







前言
当创建好一个机器学习模型之后,我们需要评估这个模型的性能好坏,以确定模型是否可用,在sklearn中的metrics模块提供了各种模型评估方法。
对分类模型和回归模型,我们需要使用不同的方法对模型进行评估。
1、分类模型评估
对于分类模型,主要有以下几种评估指标:
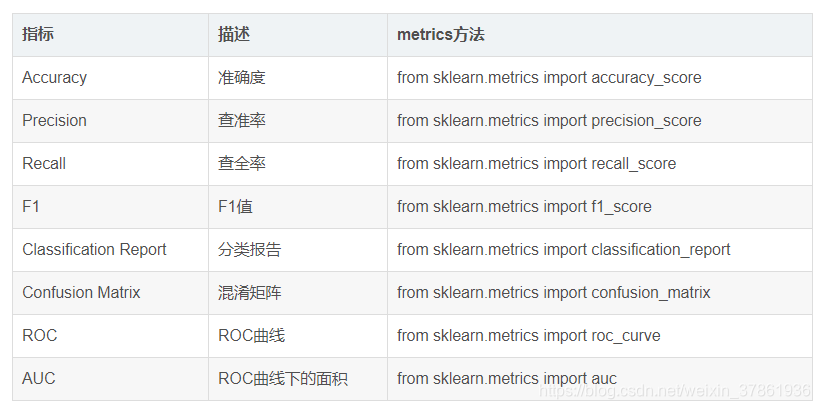
- 准确率(accuracy)
正确分类的样本数占所有样本数的比例
a c c u r a c y = n c o r r e c t n t o t a l accuracy=\frac{n_{correct}}{n_{total}} accuracy=ntotalncorrect
n c o r r e c t n_{correct} ncorrect:被正确分类的样本个数
n t o t a l n_{total} ntotal:总样本的个数
准确率的局限性:
准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷,当不同种类的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。比如:当负样本占99%,分类器把所有样本都预测为负样本也可以得到99%的准确率,换句话说总体准确率高,并不代表类别比例小的准确率高。
代码展示:
from sklearn.metrics import accuracy_score
y_true = [0, 1, 1, 1, 1]
y_pred = [0, 0, 1, 1, 1]
accuracy_score(y_true=y_true,y_pred=y_pred)
运行结果为:0.8
- 查准率(precision)和查全率(recall)
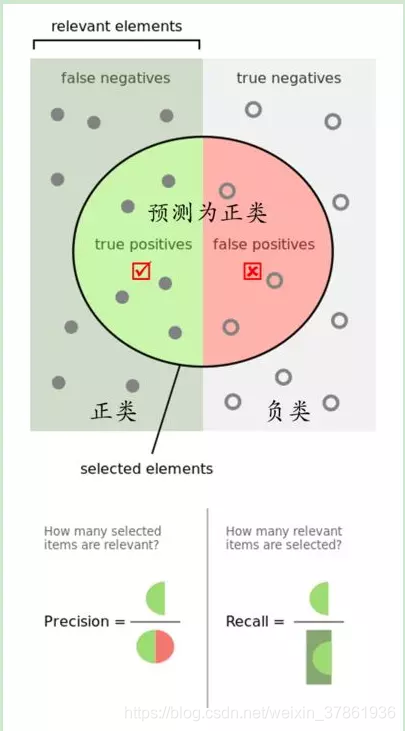
图片来源于:https://www.jianshu.com/p/4434ea11c16c
查准率是指正确分类的正样本个数占分类器判定为正样本的样本个数的比例
p r e c i s o n = T P T P + F P precison=\frac{TP}{TP+FP} precison=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









