






论文:On Layer Normalization in the Transformer Architecture
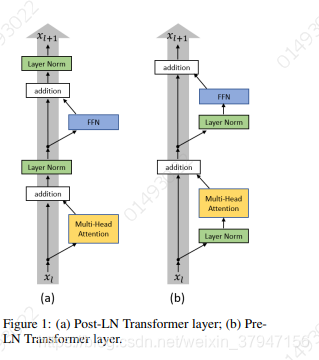
推荐说明:我们知道,在原始的Transformer中,Layer Norm在跟在Residual之后的,我们把这个称为Post-LN Transformer;而且用Transformer调过参的同学也知道,Post-LN Transformer对参数非常敏感,需要很仔细地调参才能取得好的结果,比如必备的warm-up学习率策略,这会非常耗时间。
所以现在问题来了,为什么warm-up是必须的?能不能把它去掉?本文的出发点是:既然warm-up是训练的初始阶段使用的,那肯定是训练的初始阶段优化有问题,包括模型的初始化。从而,作者发现,Post-LN Transformer在训练的初始阶段,输出层附近的期望梯度非常大,所以,如果没有warm-up,模型优化过程就会炸裂,非常不稳定。既然如此,本文作者尝试把Layer Norm换个位置,比如放在Residual的过程之中(称为Pre-LN Transformer),再观察训练初始阶段的梯度变化,发现比Post-LN Transformer不知道好到哪里去了,甚至不需要warm-up,从而进一步减少训练时间,这一结果的确令人震惊。
推荐理由:本文别出心裁,用实验和理论验证了Pre-LN Transformer结构不需要使用warm-up的可能性,其根源是LN层的位置导致层次梯度范数的增长,进而导致了Post-LN Transformer训练的不稳定性。本文第一次将warm-up、LayerNorm、gradient和initialization联系起来,非常值得一读!
推荐:
1、Transformers without Tears: Improving the Normalization of Self-Attention
2、Transformer中warm-up和LayerNorm的重要性探究

















 4138
4138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









