




 本文介绍了使用pandas进行数据分析的项目,通过Kaggle上的星巴克店铺数据,探讨了全球及中国星巴克店铺的分布情况,包括处理缺失值、异常值,以及通过可视化展示各国和各城市店铺数量。
本文介绍了使用pandas进行数据分析的项目,通过Kaggle上的星巴克店铺数据,探讨了全球及中国星巴克店铺的分布情况,包括处理缺失值、异常值,以及通过可视化展示各国和各城市店铺数量。
【Python有趣打卡】数据分析pandas完成数据分析项目

今天依然是跟着罗罗攀学习数据分析,原创:罗罗攀(公众号:luoluopan1)学习Python有趣|数据分析三板斧。今天是在DD大数据团队实习的第一天,正式开始数据分析之旅,很开心,感觉离自己的梦想又进了一步~
数据源
- 数据来源
https://www.kaggle.com/starbucks/store-locations (数据下载需要注册) - 定义问题
哪些国家星巴克店铺较多;哪些城市星巴克店铺较多;中国星巴克店铺分布情况 - 读取数据
import numpy as np
import pandas as pd
data = pd.read_csv(r'C:\Users\xuxiaojielucky_i\Desktop\directory.csv')
data.head()
还是使用jupyter notebook
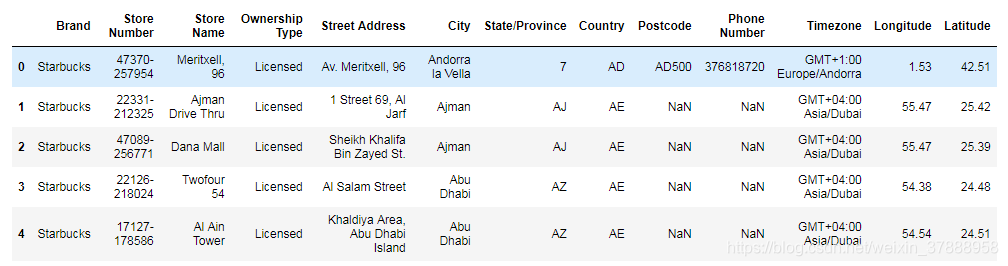
查看数据
- 检查数据
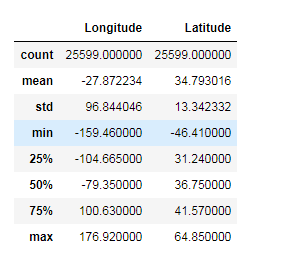
data.describe()
describe函数主要是用来了解数值型数据的分布和概况
data.info()
info函数主要是用来查看数据的缺失值情况,如针对我们的问题,我们关注的数据主要是地点(国家和城市),这里城市city部分数据缺失。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









