







 本文详细解析了Spark中RDD的缓存(cache)和持久化(persist)机制,探讨了不同存储级别的选择原则及宽窄依赖对执行计划的影响,为优化Spark作业提供了实用指南。
本文详细解析了Spark中RDD的缓存(cache)和持久化(persist)机制,探讨了不同存储级别的选择原则及宽窄依赖对执行计划的影响,为优化Spark作业提供了实用指南。
官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-persistence
Cache
cache(缓存)和persist(持久化)的区别
cache源码里面调用的是persist,persist里面默认存储化级别是内存
cache lazy(spark core里面是lazy的,spark sql在1.x版本默认不是lazy,是eager)
执行的action操作,在cache之后再次执行会缩短时间。Spark每次执行action类型的算子,都会从头重新计算一遍,如果使用了cache或者persist,就可以直接拿存储的结果来用。
val file = sc.textFile("path")
file.cache
file.count
可以在UI界面查看,如果想主动从内存里去掉:(spark会在内存不够的时候自动把最长时间不用的partition的缓存给去掉)
file.unpersist()
存储级别
注意点:
1:内存足够大,MEMORY_ONLY是最好的
2:当内存不够大的时候,MEMORY_ONLY_SER(只存内存并序列化)加上一个快速的序列化框架(比如Kryo)
3:不要把数据写到磁盘,除非重新计算数据集的代价是高昂的,或者溢出到磁盘前已经使用了内存。否则重新计算分区可能和从磁盘上新读取数据的速度一样快
4:启用副本机制,容错会比较高。但是占用空间。
一般存储级别的选择是:
MEMORY_ONLY
MEMORY_AND_DISK
MEMORY_ONLY_SER (Java and Scala)
MEMORY_AND_DISK_SER (Java and Scala)
Shuffle类算子使用的弊端
Lineage 血缘关系/血统
A =map=> B =filter=>C (RDD之间的关系,A通过map得到了B,B通过filter得到了C),这就是血缘关系。
可以知道:一个RDD是如何从父RDD计算过来的 (如果B的某个分区挂了,可以通过A再得到)
Shuffle
shuffle使多个分区(的部分数据)得到一个分区,这样就会有跨执行程序和机器复制数据,使得操作更复杂,而恢复某个挂了的分区也会变复杂(当挂掉的分区是由shuffle得到的)
Denpendence(依赖)
Narrow(窄依赖) 一个父RDD的partition至多被子RDD的某个partition使用一次(join也可以是窄依赖)(一对一或多对一)
Wide(宽依赖) 一个父RDD的partition会被子RDD的某个partition使用多次(一对多或多对多)
窄依赖重新计算会快,宽依赖重新计算会比较慢。
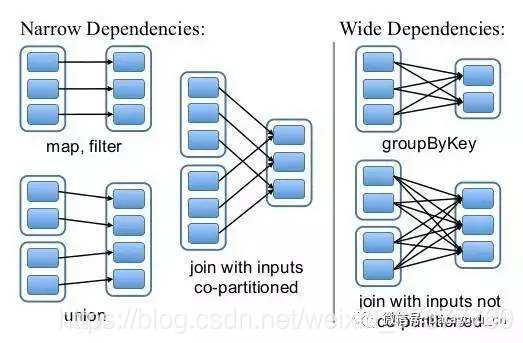
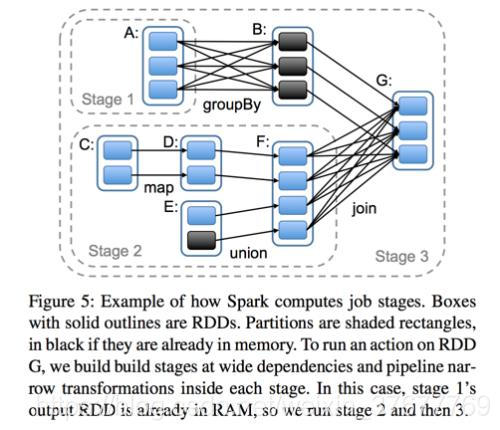
Wide => Shuffle => 拆成2个stage(一个shuffle拆成两个,两个shuffle拆成三个)
执行一次宽依赖就会把stage拆成两份:
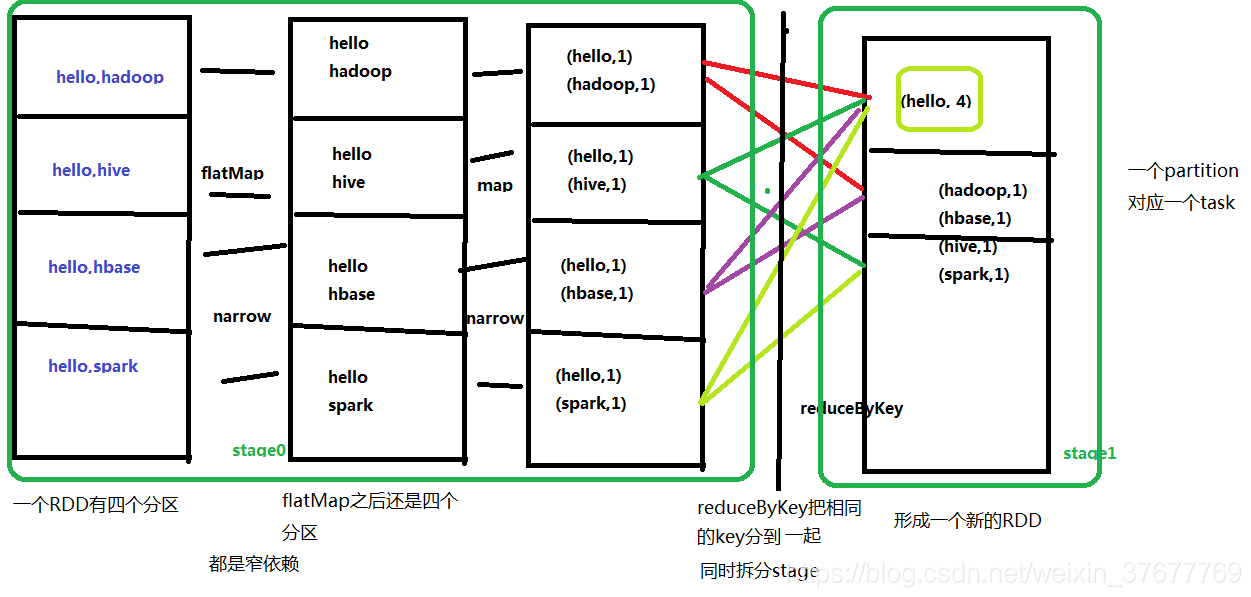
wordcount使用的依赖(reduceByKey是宽依赖,其余都是窄依赖)
flatMap、map、reduceByKey
coalesce
可以压缩数量
coalesce(10) => 100 => 10(合并小文件的一种方式)(窄依赖)
对于repartition来说,则是拆分开:
repartition:10==>50 (重新分区)(数据倾斜的一种处理方案)(宽依赖)
一般在filter(filter过滤掉了大量的数据)后加上一个coalesce。

















 2638
2638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









