






 本文介绍了一种利用LSTM处理序列到序列问题的方法,通过多层LSTM将输入转换为固定维度向量,并解码为目标序列,特别适用于机器翻译任务。实验证明,颠倒输入语句顺序能显著提升翻译质量。
本文介绍了一种利用LSTM处理序列到序列问题的方法,通过多层LSTM将输入转换为固定维度向量,并解码为目标序列,特别适用于机器翻译任务。实验证明,颠倒输入语句顺序能显著提升翻译质量。
摘要:
Deep Neural Network(DNN) 不太适合处理序列到序列的问题,这篇论文提出了一种端到端的方式处理序列到序列的问题。使用一个多层LSTM将输入转化为固定维度的向量,然后用另一个LSTM将目标向量decode成目标序列。这种方法对于长一些的序列也适用。将源输入语句的顺序倒叙输入模型中,可以更好的提高效果,比如原句是A B C 按照C B A的顺序的话,由于距离target更近,效果更好了。
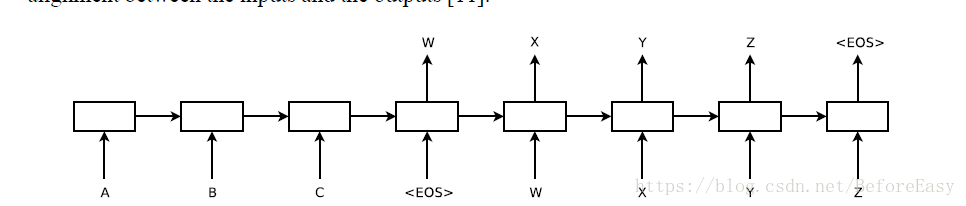
模型结构 <EOS>为标记序列的结束,模型读入ABC,输出WXYZ
使用RNN也可以训练序列到序列,但是输入序列和输出序列的长度得一样,RNN的预测是P(y1,y2,,,,yt|x1,x2,,,xt)其中y是输出序列,x是输入序列,两者长度相等;
LSTM可以处理比较长的时间依赖,LSTM的目标是预测这个概率:P(y1,y2,,,ym|x1,x2,,,xt),其中(x1,x2,,xt)是输入序列,而(y1,y2,,ym)是对应的输出序列,两者的长度可以不等。 LSTM先将输入序列X转化为固定维度的向量v,然后在计算概率:
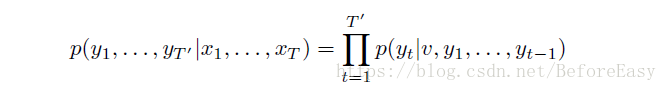
其中每一个P(yt|v,y1,,,,yt-1)都会基于整个单词表作softmax处理,序列的结束都是<EOS>标志位
具体的实验过程 是应用在WMT'14 英语到法语的机器翻译。在众多序列上训练,训练目标是
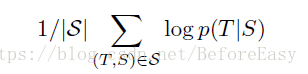 最大化,其中S 是训练数据集,T是正确的翻译,选取概率最大的那句作为输出的翻译:
最大化,其中S 是训练数据集,T是正确的翻译,选取概率最大的那句作为输出的翻译:
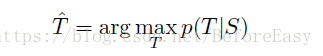
注意到,将源语句的顺序颠倒后,BLEU分数从25.9上升到了30.6
训练时用了多个GPU实现并行化

















 2644
2644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









