




 本文介绍了如何使用Python爬取Airbnb的房源信息。首先,从本地读取城市id和query信息,构建查询连接。接着,解析页面JSON数据,找到“listings”获取房源详情。对于翻页,通过分析请求头中的'items_offset'参数实现。最后,爬取并下载房源图片,整个过程在设置合理请求间隔后能有效避免被屏蔽。
本文介绍了如何使用Python爬取Airbnb的房源信息。首先,从本地读取城市id和query信息,构建查询连接。接着,解析页面JSON数据,找到“listings”获取房源详情。对于翻页,通过分析请求头中的'items_offset'参数实现。最后,爬取并下载房源图片,整个过程在设置合理请求间隔后能有效避免被屏蔽。
上次说到获得了城市的id和query信息,存储在本地文本或数据库中,今天要做的就是利用这些信息构建查询连接爬房源信息了。
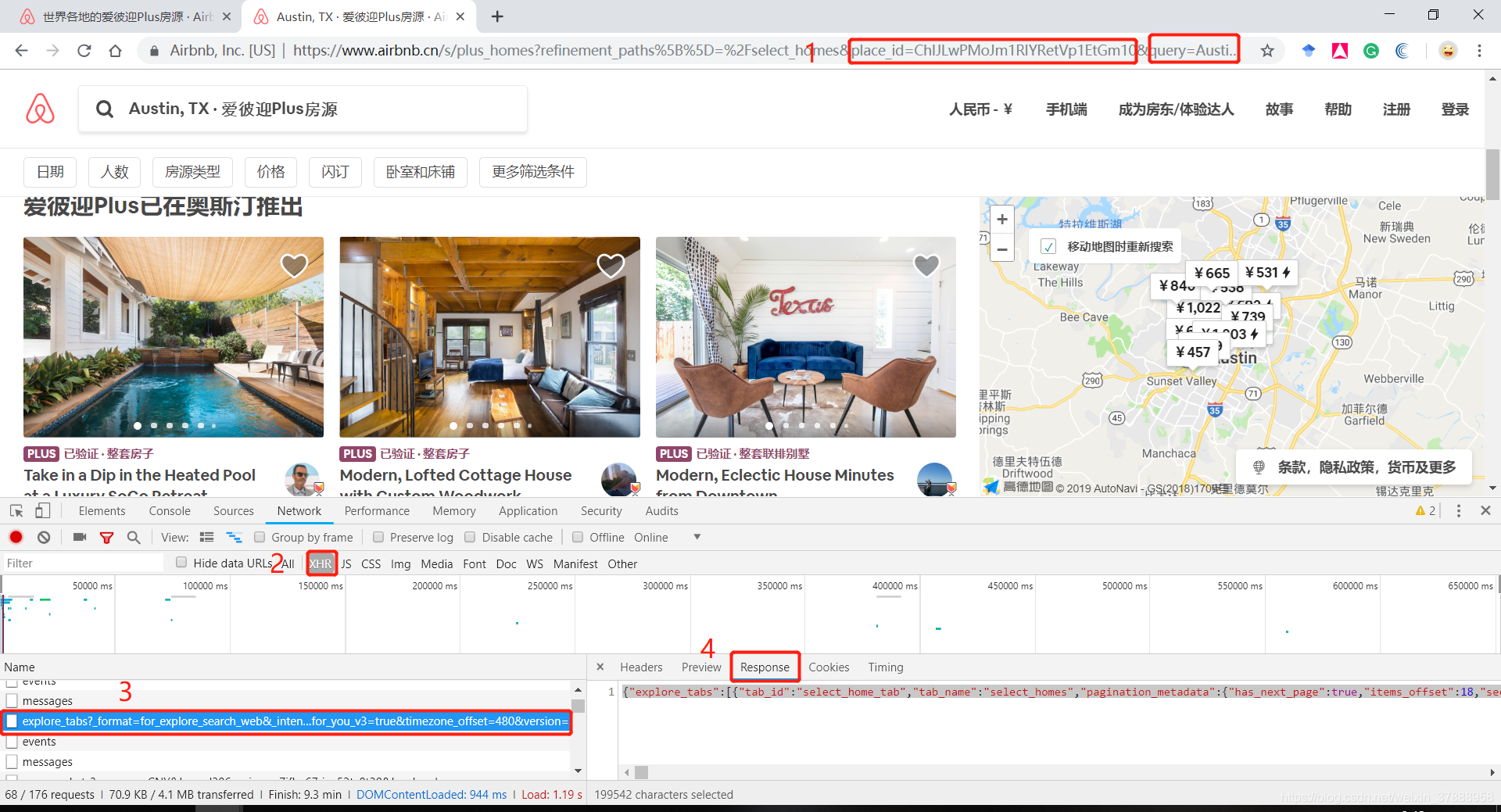
依旧是熟悉的配方,打开链接和辅助工具,找到网页返回数据的链接和json数据:
关于链接格式的分析昨天已经说过了,今天只要从本地读取参数和固定的url部分组合起来逐一请求即可。
url = 'https://www.airbnb.cn/s/plus_homes?refinement_paths%5B%5D=%2Fselect_homes&place_id={0}&query={1}%2C%20TX&allow_override%5B%5D=&s_tag=qfMYb0sz'.format(place_id, query)
接下就是对房源的分析~
把上图4位置里的数据搞出来,粘贴到 json.com 里格式化,方便阅读,很快可以找到房间所在数据组织层级,"listings"里面就是本页全部的房源信息,然后就可以根据自己的需求进行爬取啦!

关于翻页:以上操作仅是针对本页信息,那么一个城市他不会只有一页房源的,其他的房间怎么翻页获取呢?这时候就要回头看第一张图了。
先在原始网页上进行操作,翻到下一页,使用辅助工具过滤器找到这两页的数据,查看他们的请求头信息 比较这两次请求的参数,可以发现其中多出了 ‘items_offset’ 参数。第一页是没有这个参数的,第二页增加了这个参数且数值为18,如果不放心可以继续翻页再看下一页,应为36。
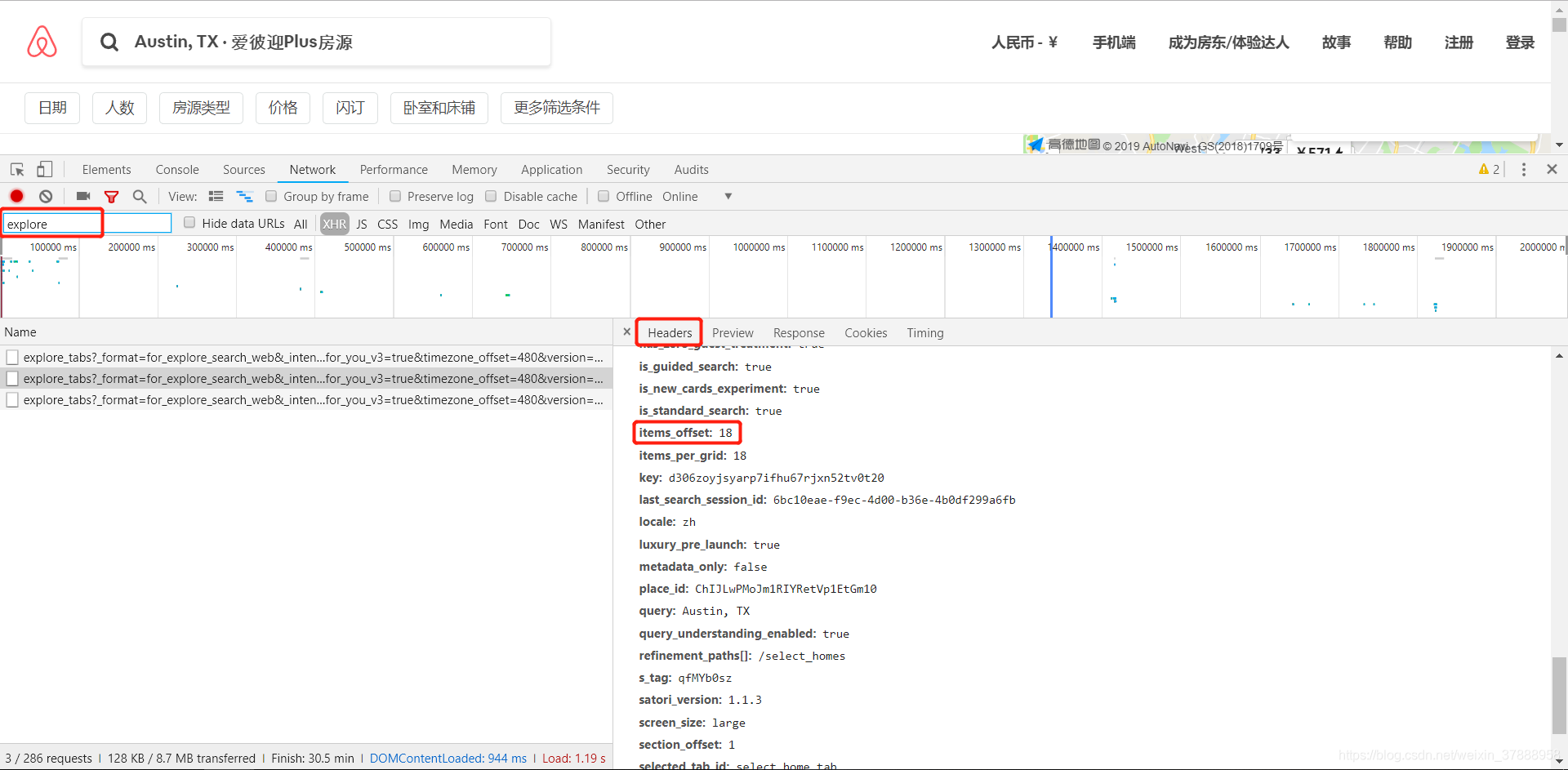
所以!需要翻页的话只需要在原始网页的链接后面加上这个参数并设定数值就OK了。虽然是去年的代码应该不能直接用了,还是先贴出来好了
如果只要基本信息的话,其实这个页面已经足够了,不过我们当时主要是想要爬取这些图片,就需要进入到具体的房源信息页,操作也是差不多,观察具体信息页的链接结构,在本页获取房源id等信息组成队列,然后依次组合连接进行请求,进入具体页面后找到返回的数据链接获得图片路径,存储到队列后依次下载就行。
Airbnb的网站请求只要设置合理的睡眠时间基本不会被屏蔽,不过就是图片的下载速度比较慢,当时好像是有个几千个房源几万张原图,没日没夜下了一周,接近60G的数据。
import requests
import json
import re
import os
from lxml import etree
import random
import time
HEADERS = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
URL = "https://zh.airbnb.com/api/v2/explore_tabs?version=1.3.5&_format=for_explore_search_web\
&auto_ib=true&timezone_offset=480&refinement_paths%5B%5D=%2Fselect_homes&selected_tab_id=select_home_tab\
&allow_override%5B%5D=&key=d306zoyjsyarp7ifhu67rjxn52tv0t20¤cy=CNY&locale=zh"
QUERY = 'London'
PLACE_ID = 'ChIJdd4hrwug2EcRmSrV3Vo6llI'
def get_num_loc(query , place_id):
url = URL + "&query={0}&place_id={1}§ion_offset=0".format(query , place_id )#单网页测试√
#print(url)
e_t = requests.get( url , headers = HEADERS).json().get('explore_tabs')[0]
place = []
for item in e_t.get('home_tab_metadata').get('breadcrumbs') :
place.append(item.get('location_name'))
loc = '-'.join(place)#按照国家、区、城市确定位置信息
#print(palce)
h_num = e_t.get('home_tab_metadata').get('listings_count')#总计房源数量
#print(h_num)
city_list = [query , place_id]
print(city_list)
if not os.path.exists('airbnb'):
os.mkdir('airbnb')
with open('airbnb/city_list.txt' , 'a' , encoding = 'utf-8') as f :
for i in city_list:
f.write( str(i) + '\t')
f.write('\n')
def get_city_list():
response = requests.get(URL , headers = HEADERS)
j = response.json()
#print(j)
airp_cities = j.get('explore_tabs')[0].get('sections')[1].get('contextual_searches')
for item in airp_cities:
search_params = item.get('search_params')
yield{
'place_id' : search_params.get('place_id'),
'query' : search_params.get('query'),
}
#---------------------*************---------------------#第一步:搜集城市列表以及每个城市的民俗个数
def get_page_json(query , place_id ,offset = 0 ):#
url = URL + "&query={0}&place_id={1}§ion_offset={2}".format(query , place_id , offset)#单网页测试√
#print(url)
time.sleep(random.randint(2 , 5 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 342
342






 到【灌水乐园】发言
到【灌水乐园】发言







