






阅读mmdetection的时候,发现了一些图像训练的技巧,可以参考原文地址获取原文。翻译如下文,其中很多原文连接,可以从原文看到。
训练技巧
1.多尺度训练
(注:请额外注意mosaic方法)
在目标检测领域,多尺度训练(Multi-scale training)是一种常见的技巧,它通过在不同尺度的图像上训练模型,增强模型对不同大小目标的检测能力。然而,在YOLO系列模型中,大多数版本通常使用640×640的单一尺度输入进行训练,原因主要有以下两点:
单一尺度训练比多尺度训练更快。当训练周期为300或500时,训练效率是用户非常关心的问题。多尺度训练会降低训练速度。
多尺度增强已经隐含在训练流程中。例如Mosaic、RandomAffin和Resize等数据增强方法,这些方法在一定程度上相当于多尺度训练的效果,因此无需再引入模型输入的多尺度训练。
通过在COCO数据集上的实验发现,如果直接在YOLOv5的DataLoader输出后引入多尺度训练,实际性能提升非常有限。如果你希望在MMYOLO中为YOLO系列算法启用多尺度训练,可以参考ms_training_testing模块,但这并不意味着在用户自定义数据集的微调模式下没有显著的性能提升。
2.使用掩码注释优化目标检测性能
(注:这里是不是说把目标检测和分割同时做?原生yolo好像不支持吧?)
当数据集的注释是完整的,例如边界框注释和实例分割注释同时存在,但任务只需要其中一部分注释时,可以使用完整的数据注释来训练任务以提高性能。在目标检测中,我们也可以从实例分割注释中学习,以提高目标检测的性能。以下是YOLOv8引入的额外实例分割注释优化的检测结果。性能提升如下所示: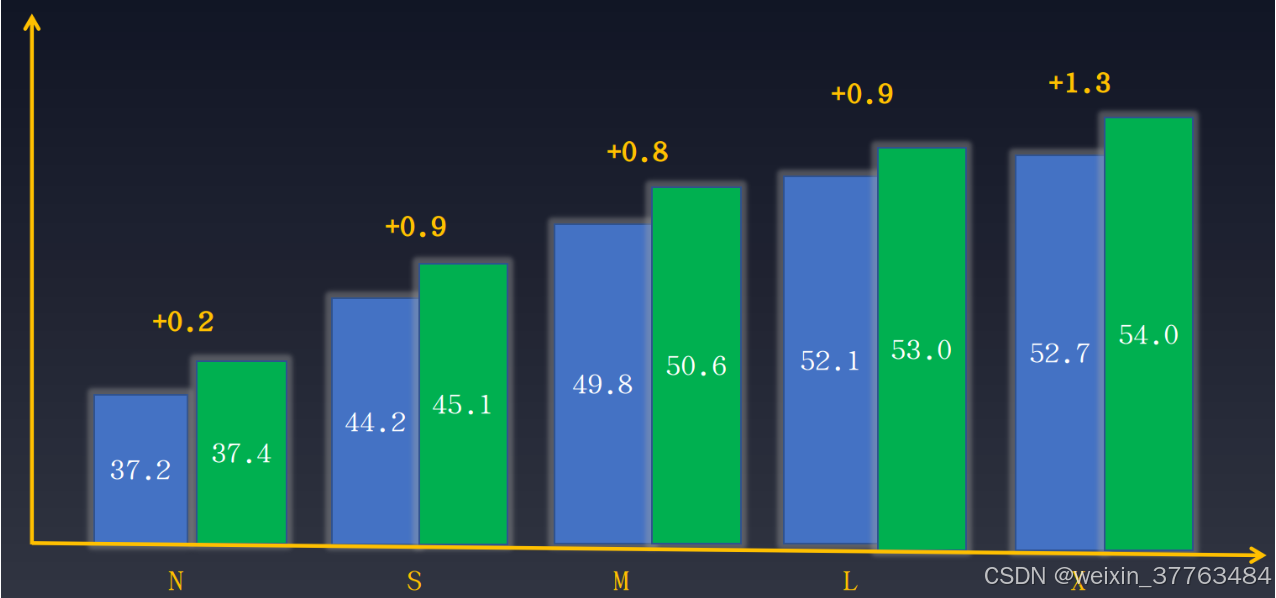
如图所示,不同尺度的模型在性能提升上有不同程度的表现。需要注意的是,“掩码精炼”(Mask Refine)仅在数据增强阶段发挥作用,无需对模型的其他训练部分进行任何更改,也不会影响训练速度。具体细节如下:
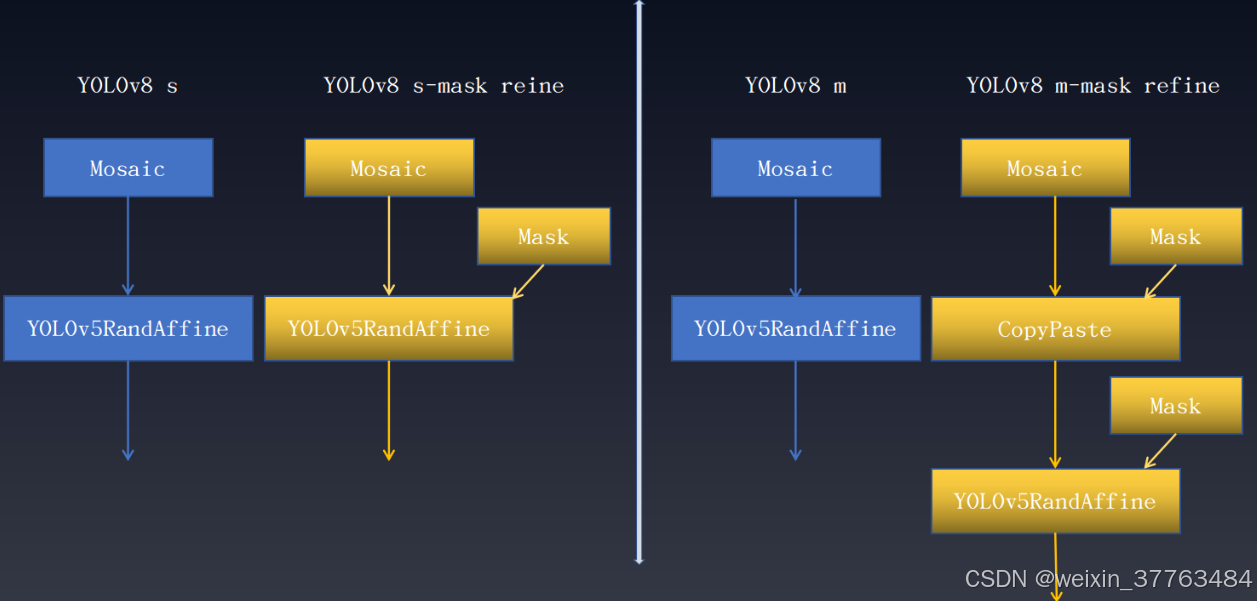
上述提到的掩码(Mask)代表一种数据增强变换,其中实例分割注释起着关键作用。将这种技术应用于其他YOLO系列模型时,会带来不同程度的性能提升。
3 关闭训练后期的强数据增强以提升检测性能
这种策略首次由YOLOX算法提出,可以显著提升检测性能。YOLOX的论文指出,Mosaic和MixUp等数据增强技术能够极大地提高目标检测性能,但训练图像与自然图像的真实分布相差甚远,且Mosaic的大量裁剪操作会引入许多不准确的标签框。因此,YOLOX提出在最后15个训练周期中关闭强增强,改用较弱的增强方式,从而使检测器能够避免不准确标签框的影响,并在自然图像的数据分布下完成最终收敛。
这种策略已被应用于大多数YOLO算法。以YOLOv8为例,其数据增强流程如下:
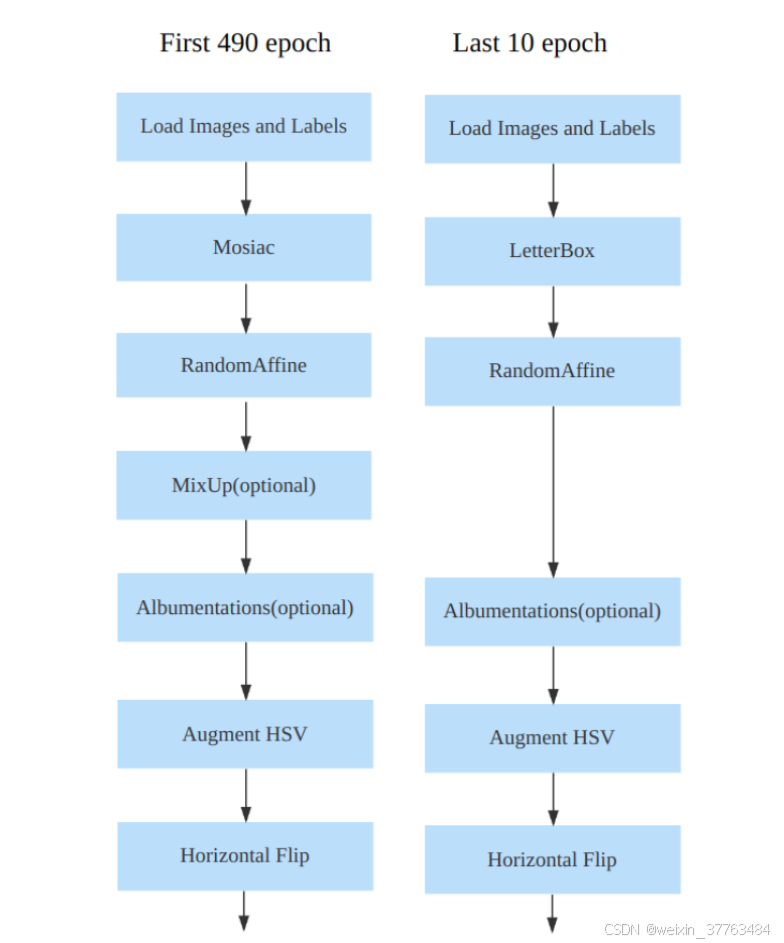
然而,何时关闭强数据增强是一个超参数。如果关闭强数据增强的时间过早,可能无法充分发挥Mosaic等强增强技术的效果;如果关闭强增强的时间过晚,则可能毫无收益,因为模型可能已经出现过拟合。这种现象可以在YOLOv8的实验中观察到。
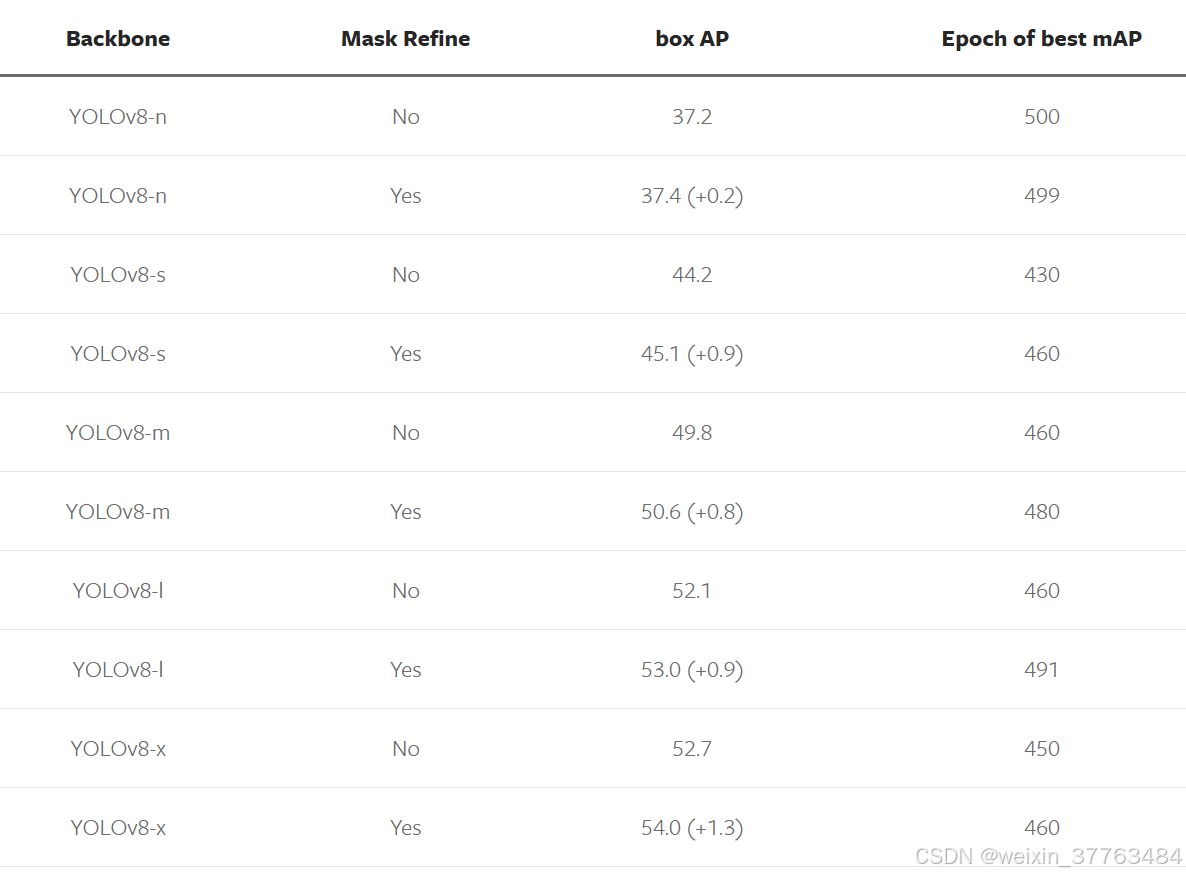
如上表所示:
在COCO数据集上训练500个周期的大模型容易出现过拟合,而在这种情况下,禁用Mosaic等强增强可能无法有效减少过拟合。
使用掩码注释可以缓解过拟合并提升性能。
4.添加纯背景图像以抑制误检
在目标检测中,对于非开放世界数据集,训练和测试都在固定类别集上进行,当应用于未训练过的类别图像时,可能会产生误检(false positives)。一种常见的缓解策略是添加一定比例的纯背景图像。在大多数YOLO系列中,通过添加纯背景图像来抑制误检的功能默认启用。用户只需将train_dataloader.dataset.filter_cfg.filter_empty_gt设置为False,表示在训练期间不应过滤掉纯背景图像。
5.也许AdamW会带来惊喜
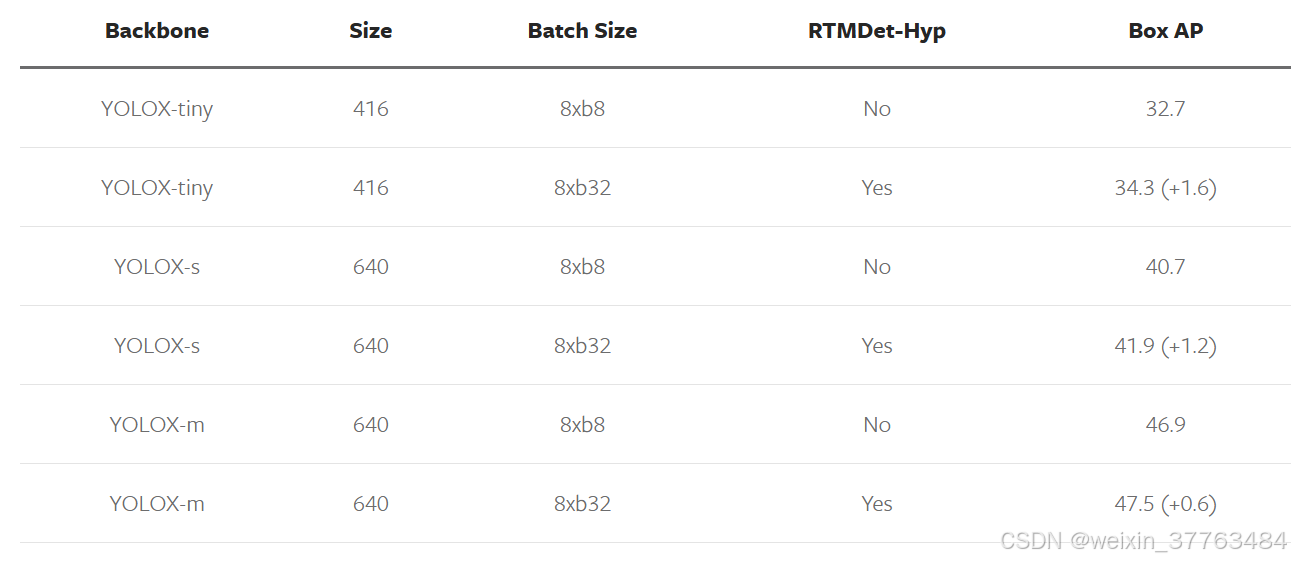
YOLOv5、YOLOv6、YOLOv7和YOLOv8都采用了SGD优化器,这种优化器对参数设置要求严格,而AdamW则相反,它对学习率不那么敏感。如果用户在自定义数据集上进行微调,可以尝试选择AdamW优化器。我们在YOLOX上做了一个简单的试验,发现将优化器替换为AdamW后,tiny、s和m尺度模型的性能都有所提升。
6.考虑忽略场景以避免不确定的注释
以CrowdHuman为例,这是一个拥挤行人检测数据集。这里有一张典型的图像:

这张图片来源于Detectron2的讨论问题。图中用黄色叉号标记的区域表示“iscrowd”标签。设置这一标签的原因有两个:
- 该区域并非真实的人,例如海报上的人像。
- 该区域过于拥挤,难以进行标注。
在这种情况下,你不能简单地删除这些标注,因为一旦删除,就意味着在训练过程中将这些区域视为背景。然而,它们与背景是不同的。首先,海报上的人像与真实的人非常相似,而拥挤区域中确实存在难以标注的人。如果简单地将它们作为背景进行训练,会导致漏检(false negatives)。最好的方法是将拥挤区域视为一个忽略区域,该区域内的任何输出都会被直接忽略,不计算损失,也不强制模型进行拟合。
MMYOLO在YOLOv5上快速且轻松地验证了“iscrowd”标注的功能。其性能表现如下:

将 ignore_iof_thr 设置为 -1 表示忽略标签不被考虑,可以看到性能在一定程度上得到了提升,更多细节可以在 CrowdHuman 的结果中找到。如果你在自定义数据集中遇到类似情况,建议考虑使用忽略标签来避免不确定的注释。
7.使用知识蒸馏
知识蒸馏是一种广泛使用的技术,可以将大模型的性能迁移到较小的模型上,从而提升小模型的检测性能。目前,MMYOLO和MMRazor已经支持这一功能,并在RTMDet上进行了初步验证。
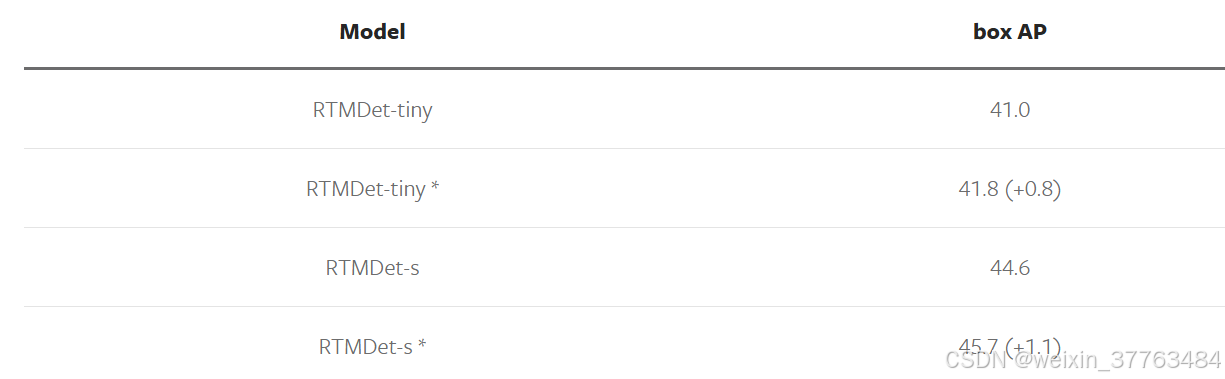
表示使用了大模型蒸馏的结果,更多细节可以在 Distill RTMDet 中找到。
8.更大的模型使用更强的数据增强参数
如果你基于默认配置修改了模型,或者替换了主干网络,建议根据当前模型的大小调整数据增强参数。一般来说,更大的模型需要更强的数据增强参数,否则可能无法充分发挥大模型的优势。相反,如果对小模型应用过强的数据增强,可能会导致欠拟合。以 RTMDet 为例,我们可以观察到不同模型大小的数据增强参数。

random_resize_ratio_range 表示 RandomResize 的随机缩放范围,而 mosaic_max_cached_images 和 mixup_max_cached_images 分别表示在 Mosaic 和 MixUp 数据增强过程中缓存的图像数量。这些参数可用于调整增强的强度。YOLO 系列模型都遵循相同的参数设置原则。
加速训练技巧
1.在单尺度训练中启用 cudnn_benchmark
YOLO 系列算法的输入图像尺寸大多是固定的,属于单尺度训练。在这种情况下,可以启用 cudnn_benchmark 来加速训练速度。这个参数主要是针对 PyTorch 的 cuDNN 底层库设置的,启用该标志可以让内置的 cuDNN 自动寻找最适合当前配置的最高效算法,从而优化运行效率。如果在多尺度模式下启用这个标志,它会不断搜索最优算法,反而可能会降低训练速度。
在 MMYOLO 中启用 cudnn_benchmark,可以在配置文件中设置 env_cfg = dict(cudnn_benchmark=True)。
2.使用带缓存的 Mosaic 和 MixUp
如果你在数据增强中应用了 Mosaic 和 MixUp,并且在调查训练瓶颈后发现随机图像读取是问题所在,那么建议用 RTMDet 提出的带缓存版本替换普通的 Mosaic 和 MixUp。
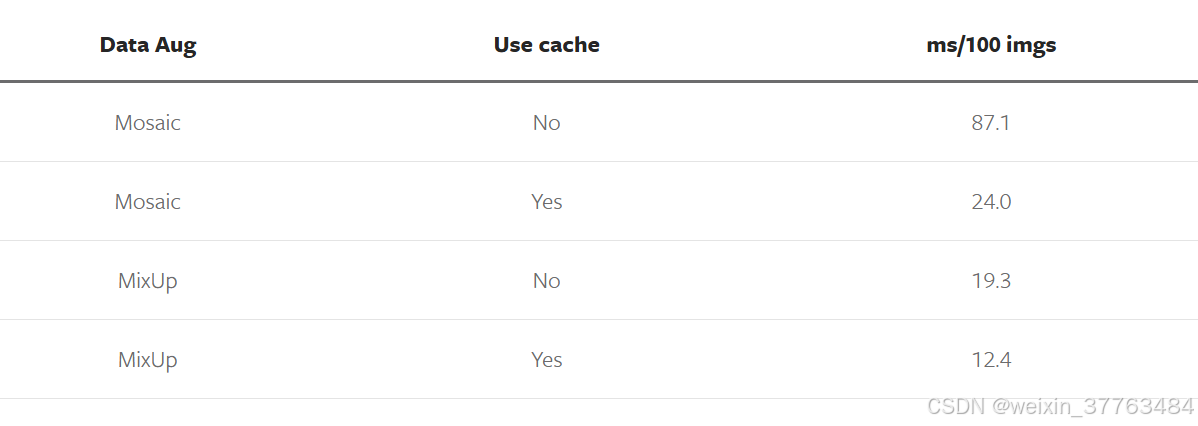
Mosaic 和 MixUp 涉及多张图像的混合,其时间消耗是普通数据增强的 K 倍(K 是混合图像的数量)。例如,在 YOLOv5 中,每次进行 Mosaic 时,都需要从硬盘重新加载 4 张图像的信息。然而,带缓存的 Mosaic 和 MixUp 版本只需要重新加载当前图像,而参与混合增强的其余图像则从缓存队列中获取,通过牺牲一定的内存空间,极大地提高了效率。
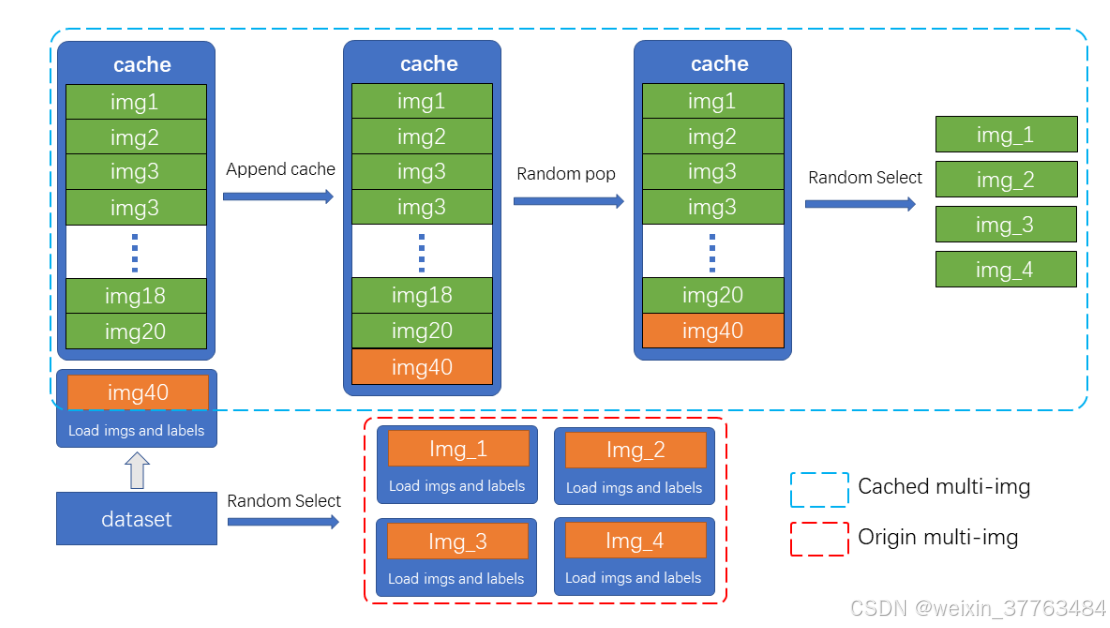
如图所示,N张预加载的图像及其标签数据被存储在缓存队列中。在每个训练步骤中,只需要加载并更新缓存队列中的一张新图像及其标签数据。(缓存队列中的图像可以重复,如图中img3出现了两次。)如果缓存队列的长度超过了预设长度,就会随机弹出一张图像。当需要进行混合数据增强时,只需要从缓存中随机选择所需的图像进行拼接或其他处理,而无需从硬盘加载所有图像,从而节省了图像加载时间。
YOLOv5 提供了一些减少超参数数量的实用方法,具体如下所述:
3.自适应损失权重调整,减少一个超参数
通常,为不同任务或类别专门设置超参数可能是一个挑战。YOLOv5 提出了一些基于类别数量和检测输出层数的自适应方法,用于调整损失权重。这些方法是基于实践经验提出的,如下所示:
# scaled based on number of detection layers
loss_cls=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=loss_cls_weight *
(num_classes / 80 * 3 / num_det_layers)),
loss_bbox=dict(
type='IoULoss',
iou_mode='ciou',
bbox_format='xywh',
eps=1e-7,
reduction='mean',
loss_weight=loss_bbox_weight * (3 / num_det_layer
return_iou=True),
loss_obj=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=loss_obj_weight *
((img_scale[0] / 640)**2 * 3 / num_det_layers)),
loss_cls可以根据自定义的类别数量和检测层数自适应调整loss_weight,loss_bbox可以根据检测层数自适应计算,loss_obj可以根据输入图像尺寸和检测层数自适应调整。这种策略允许用户避免设置损失权重超参数。需要注意的是,这只是一个经验原则,并不一定是最佳的设置组合,仅供参考。
4. 基于批量大小的自适应权重衰减和损失输出值,减少两个超参数
通常,在使用不同批量大小训练时,需要遵循自动学习率缩放的规则。然而,在多个数据集上的验证表明,YOLOv5在改变批量大小时即使不调整学习率也能取得良好的结果,有时调整学习率甚至会导致更差的结果。原因在于YOLOv5代码中基于批量大小调整的权重衰减和损失输出值的技术。在YOLOv5中,权重衰减和损失输出值会根据正在训练的总批量大小进行缩放。对应的代码如下:
# https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/engine/optimizers/yolov5_optim_constructor.py#L86
if 'batch_size_per_gpu' in optimizer_cfg:
batch_size_per_gpu = optimizer_cfg.pop('batch_size_per_gpu')
# No scaling if total_batch_size is less than
# base_total_batch_size, otherwise linear scaling.
total_batch_size = get_world_size() * batch_size_per_gpu
accumulate = max(
round(self.base_total_batch_size / total_batch_size), 1)
scale_factor = total_batch_size * \
accumulate / self.base_total_batch_size
if scale_factor != 1:
weight_decay *= scale_factor
print_log(f'Scaled weight_decay to {weight_decay}', 'current')
# https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/models/dense_heads/yolov5_head.py#L635
_, world_size = get_dist_info()
return dict(
loss_cls=loss_cls * batch_size * world_size,
loss_obj=loss_obj * batch_size * world_size,
loss_bbox=loss_box * batch_size * world_size)
不同批量大小下的损失权重会有所不同,通常,较大的批量大小意味着较大的损失和梯度。我个人推测,这可以等同于批量大小增加时线性增加学习率的情形。实际上,从YOLOv5的研究中可以看到:mAP与YOLOv5批量大小的关系表明,用户在修改批量大小时,能够在不修改其他参数的情况下实现类似的性能,这是非常理想的。上述两种策略是非常好的训练技巧。
5.节省GPU内存
如何减少训练内存使用是一个经常被讨论的问题,涉及到许多技术。MMYOLO的训练执行器来自MMEngine,因此你可以参考MMEngine的文档,了解如何减少训练内存使用。目前,MMEngine支持梯度累积、梯度检查点和大模型训练技术,具体细节可以在“SAVE MEMORY ON GPU”中找到。
测试技巧
在模型性能测试中,我们通常追求更高的 mAP,但在实际应用或推理中,我们希望模型在保持低误检率和漏检率的同时运行得更快。换句话说,测试时只关注 mAP,而忽略了后处理和评估速度,而在实际应用中,追求的是速度和精度之间的平衡。在 YOLO 系列中,可以通过控制某些参数来实现速度和精度之间的平衡。在本例中,我们将以 YOLOv5 为例详细说明。
1.避免在推理过程中对单个检测框输出多个类别
YOLOv5 在分类分支的训练中使用了 BCE Loss(use_sigmoid=True)。假设存在 4 个目标类别,分类分支输出的类别数是 4 而不是 5。此外,由于使用了 sigmoid 而不是 softmax 进行预测,可能会在某个位置预测出多个满足过滤阈值的检测框,这意味着一个预测的边界框可能对应多个预测的标签。如下图所示:
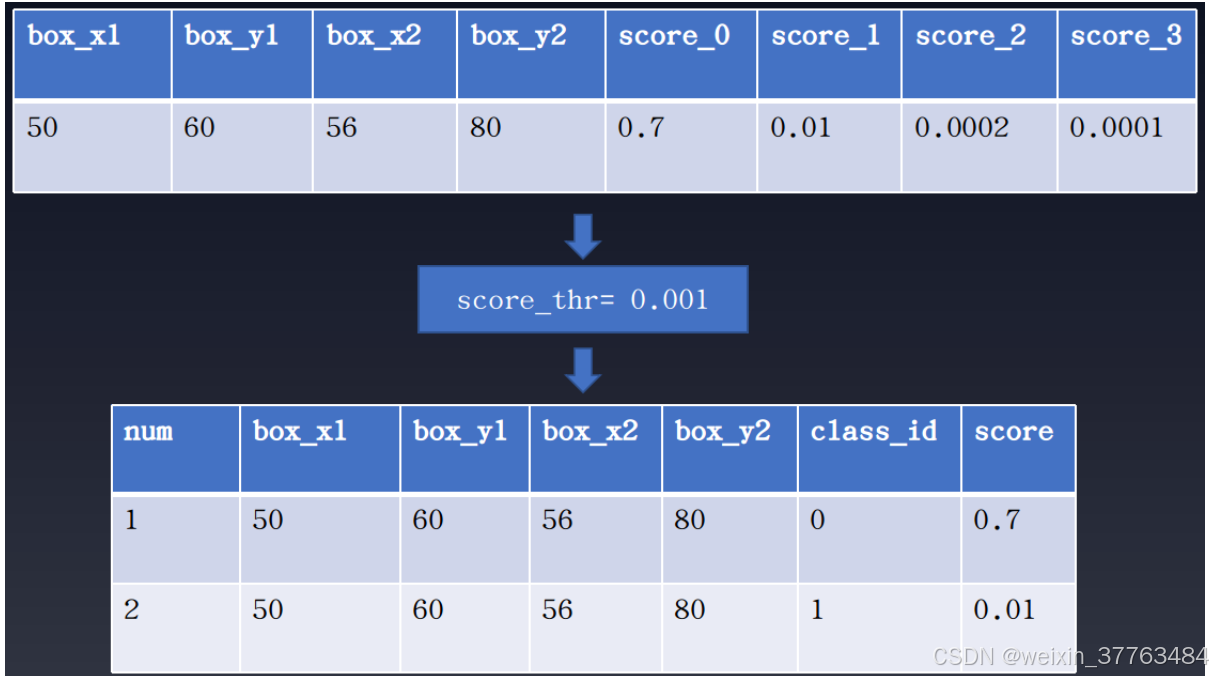
通常,在计算 mAP 时,过滤阈值会被设置为 0.001。由于 sigmoid 的非竞争性预测模式,一个边界框可能会对应多个标签。这种计算方法可以在计算 mAP 时提高召回率,但对于实际应用来说可能并不方便。
一种常见的解决方法是提高过滤阈值。然而,如果你不想出现过多的漏检(false negatives),建议将 multi_label 参数设置为 False。该参数位于配置文件的 model.test_cfg.multi_label,其默认值为 True,允许一个检测框对应多个标签。
2.简化测试流程
需要注意的是,YOLOv5 的测试流程如下:
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
它使用了两种不同功能的 Resize,目的是在评估时提高 mAP 值。在实际部署中,你可以简化这个流程,如下所示:
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='LetterResize',
scale=_base_.img_scale,
allow_scale_up=True,
use_mini_pad=True),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
在实际应用中,YOLOv5算法采用了一个简化的流程,其中multi_label被设置为False,score_thr提高到0.25,iou_threshold降低到0.45。在YOLOv5的配置中,我们为地面检测提供了一套配置参数,详细信息可在yolov5_s-v61_syncbn-detect_8xb16-300e_coco.py中查看。
3.Batch Shape加速测试速度
Batch Shape是YOLOv5提出的一种测试技术,可以加快推理速度。其核心思想是不再要求测试过程中所有图像的尺寸都为640×640,而是允许以不同的尺度进行测试,只要当前批次内的图像形状相同即可。这种方法可以减少额外的图像像素填充,从而加快推理过程。Batch Shape的具体实现可以在相关链接中找到。MMYOLO中的几乎所有算法在测试时都默认启用了Batch Shape策略。如果用户想要禁用此功能,可以将val_dataloader.dataset.batch_shapes_cfg设置为None。
在实际应用中,由于动态形状不如固定形状快速高效,因此这种策略通常不会在现实场景中使用。
4.TTA 提高测试精度
TTA(Test Time Augmentation,测试时增强)是一种多功能技巧,可以提高目标检测模型的性能,尤其在竞赛场景中非常有用。MMYOLO 已经支持 TTA,只需在测试时添加 --tta 参数即可启用。更多详细信息,请参考 TTA 相关文档。

















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









