







 本文深入解析Spark集群模式及核心术语,包括Application、Driver Program、Cluster Manager等关键组件的作用与交互过程。通过实例说明如何使用spark-submit启动作业,以及Driver如何调度执行代码,将作业分解为stage和task进行并行计算。
本文深入解析Spark集群模式及核心术语,包括Application、Driver Program、Cluster Manager等关键组件的作用与交互过程。通过实例说明如何使用spark-submit启动作业,以及Driver如何调度执行代码,将作业分解为stage和task进行并行计算。
Spark术语
Spark集群模式详解:http://spark.apache.org/docs/latest/cluster-overview.html

集群中的术语
| 术语 | 含义 |
|---|---|
| Application | 构建在Spark上的用户程序。由群集上的driver program和executors 组成。 |
| Application jar | 包含用户的Spark应用程序的jar。在某些情况下,用户想要创建一个包含其应用程序及其依赖项的“超级jar”,但用户的jar不应该包含Hadoop或Spark库,因为这些jar总在运行时添加。 |
| Driver program | 运行应用程序的main()函数并创建SparkContext的进程 |
| Cluster manager | 用于获取群集资源的外部服务(例如,独立管理器,Mesos,YARN) |
| Deploy mode | 区分驱动程序进程的运行位置。在“集群”模式下,框架在集群内部启动驱动程序。在“客户端”模式下,提交者在群集外部启动驱动程序。 |
| Worker node | 可以在群集中运行应用程序代码的任何节点 |
| Executor | 在worker node上启动应用程序的进程,该进程运行任务并将数据保存在内存或磁盘中。每个应用程序都有自己的executors。 |
| Task | 将被发送给一个executor的工作单元 |
| Job | 由多个任务组成的并行计算,这些任务是响应Spark action(例如save,collect)生成的;你会在驱动程序的日志中看到这个术语。 |
| Stage | 每个job被分成相互依赖的较小任务集,称为stages(类似于MapReduce中的map和reduce阶段); 你会在驱动程序的日志中看到这个术语。 |
启动
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
如:
# Run on a YARN cluster
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
过程
在使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是(am)向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,这里使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。
driver是运行程序时具有main方法并创建了spark context的环境对象。如果要看一段程序是否是Driver的话,就要看其内部是否有运行Application的main函数/方法,并且一定会创建SparkContext。sparkContext是通往集群的唯一入口,也是开发者使用Spark集群各种功能的唯一通道,SparkContext是整个程序运行调度的核心。
YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。应用程序有两个层面,即:application=driver+executor
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
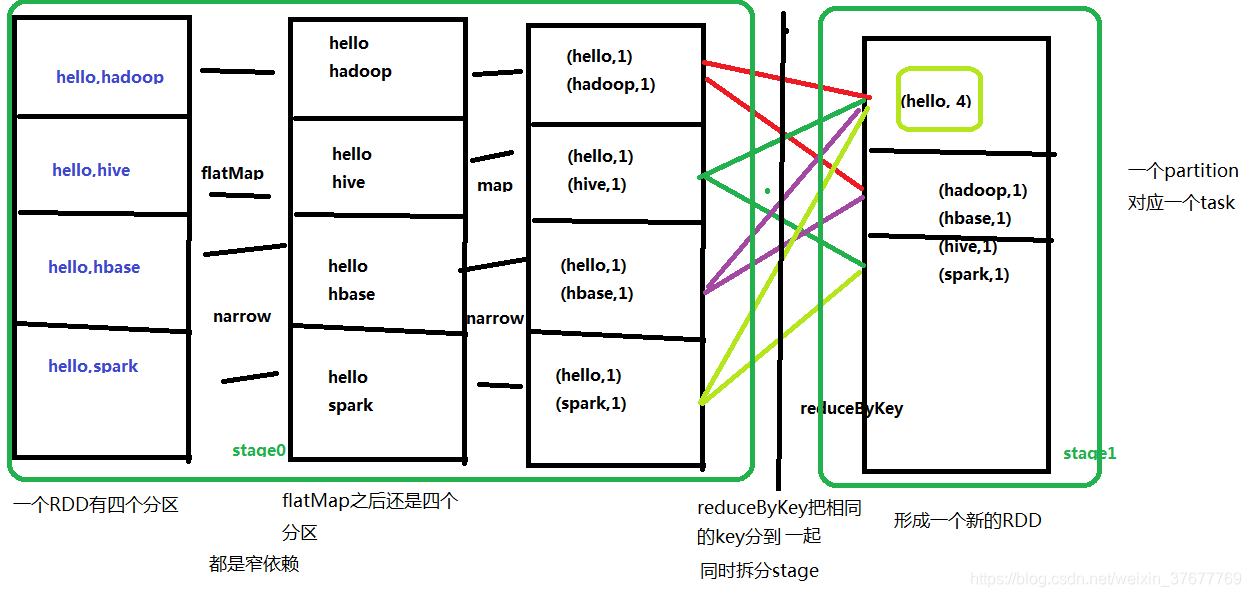
例如:对于一个wordcount来说,代码可能是:
sc.textFile("file path").flatMap(x => x.split("\t")).map((_,1)).reduceByKey(_ + _ ).collect
在程序获得资源运行时,stage、task(对应一个分区)的运行过程(一个RDD有多个分区):

















 5397
5397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









