











- 作者:Baining Zhao, Rongze Tang, Mingyuan Jia, Ziyou Wang, Fanghang Man, Xin Zhang, Yu Shang, Weichen Zhang, Chen Gao, Wei Wu, Xin Wang, Xinlei Chen, Yong Li
- 单位:清华大学
- 论文标题:AirScape: An Aerial Generative World Model with Motion Controllability
- 论文链接:https://arxiv.org/pdf/2507.08885
- 项目主页:https://embodiedcity.github.io/AirScape/
主要贡献
- 提出了首个用于训练和测试空中世界模型的数据集,包含11k个带有对应提示的空中智能体视频片段,涵盖了动作、意图或任务指令等多种信息。
- 构建了首个能够基于可控意图在三维空间中预测视觉观察结果的空中世界模型AirScape,填补了空中世界模型研究的空白。
- 实验分析表明,与通用视频生成模型或其他世界模型相比,AirScape在复杂的空中场景中展现出更强的具身指令遵循模拟和预测能力,平均在FID、FVD和IAR指标上分别提高了14.91%、14.63%和165.64%。
研究背景

- 世界模型的发展:生成模型的进展推动了世界模型的发展范式转变,使其能够基于文本和动作输入生成和模拟真实环境,实现反事实推理,帮助智能体在未知或复杂环境中更好地决策。世界模型对具身机器人和自动驾驶等下游应用至关重要,并能增强智能体的空间智能。
- 现有研究局限:以往关于空间世界模型的研究主要集中在人形机器人和自动驾驶应用,但人形机器人侧重于操作和室内环境建模,自动驾驶则聚焦于驾驶行为预测和道路动力学建模,二者多在二维平面操作,动作空间有限。而与之相比,空中智能体如无人机在三维空间中具有六自由度,能探索更广泛的空间和执行更灵活的动作,因此需要一个更通用的三维空间世界模型。
空中世界模型数据集
在研究空中世界模型时,合适的训练数据至关重要。然而,现有的数据集多为第三人称视角或地面机器人、车辆的视角,缺乏针对空中智能体的第一人称视角视频及对应的文本提示,因此构建一个新的空中世界模型数据集显得尤为必要。
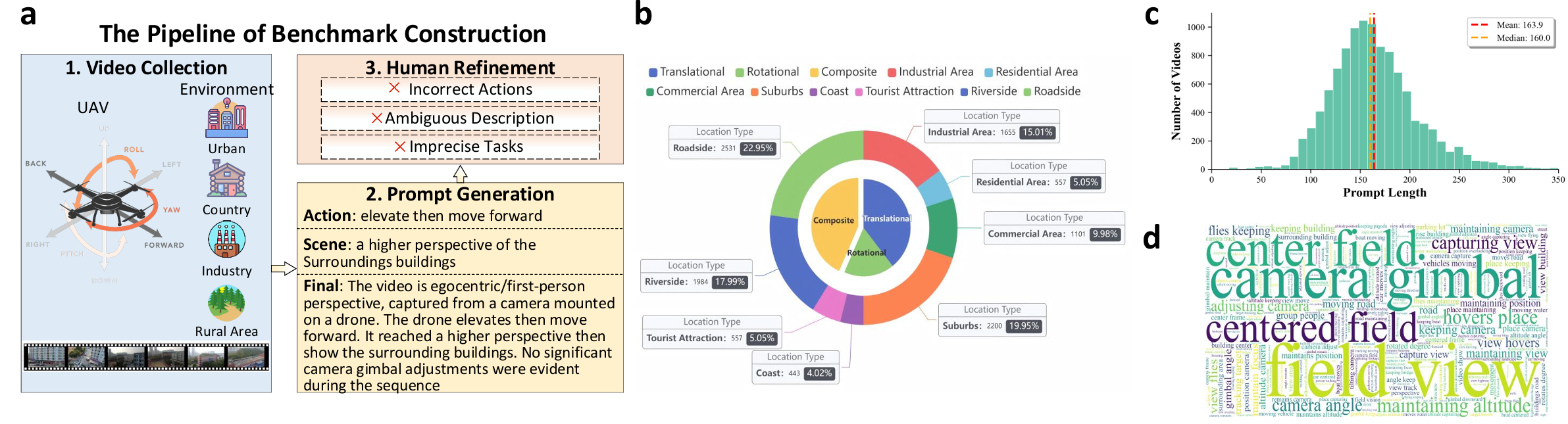
数据集构建流程
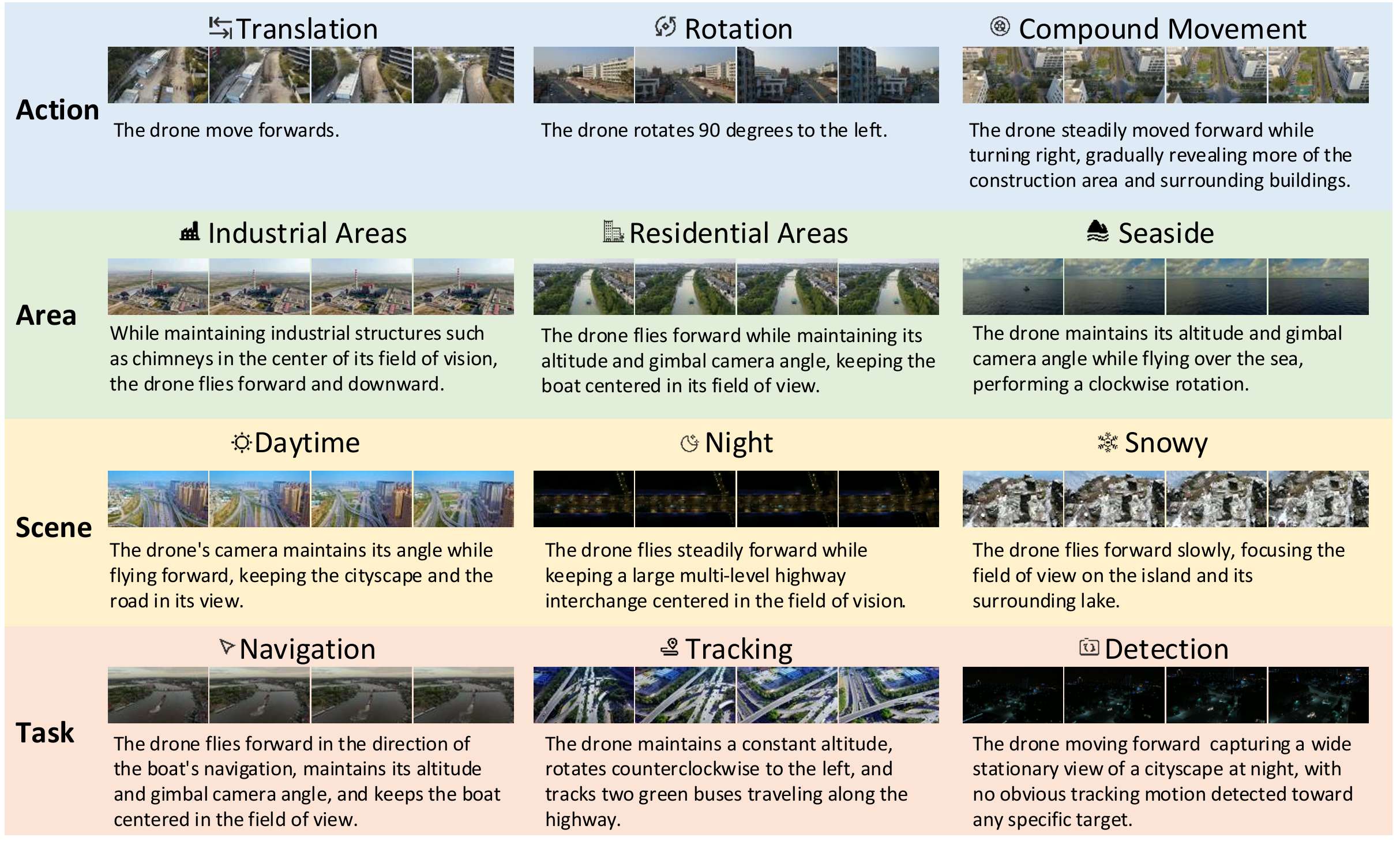
- 视频收集:从三个开源的数据集(UrbanVideo-Bench、NAT2021和WebUAV-3M)中收集无人机拍摄的第一人称视角视频。这些数据集涵盖了多种任务,如视觉语言导航、跟踪等,包含丰富多样的无人机动作,且场景类型广泛,包括工业区、住宅区、郊区和沿海地区等,还涉及晴天、夜晚等多种天气条件。
- 视频分割与过滤:将收集到的视频分割成129帧的片段,并过滤掉那些静态或有突变的片段,以确保数据质量。
- 动作意图标注:利用运动语言模型(LMM)来推断无人机的运动意图。这些意图包括简单的单个动作(如向左旋转45度)和特定任务(如跟踪前方的白色汽车)。设计了一个简单的链式思考过程,首先确定动作,然后总结其停止条件,最后将它们整合成一个连贯且逻辑合理的意图提示。
- 人工精修:由于最先进的多模态大型语言模型也难以准确地从具身视角的变化中推断出智能体的运动,因此进行了超过1000小时的人工精修工作,主要纠正了以下问题:不正确的动作、模糊的描述以及描述中不精确的任务。
数据集统计特性
- 视频和文本意图均展现出多样性,使其非常适合训练和测试能够预测未来序列观察的模型。
- 数据集中包含了不同动作(如平移、旋转、复合运动等)、不同区域(如工业区、住宅区、海边等)、不同场景(如城市、乡村等)、不同任务(如导航、检测、跟踪等)以及不同环境条件(如白天、夜晚、下雪等)的样本,能够满足模型在各种情况下的训练和测试需求。
学习空中世界模型
模型目标
空中世界模型 A\mathcal{A}A 的目标是接收当前世界的状态,并预测如果空中智能体执行某个运动意图,未来的状态将会如何变化。具体来说:
- 当前状态:当前的第一人称视觉观察 Ot\mathcal{O}_tOt。
- 意图:空中智能体在六自由度空间中的轨迹、运动或目标,以高级文本形式表示 I\mathcal{I}I。
- 未来状态:具身视觉观察的顺序变化,以视频形式表示 O^t+1:t+K\hat{\mathcal{O}}_{t+1:t+K}O^t+1:t+K。
因此,模型的任务可以表示为:
O^t+1:t+K=A(Ot,I)\hat{\mathcal{O}}_{t+1:t+K} = \mathcal{A} (\mathcal{O}_t, \mathcal{I})O^t+1:t+K=A(Ot,I)
两阶段训练计划
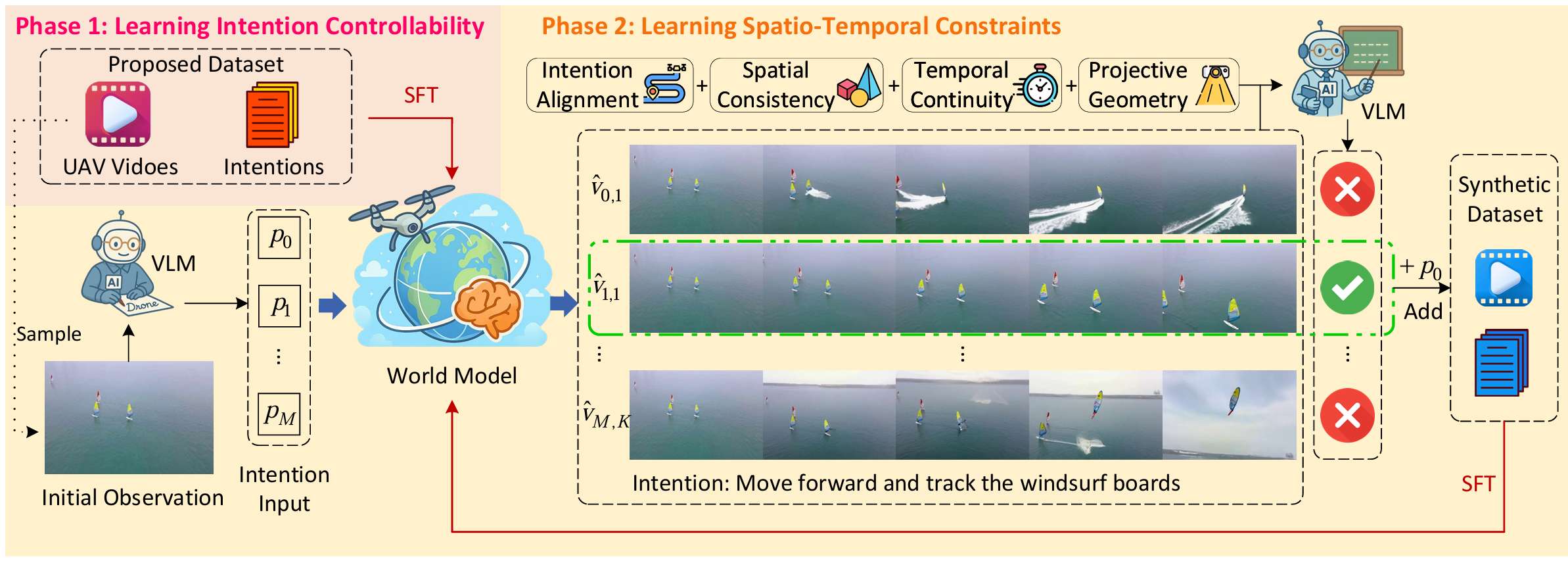
为了获得空中世界模型 A\mathcal{A}A,论文提出了两阶段训练计划,具体如下:
第一阶段:学习意图控制
- 目标:使视频生成基础模型能够根据当前观察和运动意图预测未来的序列观察。
- 方法:使用监督微调(Supervised Fine-Tuning, SFT)。
- 基础模型:利用预训练的视频生成基础模型,该模型原本习惯于接收详细描述视频内容的文本提示,主要用于将文本和图像生成视频,而不是作为预测和推理的世界模型。
- 训练数据:使用上一节提出的视频和文本意图对数据集 D={(Ot,I)}t=1TD = \{(\mathcal{O}_t, \mathcal{I})\}_{t=1}^TD={(Ot,I)}t=1T。
- 损失函数:最小化预测结果 O^t+1:t+K\hat{\mathcal{O}}_{t+1:t+K}O^t+1:t+K 和真实结果 Ot+1:t+K\mathcal{O}_{t+1:t+K}Ot+1:t+K 之间的重建损失:
Lfine-tune=1T∑t=1TLrecon(A(Ot,I),Ot+1:t+K) L_{\text{fine-tune}} = \frac{1}{T} \sum_{t=1}^T L_{\text{recon}}(\mathcal{A}(\mathcal{O}_t, \mathcal{I}), \mathcal{O}_{t+1:t+K}) Lfine-tune=T1t=1∑TLrecon(A(Ot,I),Ot+1:t+K)
其中,LreconL_{\text{recon}}Lrecon 是衡量两个视频相似性的重建损失。
第二阶段:学习时空约束
- 目标:进一步提升模型的预测质量,使其生成的视频在空间和时间上更加符合物理约束。
- 方法:引入自博弈(self-play)训练过程,生成合成数据对,并利用大模态模型(LMM)进行拒绝采样(rejection sampling)。
-
意图生成:从原始训练数据集中随机采样一个视频,并从中随机选择一帧作为当前观察 Ot\mathcal{O}_tOt。设计一个提示 ILMM\mathcal{I}_{\text{LMM}}ILMM,让LMM模仿训练数据集中的意图,并随机生成一个基础意图 I0\mathcal{I}_0I0。然后,LMM扩展基础意图,生成 M−1M-1M−1 个扩展意图 I1,I2,…,IM\mathcal{I}_1, \mathcal{I}_2, \dots, \mathcal{I}_MI1,I2,…,IM,从简洁到复杂。
-
视频生成:对于每个意图 Im\mathcal{I}_mIm 和条件观察 Ot\mathcal{O}_tOt,世界模型 A\mathcal{A}A 使用不同的随机种子 sms_msm 生成多个视频:
O^t+1:t+K(m,sm)=A(Ot,Im∣sm),m=0,…,M,sm=1,…,S \hat{\mathcal{O}}_{t+1:t+K}^{(m,s_m)} = \mathcal{A}(\mathcal{O}_t, \mathcal{I}_m | s_m), \quad m = 0, \dots, M, \quad s_m = 1, \dots, S O^t+1:t+K(m,sm)=A(Ot,Im∣sm),m=0,…,M,sm=1,…,S
这样就得到了一组候选视频 {O^t+1:t+K(m,sm)}\{\hat{\mathcal{O}}_{t+1:t+K}^{(m,s_m)}\}{O^t+1:t+K(m,sm)}。 -
拒绝采样:利用LMM评估生成视频是否符合时空约束。评估标准包括:(1)意图一致性:生成视频是否与指定意图的具身序列观察语义一致。(2)空间一致性:视频中物体的形状、位置和结构是否符合物理规律,场景中元素的空间关系是否符合常识。(3)时间连贯性:物体状态随时间连续变化,无突变或不连续。(4)投影几何:具身序列观察必须满足透视、视差效应、大小深度关系等,符合三维空间的物理和光学属性。
通过比较LMM的输出评分,选择与基础意图 I0\mathcal{I}_0I0 一致且满足时空约束的视频:
O∗=argmaxO^t+1:t+K(m,sm)LMM(O^t+1:t+K(m,sm),I0∣ILLM) \mathcal{O}^* = \arg\max_{\hat{\mathcal{O}}_{t+1:t+K}^{(m,s_m)}} \text{LMM}(\hat{\mathcal{O}}_{t+1:t+K}^{(m,s_m)}, \mathcal{I}_0 | \mathcal{I}_{\text{LLM}}) O∗=argO^t+1:t+K(m,sm)maxLMM(O^t+1:t+K(m,sm),I0∣ILLM) -
合成数据收集:将选定的视频 O∗\mathcal{O}^*O∗ 和其对应的基础意图提示 I0\mathcal{I}_0I0 组合成合成数据对 (O∗,I0)(\mathcal{O}^*, \mathcal{I}_0)(O∗,I0),并将其添加到合成数据集 DsyntheticD_{\text{synthetic}}Dsynthetic 中。
-
监督微调:当合成数据集 DsyntheticD_{\text{synthetic}}Dsynthetic 的大小达到预定义的阈值时,使用它进一步训练世界模型 A\mathcal{A}A。训练目标与第一阶段的微调相似,即最小化重建损失:
Lself-play=1∣Dsynthetic∣∑(O,I)∈DsyntheticLrecon(A(O,I),O) L_{\text{self-play}} = \frac{1}{|D_{\text{synthetic}}|} \sum_{(\mathcal{O}, \mathcal{I}) \in D_{\text{synthetic}}} L_{\text{recon}}(\mathcal{A}(\mathcal{O}, \mathcal{I}), \mathcal{O}) Lself-play=∣Dsynthetic∣1(O,I)∈Dsynthetic∑Lrecon(A(O,I),O) -
迭代优化:重复自博弈过程,每次训练后使用更新的模型 A\mathcal{A}A 生成新的合成数据集 DsyntheticD_{\text{synthetic}}Dsynthetic,通过迭代优化提升模型生成高质量视频的能力。
-
实验
实验设置
- 数据集划分:将提出的11k视频数据集按照9:1的比例划分为训练集和测试集。
- 基础模型:使用CogVideoX-i2v-5B作为视频生成基础模型。主要训练参数设置如下:
- 视频分辨率:49×480×720(帧数×高度×宽度)
- 批量大小:2
- 梯度累积步数:8
- 训练周期:10个epoch
- 训练硬件:8块NVIDIA A800-SXM4-40GB GPU
- 第二阶段训练:在第二阶段训练中,使用Gemini-2.0-Flash作为大模态模型(LMM),因其在视频理解方面表现出色且响应速度快。

指标
- 自动评估:
- FID(Fréchet Inception Distance):用于衡量生成视频与真实视频在帧级别的分布差异。评估时,将预测帧裁剪并调整大小以匹配真实视频的分辨率。
- FVD(Fréchet Video Distance):用于评估生成视频与真实视频在时间维度上的分布差异。评估时,所有生成视频和真实视频被统一降采样到相同的帧数。
- 人工评估:
- 意图对齐率(IAR, Intention Alignment Rate):评估生成视频与输入意图的语义一致性。通过人工判断生成视频与输入意图是否语义对齐(二元选择),并计算整个测试集上的平均意图对齐率。每种方法大约有1.1k个生成视频被评估,这些视频随机且均匀地分配给9名参与者进行评分。
定量结果

- AirScape的整体性能最佳:与最先进方法相比,AirScape在大多数评估指标上表现最佳,平均FID、FVD和IAR指标分别提高了14.91%、14.63%和165.64%。特别是在需要高度遵循物理规律的旋转动作组中,AirScape的性能提升尤为显著。
- 基线方法性能不稳定:例如,HunyuanVideo-I2V在复合动作组的FVD指标上表现最佳,但在同一组的FID指标上表现最差。这表明不同方法在不同指标之间存在一定的权衡,有些方法可能通过牺牲某些指标来在某一指标上取得极高性能,但这对实际应用意义不大。相比之下,AirScape的性能更加稳定,进一步验证了其设计的有效性。
- 模型参数规模与性能无直接关联:实验结果表明,模型参数规模与性能之间并无直接联系。这说明通过精心收集的数据集和训练技术,可以进一步提升模型能力。
自博弈训练的效果

- 方法验证:为了验证自博弈训练的效果,论文从视频数据集中随机抽取一帧作为初始观察,并让LMM随机生成一个合理的意图提示。通过同义词扩展提示和改变随机种子,使世界模型的输出多样化。通过增加每次输入的生成次数,确保至少有一个视频样本具有良好的预测质量。
- LMM的评估作用:LMM作为评估器,根据时空约束对每个视频进行评估。例如,上图中第二行的视频在后期丢失了船队,违反了意图目标;第三行的船队发生了不自然的扭曲,破坏了空间一致性;第四行突然出现了一座山,破坏了时间连贯性。而第一行的视频在示例中获得了最高评分。
结论与未来工作
- 结论:
- AirScape作为首个空中世界模型,能够根据运动意图预测未来具身的观察序列,并通过构建的11k视频数据集和两阶段训练计划,学习意图控制并增强预测的时空一致性,在实验中展现出优越的性能,为无人机等空中智能体的空间智能和任务规划提供了有力支持。
- 未来工作:
- 计划将世界模型与现实中的具身智能体相结合,进一步测试其性能,以实现更广泛的实际应用。


















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









