问题,我们确保一个小批处理中的所有句子的长度大致相同,从而产生2x的加速。
3.5 Parallelization
一个c++实现的深层LSTM配置从上一节对一个GPU处理速度约1700字每秒。这对于我们的目的来说太慢了,所以我们使用8-GPU机器并行化我们的模型。LSTM的每一层都是在不同的GPU上执行的,一旦计算完成,就把它的激活传递给下一层GPU /层。我们的模型有4层LSTMs,每一层都位于一个单独的GPU上。剩下的4个GPU用于并行化softmax,因此每个GPU负责乘以一个100020000矩阵。最终实现的速度达到每秒6300个单词(包括英语和法语),小批处理大小为128。实施这一计划花了大约十天的时间进行训练。
3.6 Experimental Results
我们使用大小写混合的BLEU评分[24]来评估翻译的质量。我们使用多重蓝来计算我们的蓝分数。pl1关于符号化的预言和地面真相。这种评价BELU分数的方法与[5]、[2]一致,再现了[29]的33.3分。但是,如果我们以这种方式评估最佳的WMT 14系统[9](其预测可以从statmt.org\matrix下载),我们得到37.0,这大于statmt.org\matrix报告的35.8。
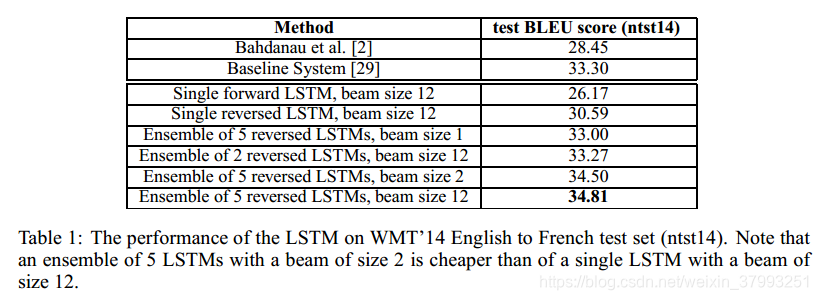

结果见表1和表2。我们的最佳结果是在LSTMs的集合中得到的,这些LSTMs的随机初始化和小批量随机顺序不同。虽然LSTM集成的解码翻译并没有超过最佳的WMT 14系统,但这是第一次一个纯神经翻译系统在大规模上超过基于短语的SMT数据集。尽管它无法处理词汇量以外的单词,但它在这方面的优势还是相当大的。如果使用LSTM重新确定基线系统的1000个最佳列表,则LSTM距离最佳WMT ' 14结果的0.5个BLEU点以内。
3.7 Performance on long sentences
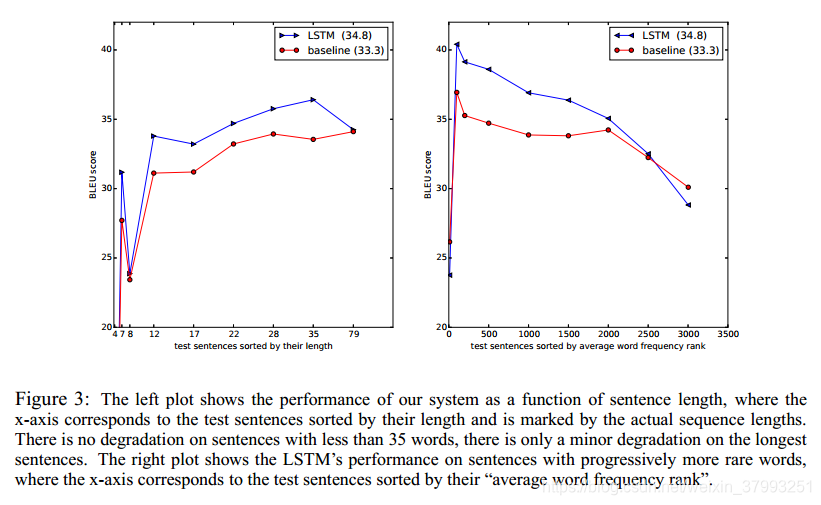
我们惊奇地发现LSTM在长句上表现得很好,如图3所示。表3给出了一些长句及其翻译的例子。

3.8 Model Analysis
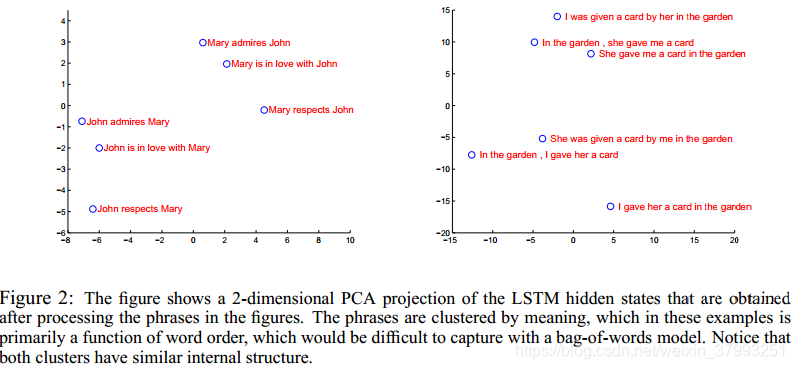
我们的模型的一个吸引人的特性是它能够将一个单词序列转换成一个固定维数的向量。图2显示了一些学习到的表示。图中清楚地显示,表示对单词的顺序敏感,而对用被动语态代替主动语态。利用主成分分析得到二维投影。
4 Related work
神经网络在机器翻译中的应用有大量的工作要做。到目前为止,将RNN-Language模型(RNNLM)[23]前馈神经网络语言模型(NNLM)[3]应用于翻译任务的最简单和最有效的方法是重新提取强MT基线[22]的最佳列表,从而可靠地提高翻译质量。
最近,研究人员开始研究将源语言信息包含到NNLM中的方法。这项工作的例子包括Auli等人的[1],他们将NNLM与输入语句的主题模型相结合,从而提高了重新取心的性能。Devlin等人也采用了类似的方法,但他们将NNLM合并到MT系统的解码器中,并使用解码器的对齐信息为NNLM提供输入句子中最有用的单词。他们的方法非常成功,并且比基线有了很大的改进。
我们的工作与Kalchbrenner和Blunsom[18]密切相关,他们首先将输入的句子映射到一个向量,然后再返回到一个句子,尽管他们使用卷积神经网络将句子映射到向量,而卷积神经网络失去了单词的顺序。与此类似,Cho等人使用类似lstm的RNN架构将句子映射成向量并返回,尽管他们的主要关注点是将神经网络集成到SMT系统中。Bahdanau等人的[2]也尝试使用神经网络直接翻译,该神经网络利用注意力机制来克服Cho等人的[5]在长句上的糟糕表现,并取得了令人鼓舞的结果。同样地,Pouget-Abadie等人的[26]试图通过翻译源句的片段来解决Cho等人的记忆问题,这种翻译方法产生流畅的译文,类似于基于短语的方法。我们怀疑,他们可以通过简单地训练他们的网络使用倒装的源语句来实现类似的改进。
端到端训练也是Hermann等人[12]的重点,他们的模型表示前馈网络的输入和输出,并将它们映射到空间中的相似点。然而,他们的方法不能直接生成翻译:为了得到翻译,他们需要在预先计算好的句子数据库中查找最近的向量,或者重新编译一个句子。
5 Conclusion
在这项工作中,我们展示了一个大型的深度LSTM,它有一个有限的词汇量,这使得几乎没有关于问题结构的假设可以胜过一个标准的基于smt的系统,它的词汇量是无限的,在一个大规模的MT任务。我们基于lstm的简单方法在MT上的成功表明,如果其他序列学习问题有足够的训练数据,那么它应该可以很好地解决这些问题。我们惊讶地发现,把原句中的单词倒过来所取得的进步之大。我们的结论是,重要的是找到一个短期依赖关系最多的问题编码,因为它们使学习问题简单得多。特别是,虽然我们无法在非倒转问题上训练标准RNN(如图1所示),但我们认为,当源语句倒转时,标准RNN应该是容易训练的(尽管我们没有通过实验验证)。我们也对LSTM能够正确翻译很长的句子感到惊讶。我们最初确信LSTM在长句上会失败,因为它的记忆有限,其他研究人员报告说,使用与我们相似的模型,长句的表现很差[5,2,26]。然而,在反向数据集上训练的LSTMs在翻译长句子方面几乎没有什么困难。最重要的是,我们证明了一个简单、直接和相对未经优化的方法可以胜过SMT系统,因此进一步的工作可能会导致更高的翻译精度。这些结果表明,我们的方法很可能在其他具有挑战性的序列对序列问题上做得很好。


















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









