




网址:You Only Look Once: Unified, Real-Time Object Detection https://arxiv.org/abs/1506.02640
- 与先前的方法不同,YOLO直接讲目标检测过程作为一个回归问题,来将空间上可分的bounding boxes和相关的类概率两者一起进行回归。从而可以在一次评估中,完成bounding boxes和类概率的预测
- 优点:可以进行端到端的优化来提高性能;很快,可以学习到对象的通用表达形式
- 缺点:YOLO将会有更多的定位错误,但是对于背景来说,它的false positives会更少
- YOLO可以使用来自于整个图片上的特征来对所有类别对象和所有bb进行决策
- 对于每一个网格,需要去预测B个bb,以及该box对应的confidence score。每一个bb的confidence score:reflect how confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts.反映了模型对于当前bb包含一个对象,同时它认为该预测的box有多准确的程度。注意,若当前cell中确实不存在对象,那么confidence scores就认为是0。每一个bb都有5个预测分类:x,y,w,h,confidence。其中(x, y)表示box的中心点。
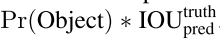
- 同时,每一个网格还需要预测C个条件类别概率,即已知当前对象,该对象对应的类别的概率。注意,类别条件概率与boxes的数目之间相互独立,对于每一个grid cell, 只预测一组类别概率
- 在测试阶段,依据右侧公式即可得到对于每一个bb来说的具体类别所对应的confidence score。

这些confidence score编码的信息为:在当前box中的c各个class的概率,以及每一个预测的box与对象的拟合程度
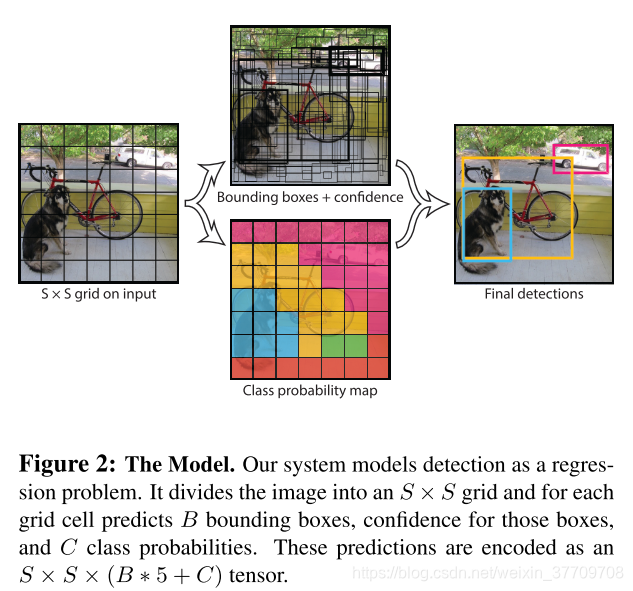
将每一个输入图片划分为SxS的网格,并且在每一个网格中划分B个bb
- 具体网络结构设计如下:使用24个卷积层,后面接2个全连接层。注意,在卷积层之间,为了减小来自于前面那些层的特征空间大小,交替的使用了1x1的卷积层。

预训练过程:将图片划分为228x228大小的小块,在ImageNet数据集上进行预训练,注意,此时只采用前20层卷积层,后面加一个平均池化层和一个全连接层。
正式训练:将前面训练好的20层卷积层,再加上4层卷积层和2个全连接层,新加的这些层的权值由随机初始化得到。且,将提高输入图片的分辨率到448x448
输出的处理:进行归一化。其中,对于每个bb的长和宽,将它们根据整幅图片的长和宽进行归一化;对于x, y值将他们相对于一个特定的grid cell location计算偏移量。两者均处于0-1之间
输出:整个网络的输出是输入image中bb的坐标和类别的概率;对于每一个grid来说,只选取一个bb来作为该单元的代表来完成对一个对线打个预测,该bb在当前单元中具有最高IOU
激活函数的使用:最后一层采用线性激活函数,其余层均使用leaky rectified linear activation
误差函数:用误差的平方的和。但是,- 由于很多grid cells并不包含任何对象,这将使得它们的confidence score均为0,也即会使得对于定位误差和分类误差不同的效果,这会导致模型不稳定,即模型训练会早早的发散出去。所以,最终对定位误差和分类误差赋予不同的权值来更好的衡量平均精确度。增大bb坐标预测损失的权值λcoor,减小对于那些不包含对象的bb的confidence predictions损失的权值λnoobj
- 对于大boxes和小boxes,和的平方的误差赋予它们的权值都是相等的,但是对于同一个偏移量,对于大boxes的影响会比小boxes带来的影响小。所以,为了能够稍微减轻一些这个影响,使用bb的长和宽的正平方根来进行预测,而不是直接使用长和宽的值
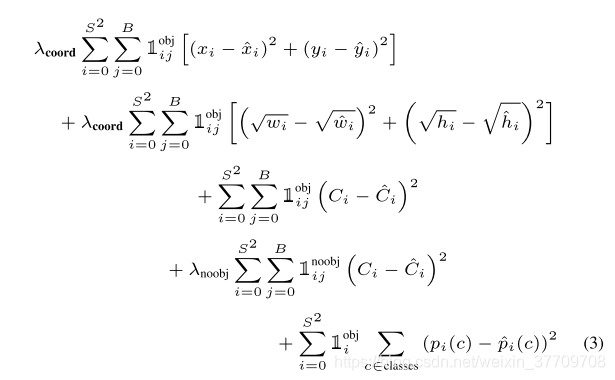
其中,1obj_i表示在当前单元i中是否有对象出现;1obj_i_j表示在单元i中第j个bb作为对于当前预测的代表。对于这个损失函数的理解,前面没有加权值λ的项是原始loss计算值,其余3项均为根据上述1、2两种情况进行的惩罚,来使得训练过程收敛
- 网格设计使得在bb预测过程中强制保证了空间松散性,通常来说,一个对象落在哪一个网格中是很明显的,然后对于每一个对象网络只为其预测一个box。但是,对于一些较大的对象,或者是接近于各个grid的边界的对象来说,需要借助多个cells来进行定位。此时,就要使用非最大抑制来减少重复的检测
- 9中提到的限制较强,这个空间上的约束限制了模型可以预测的相近的对象的数目,当一些小对象以组的形式出现时,模型表现的效果不好。同时,对于新的设置,新的对象出现时,泛化性交叉。且由于在过程中使用了下采样方式减小特征空间,在训练和测试过程中只是用了相对来说较为松散的特征。最后一个就是8.2中的缺陷
- 比较结果:
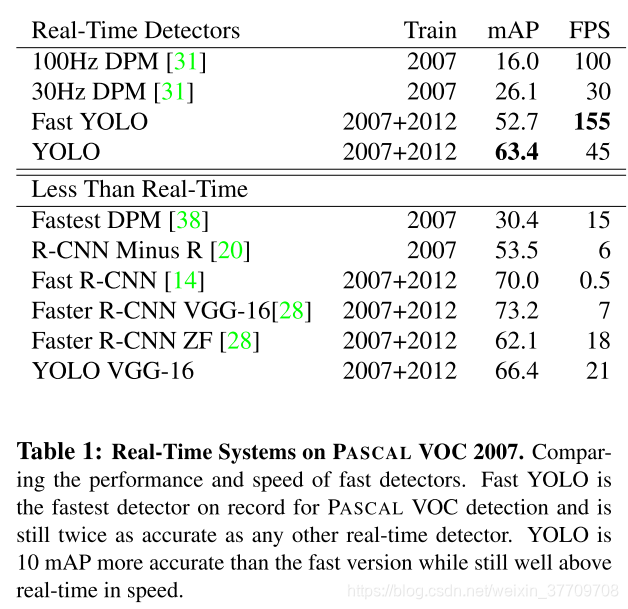
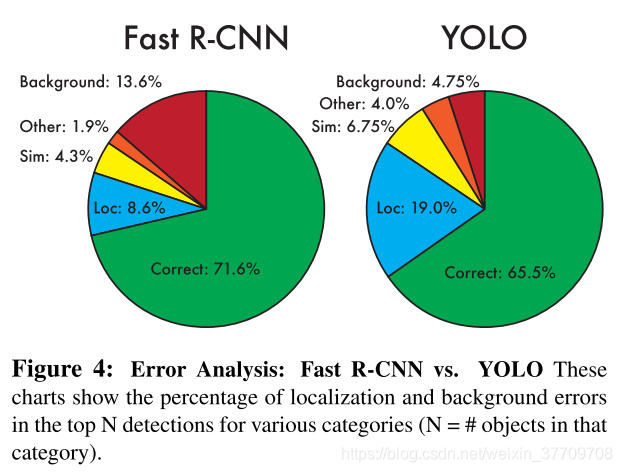
与Fast-RNN的比较结果:YOLO对对象的定位效果交叉,定位误差比其它误差总和还多。Fast-RCNN具有较小的定位误差,但是又有着更多的北京误差,有13.6%的检测认为该grid中不包含任何对象
其中: correct: correct class and IOU>.5
Localization: correct class, .1<IOU<.5
Similar: class is similarm IOU>.1
Other: class is wrong, IOU>.1
Background: IOU<.1 for any object
在计算机视觉中的应用



















 2173
2173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









