






1:数据结构
1:栈和队列的区别,具体的场景应用
栈(Stack)和队列(Queue)是两种基本的数据结构,它们在数据的存取顺序不同;
栈,后进先出:最后进入栈的元素最先被移出。
队列,先进先出:第一个进入队列的元素最先被移出。
2:set 的去重机制
HashSet 去重机制
HashSet 是基于哈希表(Hash Table)实现的,它通过元素的 哈希值(hash code) 和 equals() 方法来确定元素的唯一性。
TreeSet 去重机制
TreeSet 是基于红黑树(Red-Black Tree)实现的,它通过元素的
自然顺序 或 自定义比 较器 来保证集合的有序性和唯一性。
3:HashMap 的实现原理
基本结构: 数组 + 链表/红黑树
存储原理:
当往 HashMap 中存储一个键值对时,
HashMap 首先会根据键的哈希值(hash code)计算出该键值对在数组中的存储位置。
如果不同的键有相同的哈希值(即发生了 哈希冲突)
HashMap 会将这些键值对存储在同一个位置(即同一个桶)中,通过链表或红黑树来管理。
哈希函数:
HashMap 通过键的 hashCode() 方法生成键的哈希值
并通过一个哈希函数将哈希值转换为数组的索引。
计算数组索引的公式:index = (n - 1) & hash,其中 n 是数组的长度。
使用按位与操作 (&) 来对哈希值进行限制,使得索引值总是落在数组的有效范围内。
插入操作
计算哈希值,确定数组索引,检查哈希冲突,如果该位置为空,则将键值对放入该位置。
如果该位置已经有其他键值对(即发生哈希冲突),
HashMap 会遍历该位置的链表或红黑树,检查是否已经有相同的键:
如果有相同的键,则更新对应的值。
如果没有相同的键,则将新的键值对添加到链表或树的末尾。
链表到红黑树的转换
当同一个位置的链表长度超过 8 时(默认值),HashMap 会将链表转换为 红黑树
如果链表长度小于 6,会从红黑树转换回链表。
查找操作
HashMap 的查找操作是通过键的哈希值来定位对应的数组位置,从而查找值的。
查找步骤如下:
通过键的 hashCode() 计算哈希值。
通过哈希值和数组长度计算出对应的数组索引。
在该数组索引处检查是否有链表或红黑树:
如果没有,则返回 null。
如果有,则根据链表或红黑树的结构找到对应的键,并返回相应的值。
扩容机制
HashMap 的数组在插入大量键值对时可能会装满,这时需要对数组进行 扩容。
HashMap 的扩容机制是通过重新分配更大的数组,
并将原数组中的元素重新哈希并插入到新数组中。
触发扩容的条件:
当 HashMap 中的元素数量超过 阈值 时,触发扩容。
阈值的计算:阈值 = 数组长度 * 负载因子,默认负载因子为 0.75。
扩容过程:
创建一个新数组,长度是原数组的 2 倍。
将原数组中的所有键值对重新计算哈希值,并插入到新数组中。
如果某个位置有链表或红黑树,则重新计算每个键的数组索引,
重新分配到新数组的不同位置。
删除操作
删除操作也是通过键的哈希值定位到数组中的具体位置。
删除步骤如下:
通过键的 hashCode() 计算哈希值。
根据哈希值定位到数组的具体索引。
遍历该位置的链表或红黑树,找到对应的键并移除该节点。
如果是红黑树,还需要进行树的调整。
4:HashMap 和 Hashtable 区别
1. 线程安全性
HashMap:非线程安全。它不支持多个线程同时访问和修改同一个 HashMap,如果有多线程并发访问,必须通过外部同步机制(如 Collections.synchronizedMap() 或 ConcurrentHashMap)来保证线程安全。
Hashtable:线程安全。Hashtable 的所有方法都使用了 synchronized 关键字进行同步。
2. 性能
HashMap:由于没有内置的同步机制,HashMap 的性能一般比 Hashtable 要高。
3. 是否允许 null 键和值
HashMap:允许 1 个 null 键 和 多个 null 值。
Hashtable:不允许 null 键或 null 值。
4. 扩容机制
HashMap:默认初始容量为 16,负载因子为 0.75,以 2 倍扩容
Hashtable:默认初始容量为 11,负载因子为 0.75,以 2 倍加 1扩容
2:线程
1. 什么是线程和进程?
进程:是指一个在内存中运行的应用程序,常见的app都是一个个进程。进程具有自己独立的内存空间,一个进程可以有多个线程;
线程:是指进程中的一个执行任务的单元,负责执行当前进程中程序的执行,一个进程至少有一个线程,一个进程内的多个线程见可共享数据
2:创建线程的几种方式?
实现Runnable接口
继承Thread类
实现Callable接口
使用Executors工具类创建线程池
3:Java线程状态和方法?
Java线程状态有6种,分别是 NEW(新建状态)、RUNNABLE(就绪状态)、 BLOCKED(阻塞状态)、WAIT(等待状态)、TIME_WAIT(超时等待状态)、TERMINATED(终止状态):
4:sleep()和wait()方法的区别是什么?
虽然两个方法都有让线程暂停的作用,但是两个还是发挥不同作用的:
wait()是Object类的方法,sleep()是Thread类的方法;
wait()释放锁,让线程进入等待状态,sleep()不释放锁,让线程进入阻塞状态;
wait()方法后线程不会自动恢复执行,需要手动调用notify()/notifyAll()方法唤醒,sleep()在睡眠固定时间后会走动苏醒;
wait()常用于线程间交互/通信,sleep通常被用于暂停等待
5:并发编程的三要素是什么?
原子性:原子是指一个不可再分割的颗粒,原子性值得是一个或者多个操作要么全部成功要么全部失败;
可见性:一个线程对贡献变量的修改,另一个线程能够立刻看到(volatile,synchronized);
有序性:程序执行代码的顺序要按照代码的先后顺序执行。
6:形成死锁的四个必要条件:
互斥条件:线程申请的资源在一段时间中只能被一个线程使用
请求与等待条件:线程已经拥有了一个资源,但是又申请新的资源,拥有的资源保持不变 。
不可剥夺条件:在一个线程没有用完,主动释放资源的时候,不能被抢占。
循环等待条件:多个线程之间存在资源循环链。
7:线程池的拒绝策略?
当任务队列和线程池都满了时所采取的应对策略:
默认是AbordPolicy,表示无法处理新任务,并抛出RejectedExecutionException异常;
CallerRunsPolicy:用调用者所在的线程处理任务。此策略提供简单的反馈机制,能够减缓新任务的提交速度;
DiscardPolicy:不能执行任务,并将任务删除;
DiscardOldestPolicy:丢弃队列最近的任务,并执行当前的任务。
8:Synchronization lock都是悲观锁,适合写操作比较多的情况
乐观锁CAS算法,其实就是使用当前线程副本数据跟内存数据对比,然后再去操作或者去重试
原子类就是CAS
CompareAndSet底层就是调用CompareAndSwap,不推荐CompareAndSwap,因为他是unsafe,不受jvm 管理,需要自己释放内存
CAS会引入ABA问题,原子类加标记
volatile 关键字,可见性和排序行,防止CPU出现指令重排,懒汉单例模式就是volatile 修饰,加锁双重判断
3:IO
1.什么是Java NIO?
Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
4:设计模式
1:单例模式:
单例模式整个系统有一个对象实例。
优点:不会频繁地创建和销毁对象,浪费系统资源。
使用场景:IO 、数据库连接、Redis 连接等。
静态加载单例模式代码实现:
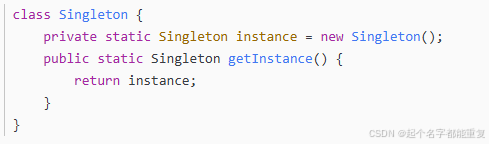
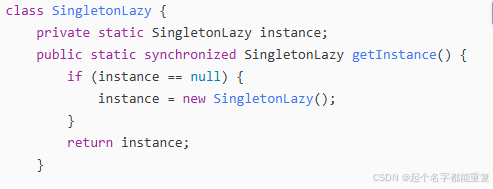
单例模式的延迟加载,非线程安全

单例模式的线程安全代码
2:工厂模式
建立一个工厂类,对实现了同一接口的一些类进行实例的创建
3:策略模式
策略模式是指定义一系列算法,将每个算法都封装起来,并且使他们之间可以相互替换。
4:观察者模式
观察者模式是定义对象间的一种一对多依赖关系,使得每当一个对象状态发生改变时,其相关依赖对象皆得到通知并被自动更新
5:代理模式
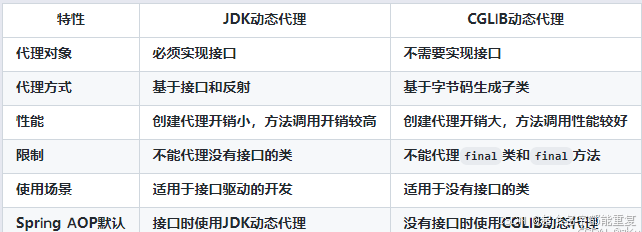
JDK动态代理
基于接口
反射机制 InvocationHandler.invoke()
CGLIB动态代理
基于字节码操作
生成目标类的子类并重写目标类的方法来实现代理
优缺点

















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









