









1、什么是KNN算法
K近邻算法是一个基本的机器学习算法,可以完成分类和回归任务。对于分类任务的话,主要是遵循”近朱者赤;近墨者黑“的原理。对于其中一个测试的实例,根据其K个最近邻的训练实例的类别进行多数表决然后完成预测。也就是随机森林中的”投票法“原则。
2、KNN算法的三要素
①K值的选择
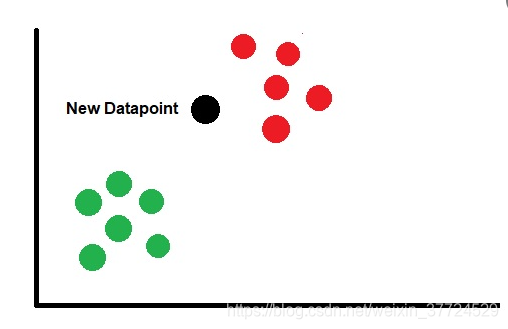
K值的选择是一个非常关键的问题,一般情况下我们通过k折交叉验证,来选取一个比较好的K值,因为K值的选取完全影响了这个算法的性能。举两个极端的例子:如果k=1,那么会造成过拟合的问题,因为拟合的会比较好,完全是由最近的这个实例的类别所决定的,但是有可能存在一个问题,刚好最近的一个点是一个噪声,因为k取太小是不可取的;如果k=n,选取的邻域就是所有的数据这样会造成的问题是欠拟合,误差会变大。这样的结果就是这个模型就是一个废物模型,与输入实例较远的训练实例也会起到作用。下面两个图做以示例:
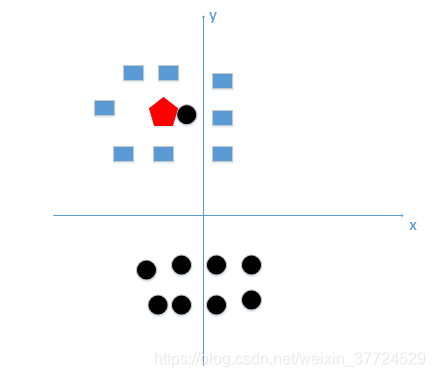
红点就是我们的测试实例,k=1的时候发现黑点就是噪声,过拟合,不准确,如果k=17,最终的分类结果是黑点,但是显然不符合我们的预期,因此这样就是欠拟合,预测的结果就非常的差。
“近朱者赤;近墨者黑”的这个原理适用于我们对任何东西的理解,但是要讲究一个阈值,这个阈值就是我们提及到的K了,比如一个人做了8件好事2件坏事,那么我们就给他发一张好人卡。基本这个原理是适用于k近邻的。
②距离度量
那么计算实例和邻域的距离,肯定是要有度量方式的,目前主流的就是欧氏距离和曼哈顿距离。
欧氏距离公式: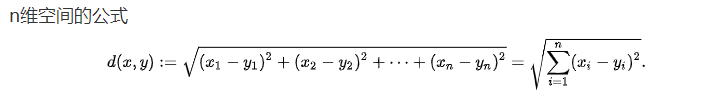
曼哈顿距离公式:
![]()
③决策规则
决策规则往往是“投票法”,少数服从多数,如果相等的话,那就任选其中一个即可。
3、KNN算法的优缺点
优点:
①没有显示的训练
②比较简单
③时间复杂度
④对异常点不敏感
⑤可做回归也可做训练
缺点:
①k值不太好选取
②需要进行归一化的处理
③计算量大
④样本不平衡的时候预测结果不太友好
4、KNN算法的代码实现
训练模型
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
iris_data = datasets.load_iris()
x = iris_data['data']
y = iris_data['target']
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.2)
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(x_train, y_train)
predict = clf.predict(x_test)
acc = metrics.accuracy_score(y_true=y_test,y_pred=predict)
recall = metrics.recall_score(y_true=y_test,y_pred=predict,average='micro')
precision = metrics.precision_score(y_true=y_test,y_pred=predict,average='micro')
print('acc',acc)
print('recall',recall)
print('precision',precision)测试结果
acc 0.9666666666666667
recall 0.9666666666666667
precision 0.9666666666666667
Process finished with exit code 0
















 3413
3413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









