









 本文深入探讨Keras函数式API的使用,包括多输入、多输出模型的构建,以及如何利用Keras回调函数和TensorBoard进行模型监控。介绍了高级深度学习实践,如批标准化、深度可分离卷积和模型集成。
本文深入探讨Keras函数式API的使用,包括多输入、多输出模型的构建,以及如何利用Keras回调函数和TensorBoard进行模型监控。介绍了高级深度学习实践,如批标准化、深度可分离卷积和模型集成。
本文为《Python深度学习》的学习笔记。
第7章 高级的深度学习最佳实践
Keras函数式API
使用Keras回调函数
使用Tensorboard可视化工具
开发最先进模型的重要实践
7.1 不用Sequential模型的解决方案:Keras函数式API
之前6章所有神经网络都是用Sequential模型实现的。Sequential模型假设,网络只有一个输入和输出,且网络是线性堆叠的。
有些任务需要多模态输入,可以合并这些不同输入源的数据。
同样,有些任务需要预测输入数据的多个目标属性。
以及ResNet。
7.1.1 函数式API简介
from keras import Input, layers
input_tensor = Input(shape = (322,))
dense = layers.Dense(32, activation = 'relu')
output_tensor = dense(input_tensor)
这里可以直接操作张量,把层Dense当做函数使用,接受张量并返回张量。
from keras.models import Sequential, Model
from keras import layers
from keras import Input
seq_model = Sequential()
seq_model.add(layers.Dense(32, activation = 'relu', input_shape = (64,)))
seq_model.add(layers.Dense(32, activation = 'relu'))
seq_model.add(layers.Dense(10, activation = 'softmax'))
input_tensor = Input(shape=(64,))
x = layers.Dense(32, activation = 'relu')(input_tensor)
x = layers.Dense(32, activation = 'relu')(x)
output_tensor = layers.Dense(10, activation = 'softmax')(x)
model = Model(input_tensor, output_tensor)
model.summary()
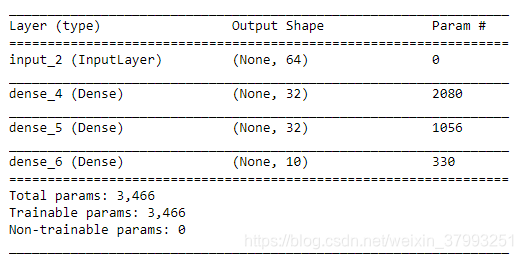
这里我们将Model对象实例化只用了一个输入张量和一个输出张量。
7.1.2 多输入模型
API可用于构建多个输入的模型。
- 下面示例如何用函数式API构建这样的模型。
# 7-1 用函数式API实现双输入问答模型
from keras.models import Model
from keras import layers
from keras import Input
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
text_input = Input(shape=(None,), dtype='int32', name='text')
embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input) # 将输入嵌入长度为64的向量
encoded_text = layers.LSTM(32)(embedded_text)
question_input = Input(shape=(None,), dtype='int32', name='question') # 对问题进行相同的处理
embedded_question = layers.Embedding(text_vocabulary_size, 32)(question_input)
encoded_question = layers.LSTM(15)(embedded_question)
concatenated = layers.concatenate([encoded_text, encoded_question], axis = -1) # 将编码后的问题和文本链接起来
answer = layers.Dense(answer_vocabulary_size, activation='softmax')(concatenated) # 在上面添加softmax分类器
model = Model([text_input, question_input], answer)
model.compile(optimizer='rmsprop', loss = 'categorical_crossentropy', metrics=['acc'])
- 可以向模型属于一个numpy数组组成的列表,或者输入一个名称映射为numpy的数组的字典。
# 7-2 将数据输入到多输入模型中
import numpy as np
from keras.utils import to_categorical
num_samples = 1000
max_length = 100
text = np.random.randint(1, text_vocabulary_size, size =(num_samples, max_length))
question = np.random.randint(1, question_vocabulary_size, size=(num_samples, max_length))
answers = np.random.randint(answer_vocabulary_size, size=(num_samples))
answers = to_categorical(answers, answer_vocabulary_size)
model.fit([text, question], answers, epochs=10, batch_size=128)
model.fit({'text': text, 'question':question}, answers, epochs=10, batch_size=128)
7.1.3 多输出模型
- 使用函数式API构建多个输出的模型。
# 7-3 用函数式API实现一个三输出模型
from keras import layers
from keras import Input
from keras.models import Model
vocabulary_size = 50000
num_income_groups = 10
posts_input = Input(shape=(None,), dtype='int32', name='posts')
embedded_posts = layers.Embedding(256, vocabulary_size)(posts_input)
x = layers.Conv1D(128, 5, activation='relu')(embedded_posts)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(128, activation='relu')(x)
age_prediction = layers.Dense(1, name='age')(x)
income_prediction = layers.Dense(num_income_groups, activation='softmax',name='income')(x)
gender_prediction = layers.Dense(1, activation='sigmoid', name='gender')(x)
mdoel = Model(posts_input, [age_prediction, income_prediction, gender_prediction])
- 训练这种模型需要对网络各个头制定不同的损失函数。
# 7-4 多输出模型的编译选项:多重损失
'''
model.compile(optimizer='rmsprop',
loss=['mse', 'categoracal_crossentropy', 'binary_crossentropy'])
'''
model.compile(optimizer='rmsprop',
loss={'age':'mse',
'income': 'categorical_crossentropy',
'gender': 'binary_crossentropy'})
- 为了平衡不同损失的贡献,让交叉熵的损失权重取10,而MSE损失的权重取0.5。
# 7-5 多输出模型的编译选项:损失加权
model.compile(optimizer='rmsprop',
loss=['mse','categorical_crossentropy','binary_crossentropy'],
loss_weights = [0.25, 1., 10.])
# 与上面方法等效,且只有输出层具有名称时才采用这种写法
model.compile(optimizer='rmsprop',
loss={'age':'mse',
'income': 'categorical_crossentropy',
'gender': 'binary_crossentropy'}
loss_weights = {'age': 0.25,
'income': 1.,
'gender': 10.})
# 7-6 将数据输入到多输出模型中
model.fit(posts, [age_targets, income_targets, gender_targets], epochs=10, batch_size=64)
mode.fit(posts, {'age': age_targets,
'income': income_targets,
'gender': gender_targets},
epochs=10, batch_size=64)
7.1.4 层组成的有向无环图
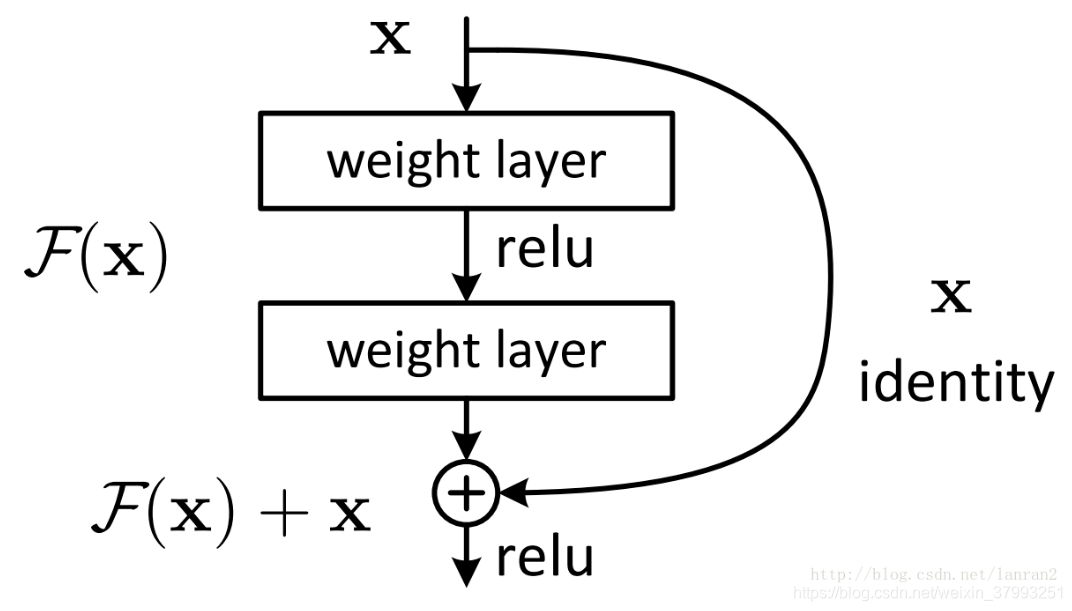
利用Keras中的神经网络可以是层组成的任意有向无环图。两个著名的模型是Inception模块和残差连接。
- Inception模块
Google:模块的堆叠,并行分支。InceptionV3:
- 1x1卷积的作用(点卷积):有助于区分开通道特征学习和空间特征学习。
7.1.5 共享层权重
函数APi能够多次重复使用一个层的实例。每次调用可以重复使用相同的权重。
# 共享权重
from keras import layers
from keras import Input
from keras.models import Model
lstm = layers.LSTM(32)
# 构建模型的左右分支
left_input = Input(shape=(None, 128))
left_output = lstm(left_input)
right_input = Input(shape=(None, 128))
right_output = lstm(right_input)
# 在上面构建一个分类器
merged = layers.concatenate([left_output, right_output], axis = -1)
predictions = layers.Dense(1, activation = 'sigmoid')(merged)
# 模型实例化
model = Model([left_input, right_input], predictions)
model.fit([left_data, right_data], targets)
7.1.6 将模型作为层
函数式APi中,可以像使用层一样使用模型。
类似于y=model(x),如果模型具有多个输入张量和多个输出张量,那么意味着可以在一个输入张量上调用模型,并得到一个输出张量。y1, y2 = model([x1, x2])
from keras import layers
from keras import applications
from keras import Input
xception_base = applications.Xception(weights=None, include_top = False)
left_input = Input(shape=(250, 250, 3))
right_input = Input(shape=(250, 250, 3))
left_features = xception_base(left_input)
right_input = xception_base(right_input)
merged_features = layers.concatenate([left_features, right_input], axis = -1)
7.2 使用Keras回调函数和TensorBoard来检查并监控深度学习模型
本节介绍训练过程中如何更好访问并控制模型内部过程的方法。
7.2.1 训练过程中将回调函数作用于模型
- 模型检查点
- 提前终止
- 在训练过程中动态调节某些函数值
- 在训练过程中记录训练指标和验证指标
- ModelCheckpoint与EarlyStoppping回调函数
如果监控的目标轮数不再改善,可以EarlyStopping来回调函数。
import keras
callback_list =[
keras.callbacks.EarlyStopping(
monitor = 'acc',
patience = 1,
),
keras.callbacks.ModelCheckpoint(
filepath = 'my_model.h5',
monitor = 'val_loss',
save_best_only = True,
)
]
model.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics = ['acc'])
'''
model.fit(x, y, epochs=10,
batch_size = 32,
callbacks = callbacks_list,
validation_data = (x_val, y_val))
'''
这里通过callback这个参数将earlystoppping和modelcheckpointliangge属性加入模型。
- ReduceLROnPlateau回调函数
如果验证损失不再改善,可以使用这个回调函数降低学习率。
callback_list =[
keras.callbacks.ReduceLROnPlateau(
monitor = 'val_loss',
factor = 0.1,
patience = 10,
)
]
- 编写自己的回调函数
创建keras.callbacks.Callback类的子类,实现下面的方法:
on_epoch_begin 在每轮开始时被调用
on_epoch_end
on_batch_begin 在处理每个批量之前被调用
on_batch_end
on_train_begin 在训练开始时被调用
on_train_end
import keras
import numpy as np
class ActivationLogger(keras.callbacks.Callback):
def set_model(self, model):
self.model = model
layer_outputs = [layer.output for layer in model.layers]
self.activations_model = keras.models.Model(model.input, layer_outputs)
def on_epoch_end(self, epoch, logs = None):
if self.validation_data is None:
raise RuntimeError('Requires validation_data.')
validation_sample = self.validation_data[0][0:1]
activations = self.activations_model.predict(validation_sample)
f = open('actifvations_at_epoch_' + str(epoch) + '.npz', 'w')
np.savez(f, activations)
f.close()
7.2.2 TensorBoard简介:TensorFlow的可视化框架
想要做好研究或者开发出好的模型,需要知道模型内部发生了什么。
# 7-7 使用了TensorBoard的文本分类模型
import keras
from keras import layers
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 2000
max_len = 500
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = max_features)
x_train = sequence.pad_sequences(x_train, maxlen = max_len)
x_test = sequence.pad_sequences(x_test, maxlen = max_len)
model = keras.models.Sequential()
model.add(layers.Embedding(max_features, 128, input_length = max_len, name = 'embed'))
model.add(layers.Conv1D(32, 7, activation = 'relu'))
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32, 7, activation = 'relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics = ['acc'])
在开始使用TensorBoard之前创建一个目录,保存生成的日志文件。在cmd窗口输入。
# 7-8 为TensorBoard日志文件创建一个目标
$ mkdir my_log_dir
# 7-9 使用一个TensorBoard回调函数来训练模型
callbacks = [
keras.callbacks.TensorBoard(
log_dir = 'my_log_dir',
histogram_freq = 1,
embeddings_freq = 1,
)
]
history = model.fit(x_train, y_train, epochs = 20,
batch_size = 128,
validation_split = 0.2,
callbacks = callbacks)
下面使用命令启动TensorBoard服务器。
S tensorboard --logdir = my_log_dir4
7.3 让模型性能发挥到极致
7.3.1 高级架构模式
- 批标准化BatchNorm:训练过程中适应性将数据标准化。
- 深度可分离卷积:有一个层可以替代Conv2D,让模型跟轻量。
7.3.2 超参数优化
hyperparameter
7.3.3 模型集成
将一组分类器的预测结果汇集在一起。

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









