



Python进阶
目录
1.装饰器
第一个问题:什么是装饰器,为何要引入装饰器,对于编写程序有什么帮助吗?
装饰器就是对一段函数的一个装饰,比如我们要统计某个函数的从执行开始到执行结束耗费的时间,用最简单明了的程序去实现,代码如下:
import time
sum=0
def sum_numbers(n):
global sum
for i in range(n):
sum+=i
return sum
if __name__ == "__main__":
start_time = time.time()
result = sum_numbers(10000)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"Sum: {result}")
print(f"Elapsed Time: {elapsed_time} seconds")
再比如我们要统计访问百度从发起接口请求到接口返回结果耗时,可以编写代码如下:
import requests
import time
def baidu_api_request():
url = "http://www.baidu.com"
response = requests.get(url)
return response.text
if __name__ == "__main__":
start_time = time.time()
result = baidu_api_request()
end_time = time.time()
elapsed_time = end_time - start_time
print(f"Elapsed Time: {elapsed_time} seconds")
现在我们就能看到其实这两段代码统计结束和起始之差的代码是高度类似的,这个其实是可以封装成一个方法的,这个其实就是我们接下来要讲解的装饰器。代码如下,其中calculate_elapsed_time就是一个装饰器方法,可以很好的传入接口请求方法并统计耗时时间
# -- coding: utf-8 --**
import time
import requests
def baidu_api_request():
url = "http://www.baidu.com"
response = requests.get(url)
return response.text
def calculate_elapsed_time(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"Elapsed Time: {elapsed_time:.6f} seconds")
return result
return wrapper
# 示例函数,你可以替换为你的实际功能
@calculate_elapsed_time
def request_spendtime():
# 这里是你的实际代码逻辑
result = baidu_api_request()
print("Function executed!")
# 调用被装饰的函数
request_spendtime()
装饰器就像是一个通用的方法,通过@method方式对不同的函数进行装饰,进而大大提升代码的耦合性,写出高效简洁的程序。
第二个问题:什么情况下使用装饰器?
一般针对实际开发场景有两个情况使用装饰器最多,一个是创建单例模式,对象创建实例之后调用函数。比如创建一个单例装饰器A,用该装饰器装饰类B和类C。
# -- coding: utf-8 --**
def singleton(cls):
instances = {}
def get_instance(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return get_instance
# 使用装饰器将类B和类C变成单例
@singleton
class ClassB:
def __init__(self):
self.name = "ClassB"
@singleton
class ClassC:
def __init__(self):
self.name = "ClassC"
# 示例使用
instance_b1 = ClassB()
instance_b2 = ClassB()
print(instance_b1 is instance_b2) # True,说明是同一个实例
instance_c1 = ClassC()
instance_c2 = ClassC()
print(instance_c1 is instance_c2) # True,说明是同一个实例
第二个常见就是打印log装饰器,打印函数的参数和函数输出的结果
# -- coding: utf-8 --**
import functools
import time
def log_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print(f"Function {func.__name__} called with args {args} and kwargs {kwargs}")
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"Result: {result}")
print(f"Execution time: {end_time - start_time:.6f} seconds")
return result
return wrapper
# 示例函数,你可以替换为你的实际功能
@log_decorator
def example_function(a, b):
# 这里是你的实际代码逻辑
time.sleep(2)
return a + b
# 调用被装饰的函数
result = example_function(3, 4)
2.上下文管理器
问题1:什么是上下文管理器,有什么作用,一般使用场景是什么。
我们平常读写文件或对数据库进行增删改查的时候,会频繁的涉及到文件的输入和输出流。数据库的关闭和连接,这个其实是比较耗费资源的。为此需要自动的进行这些操作的开始和结束,捕获期间的异常,此时上下文管理器就应运而生了。下面列举几个应用场景。
第一个例子:文件操作:通过上下文管理器可以自动打开和关闭文件,不用手动编写file.close()函数了。
# -- coding: utf-8 --**
class FileHandler:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file
def __exit__(self, exc_type, exc_value, traceback):
self.file.close()
with FileHandler('example.txt', 'r') as file:
content = file.read()
print(content)
第二个例子:数据库连接,通过上下文管理器也能自动关闭数据库连接,节省资源
import sqlite3
class DatabaseConnection:
def __init__(self, dbname):
self.dbname = dbname
def __enter__(self):
self.connection = sqlite3.connect(self.dbname)
return self.connection
def __exit__(self, exc_type, exc_value, traceback):
self.connection.close()
with DatabaseConnection('example.db') as connection:
cursor = connection.cursor()
# 执行数据库操作
# 连接在这里自动关闭
第三个自定义的上下文管理器,处理类中的函数
class CustomContextManager:
def __enter__(self):
print("Entering the context")
return self # 返回值将被赋给as后面的变量
def __exit__(self, exc_type, exc_value, traceback):
print("Exiting the context")
with CustomContextManager() as cm:
# 在这里执行需要在进入和退出上下文时执行的操作
print("输出当前的内容")
控制头输出的顺序是:
Entering the context
输出当前的内容
Exiting the context
3.生成器
问题:什么是生成器,它的作用是什么,什么场景下会频繁使用生成器。
生成器是一个函数,不会一个一个的返回函数值,而是一次按照顺序返回一个或者多个值,该函数执行直到被通知输出最后一个值。生成器使用yield语句来产生值,每次调用yield时,生成器会暂停执行并将值返回给调用者,保持当前状态。这使得生成器非常有效,尤其是在处理大量数据或需要惰性计算时。
作用:
惰性计算: 生成器允许按需生成值,而不是一次性生成所有值。这对于处理大型数据集或无限序列非常有用,因为它节省了内存。
迭代效率:生成器可以在迭代过程中动态生成值,节省了内存开销,尤其在数据量大时表现明显。
无限序列:生成器可以用于表示无限序列,因为它们可以在需要时生成值,而不会耗尽内存。
下面列举几个例子。
# -- coding: utf-8 --**
# 生成器函数,生成自然数序列
def natural_numbers():
n = 1
while True:
yield n
n += 1
# 使用生成器处理无限序列
for num in natural_numbers():
if num > 10:
break
print(num)
计算斐波那契数列
# -- coding: utf-8 --**
# 生成器函数,生成自然数序列
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# 使用生成器计算斐波那契数列
fib_gen = fibonacci()
for _ in range(10):
print(next(fib_gen))
标准库中的生成器
# -- coding: utf-8 --**
for i in range(5):
print(i)
#enumerate 函数用于同时获取列表的索引和值,它返回一个生成器。
fruits = ['apple', 'banana', 'cherry']
for index, value in enumerate(fruits):
print(f"Index: {index}, Value: {value}")
##enumerate 函数用于同时获取列表的索引和值,它返回一个生成器。
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
for name, age in zip(names, ages):
print(f"Name: {name}, Age: {age}")
#filter 函数用于根据指定的条件筛选可迭代对象中的元素
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
filtered_numbers = filter(lambda x: x % 2 == 0, numbers)
for num in filtered_numbers:
print(num)
4.魔术方法
问题一:什么是魔法方法,魔法方法存在的意义是什么,什么场景下使用魔法方法
魔法方法其实就是内置函数。魔法方法(Magic Methods),也被称为特殊方法或双下划线方法,是在类中以双下划线__开头和结尾的方法。它们在特定的情况下由解释器调用,用于执行特殊的操作。魔法方法的存在旨在提供一种自定义类行为的方式,使得类实例可以在特定的操作下表现得更像内置类型。
魔法方法的意义有以下两个:
1.自定义类行为:魔法方法允许你自定义类在特定情况下的行为,例如实例创建、属性访问、运算符重载等。
2.提供类似内置类型的接口:通过实现特定的魔法方法,可以使自定义类在使用时更类似于内置类型,提高代码的可读性和一致性。
下面列举几个常用魔方方法的场景:
# -- coding: utf-8 --**
#__init__(self, ...): 类的构造方法,用于初始化对象。在对象创建时被调用。
class MyClass:
def __init__(self, name,age):
self.name = name
self.age=age
obj = MyClass("Example",23)
print(obj.name)
print(obj.age)
#__str__(self): 返回对象的字符串表示,通过str(obj)或print(obj)调用
class MyClass:
def __init__(self, name,address):
self.name = name
self.address=address
def __str__(self):
return f"MyClass object with name: {self.name}{self.address}"
obj = MyClass("Example",'Beijing')
print(obj) # 输出: MyClass object with name: ExampleBeijing
print(obj.__str__()) # 输出: MyClass object with name: ExampleBeijing
#__len__(self): 返回对象的长度,通过len(obj)调用。
class MyList:
def __init__(self, items):
self.items = items
def __len__(self):
return len(self.items)
my_list = MyList([1, 2, 3, 4])
print(len(my_list)) # 输出: 4
print(my_list.__len__()) # 输出: 4
#__getitem__(self, key): 获取对象的元素,通过obj[key]调用。
class MyList:
def __init__(self, items):
self.items = items
def __getitem__(self, index):
return self.items[index]
my_list = MyList([1, 2, 3, 4])
print(my_list[2]) # 输出: 3
#__add__(self, other): 实现对象的加法运算,通过obj1 + obj2调用。
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, other):
return Point(self.x + other.x, self.y + other.y)
p1 = Point(1, 2)
p2 = Point(3, 4)
result = p1 + p2
print(result.x, result.y) # 输出: 4, 6
问题:解释 __init__ 和 __new__ 方法之间的区别。
答案: __new__ 在实例创建之前调用,负责创建并返回实例。__init__ 在实例已经创建后调用,用于初始化实例的属性。
问题:如何通过 with 语句使用上下文管理器,即实现 __enter__ 和 __exit__ 方法?
答案: 实现 __enter__ 方法返回需要管理的资源,并在 __exit__ 方法中进行资源清理。这样可以使用 with 语句进行资源管理。
问题:解释 __getattr__ 和 __setattr__ 的区别,并说明它们在类中的作用。
答案: __getattr__ 在属性访问失败时调用,用于处理未定义的属性。__setattr__ 在给属性赋值时调用,用于拦截属性的赋值。
以下是一些常见的魔法方法的列表,附带简要的解释和用途:
__init__(self, ...): 构造方法,用于初始化对象。
__new__(cls, ...): 创建对象的实例,通常在对象实例化之前调用。
__del__(self): 析构方法,用于释放对象占用的资源。
__str__(self): 返回对象的字符串表示,通过str(obj)或print(obj)调用。
__repr__(self): 返回对象的开发者友好的字符串表示,通常用于调试。
__len__(self): 返回对象的长度,通过len(obj)调用。
__getitem__(self, key): 获取对象的元素,通过obj[key]调用。
__setitem__(self, key, value): 设置对象的元素,通过obj[key] = value调用。
__delitem__(self, key): 删除对象的元素,通过del obj[key]调用。
__iter__(self): 返回一个迭代器对象,使得对象可以被迭代。
__next__(self): 在迭代器中,返回下一个元素。
__call__(self, ...): 允许对象像函数一样被调用。
__eq__(self, other): 用于判断对象相等性。
__ne__(self, other): 用于判断对象的不等性。
__lt__(self, other): 用于判断对象是否小于另一个对象。
__le__(self, other): 用于判断对象是否小于或等于另一个对象。
__gt__(self, other): 用于判断对象是否大于另一个对象。
__ge__(self, other): 用于判断对象是否大于或等于另一个对象。
__hash__(self): 返回对象的哈希值,通常与__eq__一起使用。
__enter__(self): 进入上下文管理器的方法,在with语句中调用。
__exit__(self, exc_type, exc_value, traceback): 退出上下文管理器的方法,在with语句结束时调用。
__getattr__(self, name): 在访问未定义的属性时调用。
__setattr__(self, name, value): 在给属性赋值时调用。
__delattr__(self, name): 在删除属性时调用。
__slots__: 限制对象可以拥有的属性,用于节省内存。
5.元类
问题:什么是元类,元类的作用是什么,元类常见的使用场景有哪些
元类(Metaclass)是一种高级的编程概念,用于定义类的创建和行为。在Python中,类是对象,而元类是类的类。元类允许你控制类的创建过程,可以认为是类的“模板”
元类的作用:
控制类的创建: 元类允许你在类被创建的时候执行一些特定的操作,例如修改类的属性、方法或添加新的方法。
规范类的行为: 元类可以用于强制编码规范,确保类的一致性和正确性。
自动化重复的工作: 元类可以用于自动化一些常规的工作,例如自动添加类属性、检查类定义等。
下面列举一个例子
class MyMeta(type):
def __new__(cls, name, bases, dct):
# 对类进行修改或检查
if 'my_attribute' not in dct:
dct['my_attribute'] = 'Default'
return super().__new__(cls, name, bases, dct)
class MyClass(metaclass=MyMeta):
pass
obj = MyClass()
print(obj.my_attribute) # 输出: Default
下面是针对上面代码的解释:
在这个示例中,MyMeta 是一个简单的元类,通过在__new__方法中检查类的属性,
动态添加了一个默认的属性my_attribute。在定义MyClass时,我们指定了metaclass=MyMeta,
使得MyMeta成为MyClass的元类。这样,创建MyClass类时,元类的__new__方法会被调用,
允许我们在类创建时进行自定义的操作。
元类实现单例模式:
# -- coding: utf-8 --**
class SingletonMeta(type):
_instances = {}
def __call__(cls, *args, **kwargs):
# 如果类的实例不存在,则创建一个新的实例
if cls not in cls._instances:
instance = super().__call__(*args, **kwargs)
cls._instances[cls] = instance
# 返回已存在的实例
return cls._instances[cls]
class SingletonClass(metaclass=SingletonMeta):
def __init__(self, name):
self.name = name
# 创建多个实例,但只有一个实际的实例存在
instance1 = SingletonClass("Instance 1")
instance2 = SingletonClass("Instance 2")
print(instance1 is instance2) # 输出: True
关于上面的代码解释如下:
在这个例子中,SingletonMeta 元类用于确保一个类只有一个实例。通过将 SingletonClass 指定为使用 SingletonMeta 元类,即 metaclass=SingletonMeta,我们确保了 SingletonClass 的实例唯一性。
6.类工厂
问题:什么是类工厂,类工厂的作用是什么,常见的类工厂的用法有哪些?
类工厂(Class Factory) 是一种模式或技术,它允许在运行时动态创建类。类工厂通常是一个函数或类,接受一些参数,并返回一个新的类。这样的设计模式使得代码更加灵活,可以根据不同的需求创建不同的类
类工厂的作用:动态创建类: 类工厂允许在运行时根据不同的需求动态创建类,而不是在编写代码时就固定好类的结构。参数化类的创建: 类工厂可以接受参数,根据参数的不同来生成不同的类,实现类的定制化。简化代码: 使用类工厂可以避免重复的类定义,尤其是当需要创建大量相似但不完全相同的类时。
# -- coding: utf-8 --**
def create_class(name, attrs):
return type(name, (), attrs)
#基本类工厂函数:
MyClass = create_class("MyClass", {"x": 10, "y": 20})
obj = MyClass()
print(obj.x, obj.y) # 输出: 10 20
#参数化类工厂函数
def create_person_class(name, age):
return type(name, (), {"name": name, "age": age})
Person = create_person_class("John", 30)
john = Person()
print(john.name, john.age) # 输出: John 30
#类装饰器作为类工厂
def add_method(cls):
def new_method(self):
return f"Hello, I'm {self.name}"
cls.new_method = new_method
return cls
@add_method
class Person:
def __init__(self, name):
self.name = name
john = Person("John")
print(john.new_method()) # 输出: Hello, I'm John
7.抽象基类
问题:什么是抽象基类,抽象基类有什么作用,常见使用抽象基类的场景有哪些
# -- coding: utf-8 --**
from abc import ABC, abstractmethod
class MyABC(ABC):
@abstractmethod
def my_method(self):
print("my_method")
class MyConcreteClass(MyABC):
def my_method(self):
# 实现抽象方法
print("MyConcreteClass")
obj=MyConcreteClass()
print(obj.my_method())
#Can't instantiate abstract class MyABC with abstract methods my_method
obj2=MyABC()
print(obj2.my_method())
8.正则表达式
问题:什么是正则表达式?该表达式常见的应用场景有哪些,请列举例子
正则表达式(Regular Expression,简称正则或RegExp) 是一种强大的文本匹配和处理工具,用于在字符串中匹配、搜索、替换特定模式的文本。正则表达式由字符和操作符组成,可以描述字符的组合、字符的数量和字符之间的关系。
# -- coding: utf-8 --**
#文本搜索和匹配: 查找文本中符合特定模式的字符串。
import re
pattern = re.compile(r'\b\w+@\w+\.\w+\b')
text = "Emails: john@example.com, alice@gmail.com, bob@yahoo.com"
matches = pattern.findall(text)
print(matches)
#数据提取和解析: 从字符串中提取特定格式的数据。
pattern = re.compile(r'(\d{2})/(\d{2})/(\d{4})')
date_string = "Today's date is 12/25/2022"
match = pattern.search(date_string)
if match:
day, month, year = match.groups()
print(f"Date: {year}-{month}-{day}")
pattern = re.compile(r'\b\w+\b')
text = "Replace these words"
result = pattern.sub('***', text)
print(result)
log_pattern = re.compile(r'(\d+\.\d+\.\d+\.\d+) - - \[([^\]]+)\] "(GET|POST) ([^"]+)" (\d+) (\d+)')
log_entry = '192.168.1.1 - - [15/Dec/2022:12:30:45 +0000] "GET /page.html" 200 1234'
match = log_pattern.match(log_entry)
if match:
ip, timestamp, method, path, status, size = match.groups()
print(f"IP: {ip}, Time: {timestamp}, Method: {method}, Path: {path}, Status: {status}, Size: {size}")
常见的正则表达式及其说明
1 ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ 匹配标准邮箱地址
2 `^(https? ftp)://[^\s/$.?#].[^\s]*$`
3 ^1[3456789]\d{9}$ 匹配中国大陆手机号码
4 ^\d{4}-\d{2}-\d{2}$ 匹配格式为 "YYYY-MM-DD" 的日期
6 ^\d{6}$ 匹配六位数字的邮政编码
7 ^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 匹配长度为5到16位的用户名,以字母开头,允许字母、数字、下划线
`^(^\d{15}$) (^\d{18}$)
^[\u4e00-\u9fa5]+$ 匹配一个或多个中文字符
<([a-z]+)>(.*?)<\/\1> 匹配HTML标签及其内容
^[1-9]\d{4,10}$ 匹配5到11位的QQ号码
`^[a-zA-Z]:\(?:[^\:*?"<> \r\n]+\)[^\:?"<>
^([0-9A-Fa-f]{2}[:-]){5}([0-9A-Fa-f]{2})$ 匹配标准的MAC地址
^-?\d+(\.\d+)?$ 匹配整数或浮点数
<!--(.*?)--> 匹配HTML注释
\[([^\]]+)\]\(([^)]+)\) 匹配Markdown中的链接
\b(\w+)\s+\1\b 匹配连续重复的单词
<(\w+)[^>]*>.*?<\/\1> 匹配XML标签及其内容
^\s*$ 匹配空白行
9.python多线程编程
什么是多线程,它的作用是什么,什么场景下使用多线程
多线程(Multithreading 指在同一进程内同时运行多个线程,每个线程都独立执行不同的任务。线程是操作系统进行调度的最小单位,它在进程内分享相同的资源,如内存空间和文件句柄等。多线程在提高程序并发性、响应性和资源利用率方面具有优势
# -- coding: utf-8 --**
# from concurrent.futures import ThreadPoolExecutor, as_completed
# import pandas as pd
import time
import openai
import pandas as pd
from concurrent.futures import ThreadPoolExecutor, as_completed
successcount=0
totalcount=0
start_time=time.time()
def req_openai(question, answer1, answer2):
global totalcount
totalcount+=1
# gpt-3.5-turbo
#openai.api_base = "https://openkey.cloud/v1"
openai.api_base="https://op.zakix.info/v1"
openai.api_key = "sk-a70CIVdZjWb1rMzEMwFoXolVs2Jhllh5y6a436PaHo4Iuflw"
retry_times = 0
messages = []
smaple = '1.单位或者个体工商户为聘用的员工无偿提供服务不需要缴纳增值税 和 2.单位或者个体工商户为聘用的员工无偿提供服务不用缴纳增值税,只需要分别输出 不需要缴纳增值税||不用缴纳增值税'
#message = answer1 + " 跟内容 " + answer2 + "意思是否相近,回答A.基本一致 B.部分一致 C.不一致,直接回答A或者B或者C,并把意思相近的两段话中最核心的字符串分别输出 ,用||分隔开回答,字符串1和字符串2,除此不需要其他任何多余的回答" + "参考例子" + smaple
message = answer1 + " 跟内容 " + answer2 + "意思是否相近,回答A.基本一致 B.部分一致 C.不一致,直接回答A或者B或者C,除此不需要其他任何多余的回答" + "参考例子" + smaple
messages.append({"role": "user", "content": message})
try:
response = openai.ChatCompletion.create(
# model='gpt-3.5-turbo',
# model="gpt-4",
model='gpt-4-1106-preview',
messages=messages,
temperature=1
)
reply = response["choices"][0]['message']['content']
return reply
except Exception as r:
print(r)
return ''
def process_row(row):
question = row[0]
answer1 = row[1]
answer2 = row[2]
# 模拟接口请求,实际中需要根据你的需求修改
result = req_openai(question, answer1, answer2)
# 返回问题+第二列和第三列意思是否一致的答案
return f"{question}&&{answer1}&&{answer2}的意思是否一致:||{result}"
def main():
global successcount;
# 读取Excel文件
filename='湖北税务局评测1527.xlsx'
df = pd.read_excel(filename)
with ThreadPoolExecutor() as executor:
# 提交任务并获得Future对象
futures = {executor.submit(process_row, row): row for _, row in df.iterrows()}
results = []
for future in as_completed(futures):
row = futures[future]
try:
result = future.result()
results.append(result)
except Exception as e:
# 处理异常
print(f"Error processing row {row}: {e}")
# 将结果写入新的Excel文件的第四列
df['多线程返回结果'] = results
df.to_excel('output_file.xlsx', index=False)
df['最终结果'] = df['多线程返回结果'].str.split('||')
length = df.iloc[:, 3]
import datetime
now = datetime.datetime.now()
date_string = now.strftime("%Y-%m-%d")
time_string = now.strftime("%H:%M:%S")
print("当前日期:", date_string)
print("当前时间:", date_string + time_string.replace('-', ':'))
now_time = date_string + "-" + time_string.replace(':', '-')
print(now_time)
for i in range(len(length)):
df.iat[i, 4] = str(df.iloc[i, 3]).split('||')[1]
print(str(df.iloc[i, 3]).split('||')[1])
if str(df.iloc[i, 3]).split('||')[1]=='A':
successcount += 1
print("当前case的完全正确率"+str(successcount/(i+1)))
# 将结果写回Excel文件
resultexcelname=''
df.to_excel(filename.split('.')[0]+now_time+'评测结果.xlsx', index=False)
end_time = time.time()
# 计算执行时间
execution_time = end_time - start_time
print(f"Execution Time: {execution_time} seconds")
if __name__ == "__main__":
main()
9.多线程的作用:
- 提高并发性: 多线程使得程序能够同时执行多个任务,提高了程序的并发性,特别是在多核处理器上。
- 提高响应性: 在图形用户界面(GUI)应用程序中,使用多线程可以确保用户界面的响应性,避免在执行耗时任务时导致界面冻结。
- 资源共享: 不同线程之间可以共享相同进程的资源,如变量、文件句柄等,这样可以方便地在线程之间传递数据。
- 提高资源利用率: 在多核系统上,多线程能够更好地利用多个核心,提高系统资源的利用率。
使用多线程的场景:
耗时任务: 当程序中存在一些需要花费较长时间的任务,如文件 I/O、网络请求等,使用多线程可以避免阻塞主线程,提高整体性能。
GUI应用程序: 在图形用户界面中,使用多线程可以确保用户界面的流畅运行,同时执行后台任务。
并行计算: 对于可以并行计算的任务,如图像处理、数据分析等,多线程能够充分利用多核处理器,提高计算效率。
异步编程: 在异步编程中,多线程常用于处理并发的异步任务,以提高系统的响应性。
服务器应用: 服务器程序通常需要处理多个客户端的请求,使用多线程可以同时处理多个请求,提高服务器的吞吐量。
实时系统: 在一些实时系统中,使用多线程可以保证对时间敏感的任务在规定时间内完成。
展示一个完美的线程的生命周期:
# -- coding: utf-8 --**
import threading
import time
def thread_function():
print("Thread is in the 'Running' state.")
time.sleep(2)
print("Thread is in the 'Blocked' state.")
time.sleep(2)
print("Thread is in the 'Running' state.")
time.sleep(2)
print("Thread is in the 'Terminated' state.")
# 创建线程
my_thread = threading.Thread(target=thread_function)
# 打印线程状态(应该是 'New' 状态)
print(f"Thread is in the '{my_thread.getName()}' state.")
# 启动线程(进入 'Runnable' 状态)
my_thread.start()
# 等待线程完成
my_thread.join()
# 打印线程状态(应该是 'Terminated' 状态)
print(f"Thread is in the '{my_thread.getName()}' state.")
这个代码演示了线程的生命周期,包括创建('New')、就绪('Runnable')、运行('Running')、阻塞('Blocked')和终止('Terminated')等状态。请注意,线程状态可能因操作系统的调度而有所变化,这里的演示仅是一个简单的示例。
在这个例子中,线程 my_thread 在 thread_function 函数中执行,模拟了线程的生命周期不同阶段的状态。在实际应用中,线程的生命周期可能会更复杂,具体取决于任务和线程的交互。
多进程可以利用计算机多核的作用,但是多线程由于GLK的作用,无法实现
下列代码的多线程耗时:
# -- coding: utf-8 --**
import concurrent.futures
import time
start_time=time.time()
PRIMES = [
1116281,
1297337,
104395303,
472882027,
533000389,
817504243,
982451653,
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419
] * 5
def is_prime(n):
"""判断素数"""
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
return False
return n != 1
def main():
"""主函数"""
with concurrent.futures.ThreadPoolExecutor(max_workers=16) as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
end_time = time.time()
# 计算程序执行时间
elapsed_time = end_time - start_time
print('程序执行时间:%f 秒' % elapsed_time) #30.72s
下列代码多进程耗时:
start_time = time.time()
PRIMES = [
1116281,
1297337,
104395303,
472882027,
533000389,
817504243,
982451653,
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419
] * 5
def is_prime(n):
"""判断素数"""
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
return False
return n != 1
def main():
"""主函数"""
with concurrent.futures.ProcessPoolExecutor(max_workers=16) as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
# 记录结束时间
end_time = time.time()
# 计算程序执行时间
elapsed_time = end_time - start_time
print('程序执行时间:%f 秒' % elapsed_time) #程序执行时间:10.08 秒
可以看出多线程耗时是多线程的3倍
10.面向对象编程
问题:什么是面向对象编程,面向对象编程的作用是什么,请列举几个代码例子解释。
面向对象编程(Object-Oriented Programming,简称OOP) 是一种程序设计范式,它以对象为中心,通过封装、继承和多态等机制来组织和设计代码。面向对象编程的目标是提高代码的重用性、可维护性和可扩展性。决于任务和线程的交互。
面向对象编程的主要特征:
封装(Encapsulation): 将数据和操作封装在对象中,通过定义类的成员变量(属性)和方法来实现。封装隐藏了实现的细节,使得对象的内部状态对外部不可见。
继承(Inheritance): 允许一个类(子类)继承另一个类(父类)的属性和方法。继承提供了代码重用的机制,子类可以重用父类的代码,并且可以通过覆盖或扩展来修改其行为。
多态(Polymorphism): 允许使用同样的接口来操作不同的对象,提高了代码的灵活性。多态通过方法重载和方法重写来实现,使得同一个方法在不同的对象上可以有不同的行为。
# 定义一个基类
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
pass
# 定义两个子类继承自基类
class Dog(Animal):
def speak(self):
return f"{self.name} says Woof!"
class Cat(Animal):
def speak(self):
return f"{self.name} says Meow!"
# 创建对象并调用方法
dog = Dog("Buddy")
cat = Cat("Whiskers")
print(dog.speak()) # 输出: Buddy says Woof!
print(cat.speak()) # 输出: Whiskers says Meow!
面向对象编程还涉及到重写内置方法
# -- coding: utf-8 --**
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, other):
return Point(self.x + other.x, self.y + other.y)
# Example
p1 = Point(1, 2)
p2 = Point(3, 4)
result = p1 + p2
print(result.x, result.y) # Output: 4 6
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __sub__(self, other):
return Point(self.x - other.x, self.y - other.y)
# Example
p1 = Point(5, 8)
p2 = Point(2, 3)
result = p1 - p2
print(result.x, result.y) # Output: 3 5
class ComplexNumber:
def __init__(self, real, imag):
self.real = real
self.imag = imag
def __mul__(self, other):
real_part = self.real * other.real - self.imag * other.imag
imag_part = self.real * other.imag + self.imag * other.real
return ComplexNumber(real_part, imag_part)
# Example
c1 = ComplexNumber(2, 3)
c2 = ComplexNumber(1, 4)
result = c1 * c2
print(result.real, result.imag) # Output: -10 11
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"Person(name={self.name}, age={self.age})"
# Example
person = Person("John", 30)
print(str(person)) # Output: Person(name=John, age=30)
11.异步IO
问题:什么是异步IO,异步ID作用是什么,请举代码例子说明
异步 I/O(Asynchronous I/O) 是一种编程模型,其主要目的是在执行 I/O 操作时不阻塞程序的其他任务,从而提高程序的并发性和性能。异步 I/O 通常涉及非阻塞 I/O 操作和事件循环的概念。
异步 I/O 的作用:
提高并发性: 允许程序在进行 I/O 操作时同时执行其他任务,而不必等待 I/O 操作完成。
提高性能: 通过异步执行 I/O 操作,程序可以更充分地利用 CPU 时间,从而提高整体性能。
改善响应性: 在 GUI 应用程序或网络服务中,异步 I/O 可以确保程序对用户请求的响应更加及时。
# -- coding: utf-8 --**
import asyncio
async def async_task(name, delay):
print(f"{name} start")
await asyncio.sleep(delay)
print(f"{name} end after {delay} seconds")
async def main():
# 创建异步任务
task1 = async_task("Task 1", 2)
task2 = async_task("Task 2", 1)
task3 = async_task("Task 3", 3)
# 启动异步任务
await asyncio.gather(task1, task2, task3)
# 运行事件循环
if __name__ == "__main__":
asyncio.run(main())
12数据库的增删改查
问题:python有哪些常见的第三方数据库类库用来操作数据库,操作数据库的例子请列举几个完整代码例子。
# -- coding: utf-8 --**
import sqlite3
# 连接到 SQLite 数据库(如果不存在则创建)
conn = sqlite3.connect('example.db')
# 创建一个游标对象
cursor = conn.cursor()
# 执行 SQL 命令
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
username TEXT,
email TEXT
)
''')
# 插入数据
cursor.execute('INSERT INTO users (username, email) VALUES (?, ?)', ('john_doe', 'john@example.com'))
cursor.execute('INSERT INTO users (username, email) VALUES (?, ?)', ('john_doe2', 'john@example2.com'))
# 提交更改
conn.commit()
# 查询数据
cursor.execute('SELECT * FROM users')
print(cursor.fetchone())
print(cursor.fetchall())
# 关闭连接
conn.close()
操作mysql数据库
import mysql.connector
# 连接到 MySQL 数据库
conn = mysql.connector.connect(
host='localhost',
user='username',
password='password',
database='mydatabase'
)
# 创建一个游标对象
cursor = conn.cursor()
# 执行 SQL 命令
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255),
email VARCHAR(255)
)
''')
# 插入数据
cursor.execute('INSERT INTO users (username, email) VALUES (%s, %s)', ('john_doe', 'john@example.com'))
# 提交更改
conn.commit()
# 查询数据
cursor.execute('SELECT * FROM users')
print(cursor.fetchall())
# 关闭连接
conn.close()
psycopg2操作数据库
import psycopg2
# 连接到 PostgreSQL 数据库
conn = psycopg2.connect(
host='localhost',
user='username',
password='password',
database='mydatabase'
)
# 创建一个游标对象
cursor = conn.cursor()
# 执行 SQL 命令
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
username VARCHAR(255),
email VARCHAR(255)
)
''')
# 插入数据
cursor.execute('INSERT INTO users (username, email) VALUES (%s, %s)', ('john_doe', 'john@example.com'))
# 提交更改
conn.commit()
# 查询数据
cursor.execute('SELECT * FROM users')
print(cursor.fetchall())
# 关闭连接
conn.close()
13.函数式编程
问题:什么是函数式编程,函数式编程的作用是什么,常见的函数式编程有哪些?
函数式编程 是一种编程范式,它将计算视为数学函数的求值,强调使用纯函数和避免可变状态和可变数据。函数式编程的核心思想是将程序分解成小的、可组合的函数,通过组合这些函数来构建更复杂的程序。
函数式编程的主要特点:
纯函数(Pure Functions): 函数的输出仅由输入决定,不依赖于外部状态或副作用。相同的输入总是产生相同的输出,且没有可观察的副作用。
不可变性(Immutable Data): 数据一旦创建就不能被修改。任何修改都是通过创建新的数据完成的,而不是在原始数据上进行。
函数的高阶特性(Higher-Order Functions): 函数可以接受函数作为参数,也可以返回函数。这使得函数可以作为一等公民在代码中使用。
递归(Recursion): 函数式编程鼓励使用递归而不是迭代。递归更符合函数式编程的风格。
不可变性的数据结构(Immutable Data Structures): 使用不可变的数据结构,如元组、列表、集合等,以便更容易进行函数式操作。
函数式编程的作用:
代码简洁:函数式编程通常可以用更简洁的方式表达复杂的逻辑,减少了可变状态和副作用的复杂性。
可维护性:不可变性和纯函数使得代码更容易理解和维护。由于函数没有副作用,更容易调试和测试。
并发和并行性:函数式编程的不可变性和纯函数性质使得并发编程更容易。没有共享的可变状态,更容易实现并行性。
更容易推理:函数式编程的代码更容易进行数学推理,因为它遵循严格的规则和模式。
常见的函数式编程代码例子如下:
# -- coding: utf-8 --**
# 使用 map 函数将列表中的每个元素平方
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
print(squared)
# 使用递归计算阶乘
def factorial(n):
if n == 0 or n == 1:
return 1
else:
return n * factorial(n-1)
print(factorial(5)) # 输出: 120
# 使用元组和集合表示不可变的数据结构
person = ('John', 30)
skills = {'Python', 'JavaScript', 'SQL'}
13.常见的内置模块和第三方模块
math 提供基本的数学运算函数,如加减乘除、三角函数等
random 生成随机数的模块,包括随机数生成和随机选择等
time 处理时间和日期的模块,包括获取当前时间、延时等操作
os 提供与操作系统交互的功能,如文件和目录操作
sys 用于访问 Python 解释器的变量和函数,如命令行参数等
re 正则表达式模块,用于处理字符串匹配和搜索
json 处理 JSON 格式数据的模块,包括解析和生成 JSON 数据
urllib 用于处理 URL 的模块,支持发送 HTTP 请求和处理 URL 编码等
requests 更高级的 HTTP 请求库,简化了发送 HTTP 请求的过程
sqlite3 提供对 SQLite 数据库的访问,支持创建、查询和操作数据库
tkinter Python 的标准 GUI 库,用于创建图形用户界面
collections 提供额外的数据类型,如 OrderedDict、defaultdict 等
itertools 包含创建和操作迭代器的函数,如排列组合、循环等
datetime 处理日期和时间的模块,支持日期算术和日期格式化等
logging 用于记录日志信息的模块,支持不同级别的日志记录
subprocess 启动和控制子进程的模块,可以执行外部命令
threading 提供多线程支持的模块,用于并行执行任务
socket 实现网络通信的模块,支持创建套接字和网络通信
hashlib 提供常见的哈希函数,如 MD5、SHA-1 等
zlib 提供数据压缩和解压的模块
math 提供数学运算函数,如对数、指数、幂运算等
cmath 复数运算的数学模块
platform 获取平台信息的模块,如操作系统、计算机架构等
argparse 解析命令行参数的模块,用于处理命令行输入
csv 处理CSV 文件的模块,支持读写 CSV 格式的数据
pickle 实现 Python 对象的序列化和反序列化
import math
import random
import time
import os
import sys
import re
import json
import urllib.request
import requests
import sqlite3
from tkinter import Tk, Label
from collections import OrderedDict, defaultdict
import itertools
from datetime import datetime
import logging
import subprocess
import threading
import socket
import hashlib
import zlib
import cmath
import platform
import argparse
import csv
import pickle
# 示例函数,使用了不同的内置模块功能
def demo_script():
print("1. Math Module: Square root of 16 =", math.sqrt(16))
print("\n2. Random Module: Random number between 1 and 10 =", random.randint(1, 10))
print("\n3. Time Module: Current time =", time.strftime("%Y-%m-%d %H:%M:%S"))
print("\n4. OS Module: Current working directory =", os.getcwd())
print("\n5. Sys Module: Command line arguments =", sys.argv)
sample_string = "Hello, world! This is a sample string."
pattern = re.compile(r'\b\w{5}\b')
print("\n6. Re Module: Words with 5 characters in the sample string =", pattern.findall(sample_string))
data = {'name': 'John', 'age': 30, 'city': 'New York'}
json_data = json.dumps(data)
print("\n7. JSON Module: JSON representation of data =", json_data)
url = 'https://www.example.com'
response = urllib.request.urlopen(url)
print("\n8. Urllib Module: Response from", url, "=", response.read().decode('utf-8'))
response = requests.get(url)
print("\n9. Requests Module: Status code for", url, "=", response.status_code)
# SQLite3 example
connection = sqlite3.connect(':memory:')
cursor = connection.cursor()
cursor.execute('CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER)')
cursor.execute('INSERT INTO users (name, age) VALUES (?, ?)', ('Alice', 25))
connection.commit()
result = cursor.execute('SELECT * FROM users').fetchall()
print("\n10. SQLite3 Module: Result from SQLite database =", result)
# Tkinter example
root = Tk()
label = Label(root, text="Tkinter Module: Hello, Tkinter!")
label.pack()
root.mainloop()
# Other modules can be similarly demonstrated...
if __name__ == "__main__":
demo_script()
下面列举常见的第三方模块
模块名称 描述
NumPy 提供用于处理大型多维数组和矩阵的数学函数
Pandas 用于数据分析和处理的数据结构和工具
Matplotlib 用于创建图表和绘图的二维绘图库
Requests 更便捷的 HTTP 请求库,简化了发送 HTTP 请求的过程
BeautifulSoup 用于从 HTML 或 XML 中提取数据的库
Scikit-learn 机器学习库,包含多种常用的机器学习算法
TensorFlow 开源的机器学习框架,广泛用于深度学习任务
PyTorch 另一个流行的深度学习框架,提供灵活的张量计算和深度学习支持
Flask 轻量级的 Web 框架,用于构建简单的 Web 应用程序
Django 全功能的 Web 框架,用于构建复杂的 Web 应用程序
SQLAlchemy SQL 工具包和对象关系映射(ORM)框架,简化数据库操作
Celery 分布式任务队列,用于处理异步任务和定时任务
Pillow Python Imaging Library(PIL)的继承版本,用于图像处理
Flask-SQLAlchemy 在 Flask 中使用 SQLAlchemy 的扩展,简化数据库集成
Pygame 用于创建简单的游戏和多媒体应用程序的库
Tweepy 用于访问 Twitter API 的库,简化 Twitter 数据的获取和操作
SQLAlchemy SQL 工具包和对象关系映射(ORM)框架,简化数据库操作
Pyinstaller 将 Python 代码转换为独立可执行文件的工具
Flask-RESTful 用于构建 RESTful API 的 Flask 扩展
Plotly 用于创建交互式图表和可视化的库
# -- coding: utf-8 --**
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
from flask import Flask, render_template
import pandas as pd
def fetch_and_parse_data():
# 使用Requests获取网页内容
url = 'https://example.com'
response = requests.get(url)
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取网页中的数据
data_list = []
for item in soup.find_all('div', class_='data-item'):
data = item.text.strip()
data_list.append(data)
return data_list
def plot_data(data_list):
# 使用Matplotlib创建图表
plt.bar(range(len(data_list)), data_list)
plt.xlabel('Data Points')
plt.ylabel('Values')
plt.title('Data Visualization')
plt.show()
def create_flask_app():
# 使用Flask创建简单的Web应用
app = Flask(__name__)
@app.route('/')
def index():
# 使用Pandas创建数据框
data = {'Category': ['A', 'B', 'C', 'D'],
'Value': [10, 20, 15, 25]}
df = pd.DataFrame(data)
# 使用Flask渲染模板并显示数据框
return render_template('index.html', tables=[df.to_html(classes='data')], titles=df.columns.values)
return app
if __name__ == "__main__":
# 获取、解析数据并绘制图表
data_list = fetch_and_parse_data()
plot_data(data_list)
# 创建Flask应用并运行
app = create_flask_app()
app.run(debug=True)
代码解析:在这个示例脚本中,我们首先使用Requests获取一个网页的内容,然后使用BeautifulSoup解析HTML内容并提取数据。接着,使用Matplotlib创建一个简单的柱状图来可视化提取的数据。最后,使用Flask创建一个简单的Web应用,使用Pandas创建数据框,并在Web页面上显示数据框。
14.网络编程
问题:什么是TCP和UDP,常见的TCP和UDP编程例子有哪些?
TCP(传输控制协议)和UDP(用户数据报协议)是两种不同的传输层协议,用于在计算机网络中传输数据。它们有一些关键的区别:
连接性:TCP是面向连接的协议,提供可靠的、有序的数据传输。在通信之前,需要建立连接,并且在数据传输完成后需要释放连接。
UDP是面向无连接的协议,不需要建立连接,数据包发送者和接收者之间没有直接的关联。因此,UDP比TCP更轻量级。
可靠性:TCP提供可靠的数据传输,确保数据的完整性和有序性。如果数据包丢失或损坏,TCP会重新发送。
UDP不保证可靠性,数据包可能会丢失或按顺序交付。
延迟:TCP通常具有较高的延迟,因为它必须确保数据的可靠传输和有序交付。
UDP具有较低的延迟,适用于实时应用,如音频和视频流。
客户端代码:发送消息给服务端
# -- coding: utf-8 --**
import socket
# 创建TCP客户端
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = ('localhost', 12345)
# 连接到服务器
client_socket.connect(server_address)
# 发送数据
message = "Hello, server!我是客户端"
client_socket.sendall(message.encode('utf-8'))
# 接收响应
data = client_socket.recv(1024)
print("Server response:", data.decode('utf-8'))
# 关闭连接
client_socket.close()
服务端代码:接受客户端的请求并返回数据
# -- coding: utf-8 --**
import socket
# 创建TCP服务器
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = ('localhost', 12345)
server_socket.bind(server_address)
server_socket.listen(1)
print("Waiting for a connection...")
# 接受连接
client_socket, client_address = server_socket.accept()
print("Connection from:", client_address)
# 接收数据
data = client_socket.recv(1024)
print("Received:", data.decode('utf-8'))
# 发送响应
response = "Hello, client!我是服务器"
client_socket.sendall(response.encode('utf-8'))
# 关闭连接
client_socket.close()
server_socket.close()
Udp代码例子:
客户端代码:# -- coding: utf-8 --**
import socket
# 创建UDP客户端
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server_address = ('localhost', 12345)
# 发送数据
message = "Hello, server!"
client_socket.sendto(message.encode('utf-8'), server_address)
# 接收响应
data, server_address = client_socket.recvfrom(1024)
print("Server response:", data.decode('utf-8'))
# 关闭客户端
client_socket.close()
服务端代码:接收信号并返回数据
# -- coding: utf-8 --**
import socket
# 创建UDP服务器
server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server_address = ('localhost', 12345)
server_socket.bind(server_address)
print("Waiting for a message...")
# 接收数据
data, client_address = server_socket.recvfrom(1024)
print("Received:", data.decode('utf-8'))
# 发送响应
response = "Hello, client!"
server_socket.sendto(response.encode('utf-8'), client_address)
# 关闭服务器
server_socket.close()
15.flask编程
问题:什么是flask,flask的作用是什么?列举几个flask代码例子
Flask是一个轻量级的Web应用框架,用于构建Web应用程序和RESTful API。它是一个基于Python的开源框架,设计简单而灵活,使得开发Web应用变得容易。
Flask的主要作用包括:Web应用开发: Flask提供了一种简单而灵活的方式来构建Web应用程序。你可以使用它来定义路由、处理HTTP请求和响应,以及管理模板渲染等。
RESTful API构建: Flask支持构建RESTful API,使得开发和提供API变得简单。通过定义路由和视图函数,你可以轻松地处理API请求和返回相应的数据。
轻量级和灵活: Flask的设计理念是保持轻量级和灵活性。它提供了一些核心功能,同时允许开发者选择和集成其他库和工具。
以下是几个简单的Flask代码例子,展示了不同方面的使用
# -- coding: utf-8 --**
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def home():
return 'Home Page'
@app.route('/user/<username>')
def show_user(username):
return 'User: {}'.format(username)
if __name__ == '__main__':
app.run(debug=True)
16.设计模式
问题:python常用的设计模式有哪些,请举例说明
单例模式(Singleton Pattern):
- 保证一个类只有一个实例,并提供一个全局访问点。
- 例子:在多线程环境中,确保只有一个数据库连接池。
class Singleton:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
return cls._instance
# Usage
singleton1 = Singleton()
singleton2 = Singleton()
print(singleton1 is singleton2) # True
工厂模式(Factory Pattern):
定义一个创建对象的接口,但让子类决定实例化哪个类。工厂方法使一个类的实例化延迟到其子类。
例子:创建一个通用的数据导入工厂,根据文件类型返回相应的数据导入器。
from abc import ABC, abstractmethod
class DataImporter(ABC):
@abstractmethod
def import_data(self, file_path):
pass
class CSVImporter(DataImporter):
def import_data(self, file_path):
print(f"Importing CSV data from {file_path}")
class JSONImporter(DataImporter):
def import_data(self, file_path):
print(f"Importing JSON data from {file_path}")
class DataImportFactory:
def create_importer(self, file_type):
if file_type == 'csv':
return CSVImporter()
elif file_type == 'json':
return JSONImporter()
# Usage
factory = DataImportFactory()
importer = factory.create_importer('csv')
importer.import_data('/path/to/data.csv')
观察者模式(Observer Pattern):
定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象,当主题对象状态发生变化时,它的所有依赖者都会收到通知并更新。
例子:实现一个简单的事件系统,让多个观察者监听事件。
# -- coding: utf-8 --**
class Observer:
def update(self, message):
pass
class ConcreteObserver(Observer):
def update(self, message):
print(f"Received message: {message}")
class Subject:
def __init__(self):
self._observers = []
def add_observer(self, observer):
self._observers.append(observer)
def remove_observer(self, observer):
self._observers.remove(observer)
def notify_observers(self, message):
for observer in self._observers:
observer.update(message)
# Usage
subject = Subject()
observer1 = ConcreteObserver()
observer2 = ConcreteObserver()
subject.add_observer(observer1)
subject.add_observer(observer2)
subject.notify_observers("Event occurred")
代理模式(Proxy Pattern)是一种结构型设计模式,它提供了一个代理对象,用于控制对另一个对象的访问。代理对象充当客户端和实际目标对象之间的中介,可以在访问目标对象时添加一些额外的行为或控制访问。
from abc import ABC, abstractmethod
# 主题接口
class Subject(ABC):
@abstractmethod
def request(self):
pass
# 实际主题
class RealSubject(Subject):
def request(self):
print("RealSubject: Handling request")
# 代理
class Proxy(Subject):
def __init__(self):
self._real_subject = None
def request(self):
if self._real_subject is None:
self._real_subject = RealSubject()
print("Proxy: Handling request before delegating to RealSubject")
self._real_subject.request()
print("Proxy: Handling request after delegating to RealSubject")
# 客户端
def client_code(subject):
subject.request()
# Usage
real_subject = RealSubject()
client_code(real_subject)
proxy = Proxy()
client_code(proxy)
17.python爬虫技术
问题:什么是爬虫,爬虫的作用是什么,列举几个常用的爬虫场景代码
爬虫(Web Scraper)是指通过程序自动访问互联网,并从网页上抓取信息的工具或程序。爬虫主要用于从网页中提取数据,以便后续的分析、处理或存储。其作用包括:
数据采集: 从网页中获取结构化数据,用于分析和处理。
信息监控: 定期检查网站上的变化,获取更新的信息。
搜索引擎: 爬虫是搜索引擎的核心组成部分,通过爬取网页内容建立搜索引擎的索引。
数据验证: 检查网站上的链接、图像等,确保其有效性和完整性。
自动化测试: 对网站进行功能、性能等方面的测试,提高开发和维护效率。
列举几个爬虫的代码例子:
# -- coding: utf-8 --**
from bs4 import BeautifulSoup
html_content = '<html><body><p>Hello, World!</p></body></html>'
soup = BeautifulSoup(html_content, 'html.parser')
print(soup.p.text)
Python如何爬取最近的股价
爬取豆瓣网站中电影排名:电影名称和评分,保存在excel:
# -- coding: utf-8 --**
import requests
from bs4 import BeautifulSoup
import pandas as pd
def scrape_douban_movies():
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
}
response = requests.get(url, headers=headers)
print(response)
soup = BeautifulSoup(response.text, 'html.parser')
movies = []
for movie_div in soup.find_all('div', class_='hd'):
title = movie_div.a.span.text.strip()
rating_div = movie_div.find_next('div', class_='star')
rating = rating_div.find('span', class_='rating_num').text.strip()
movies.append({'Title': title, 'Rating': rating})
print(movies)
return movies
def save_to_excel(movies, filename='douban_movies.xlsx'):
df = pd.DataFrame(movies)
df.to_excel(filename, index=False)
print(f'Data has been saved to {filename}.')
if __name__ == '__main__':
movies_data = scrape_douban_movies()
save_to_excel(movies_data)
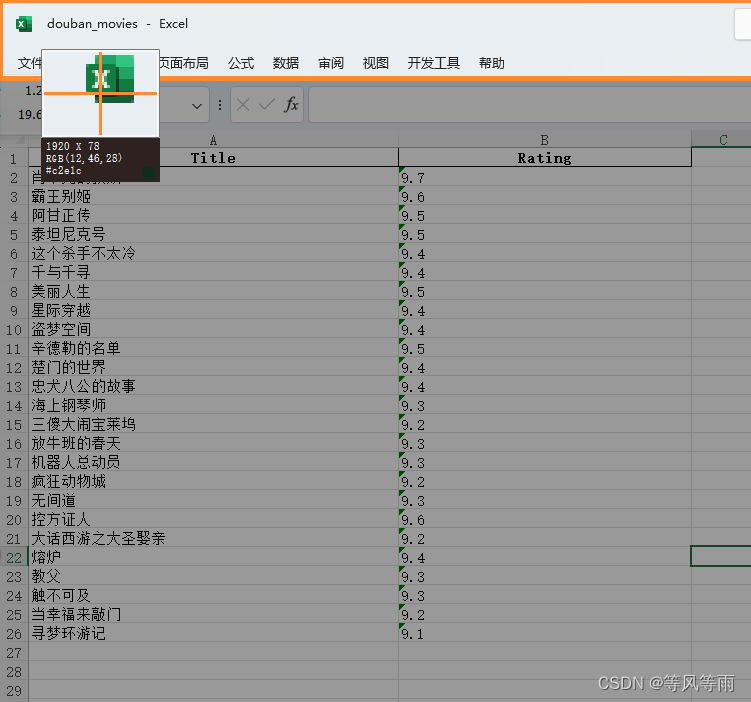
18.python中如何操作git
问题:git常用的操作命令有哪些,python如何自动操作git,请列举几个例子来说明
基本操作:
git init: 初始化一个新的Git仓库。
git clone <repository>: 克隆一个远程仓库到本地。
git add <file>: 将文件添加到暂存区。
git commit -m "message": 提交暂存区的文件到版本库。
分支操作:
git branch: 列出本地分支。
git checkout -b <branch_name>: 创建并切换到新分支。
git merge <branch_name>: 合并指定分支到当前分支。
git branch -d <branch_name>: 删除本地分支。
远程操作:
git remote -v: 查看远程仓库信息。
git pull origin <branch_name>: 从远程仓库拉取最新代码。
git push origin <branch_name>: 推送本地代码到远程仓库。
查看状态和历史:
git status: 查看工作区和暂存区的状态。
git log: 查看提交历史。
git diff: 查看工作区和暂存区的差异。
Python可以通过subprocess模块来执行Shell命令,从而实现自动化Git操作。
以下是一些示例代码:
import subprocess
subprocess.run(['git', 'init'])
subprocess.run(['git', 'add', '.'])
subprocess.run(['git', 'commit', '-m', '"Initial commit"'])
subprocess.run(['git', 'remote', 'add', 'origin', 'https://github.com/yangyangwithgnu/Python-Study.git'])
subprocess.run(['git', 'push', '-u', 'origin', 'master'])
import subprocess
repo_url = 'https://github.com/example/repo.git'
subprocess.run(['git', 'clone', repo_url])
import subprocess
subprocess.run(['git', 'add', 'file.txt'])
subprocess.run(['git', 'commit', '-m', 'Commit message'])
subprocess.run(['git', 'push', 'origin', 'master'])
import subprocess
subprocess.run(['git', 'pull', 'origin', 'master'])
subprocess.run(['git', 'push', 'origin', 'master'])
19.python操作办公软件excel和word
问题:python如何自动操作办公软件excel和word
操作excel
import openpyxl
# 打开Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
# 选择工作表
sheet = workbook['Sheet1']
# 读取单元格内容
cell_value = sheet['A1'].value
print(cell_value)
写入excel
import openpyxl
# 创建新的Excel文件
workbook = openpyxl.Workbook()
# 选择工作表
sheet = workbook.active
# 写入数据到单元格
sheet['A1'] = 'Hello'
sheet['B1'] = 'World'
# 保存文件
workbook.save('new_example.xlsx')
创建和写入word
from docx import Document
# 创建新的Word文档
doc = Document()
# 添加段落
doc.add_paragraph('Hello, World!')
# 添加标题
doc.add_heading('Document Title', level=1)
# 保存文件
doc.save('example.docx')
读取word文件
from docx import Document
# 打开Word文档
doc = Document('example.docx')
# 读取段落内容
for paragraph in doc.paragraphs:
print(paragraph.text)
20.numpy和pandas用法
NumPy是Python中用于科学计算的核心库之一。它提供了高性能的多维数组对象(numpy.ndarray)以及对这些数组进行操作的各种函数。以下是一些使用NumPy的常见场景,每个场景都有相应的完整代码例子:
# -- coding: utf-8 --**
import numpy as np
# 创建一维数组
arr1 = np.array([1, 2, 3])
# 创建二维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr1)
print(arr2)
arr = np.array([1, 2, 3])
# 数组加法
result = arr + 1
print(result)
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 获取数组形状
shape = arr.shape
# 获取数组大小
size = arr.size
print("形状:", shape)
print("大小:", size)
arr = np.array([1, 2, 3, 4, 5])
# 数组索引
value = arr[2]
# 数组切片
subset = arr[1:4]
print("索引:", value)
print("切片:", subset)
arr = np.array([1, 2, 3, 4, 5])
# 计算数组均值
mean_value = np.mean(arr)
# 计算数组标准差
std_dev = np.std(arr)
print("均值:", mean_value)
print("标准差:", std_dev)
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
# 数组加法
result = arr1 + arr2
print(result)
arr = np.array([1, 2, 3, 4, 5])
# 条件筛选
filtered_arr = arr[arr > 2]
print(filtered_arr)
# 生成随机整数数组
random_arr = np.random.randint(1, 10, size=(3, 3))
print(random_arr)
Pandas 是一个强大的数据分析和操作库,提供了高性能、易用的数据结构,特别是 DataFrame,用于处理和分析结构化数据。以下是使用 Pandas 的 10 个完整代码例子,展示其主要功能:
# -- coding: utf-8 --**
import pandas as pd
# 从字典创建 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]}
df = pd.DataFrame(data)
print(df)
import pandas as pd
# 创建 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 选择列
ages = df['Age']
# 使用条件选择行
selected_rows = df[df['Age'] > 30]
print(ages)
print(selected_rows)
import pandas as pd
# 创建 DataFrame
data = {'Height': [160, 175, 180, 155, 165],
'Weight': [50, 70, 80, 45, 55]}
df = pd.DataFrame(data)
# 统计描述
stats = df.describe()
print(stats)
import pandas as pd
# 创建两个 DataFrame
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Charlie']})
df2 = pd.DataFrame({'ID': [2, 3, 4], 'Age': [25, 30, 35]})
# 使用键合并两个 DataFrame
merged_df = pd.merge(df1, df2, on='ID', how='inner')
print(merged_df)
21.python 操作linux命令
Python在linux环境中如何操作linux命令
import subprocess
# 执行 ls 命令
result = subprocess.run(['ls', '-l'], stdout=subprocess.PIPE, text=True)
# 输出命令结果
print(result.stdout)
import subprocess
# 执行 pwd 命令
result = subprocess.run(['pwd'], stdout=subprocess.PIPE, text=True)
# 获取命令输出
current_directory = result.stdout.strip()
print(f"当前工作目录: {current_directory}")
import subprocess
# 执行 mkdir 命令创建目录
directory_name = 'new_directory'
subprocess.run(['mkdir', directory_name])
print(f"已创建目录: {directory_name}")
比较常用的linux命令如下:
| 命令 | 描述 |
| find /path/to/search -name "pattern" | 在指定路径中按名称查找文件,支持通配符 |
| grep "pattern" file | 在文件中搜索指定模式的文本 |
| awk '{print $1}' file | 使用 AWK 提取文件中的第一列数据 |
| sed 's/old/new/g' file | 使用SED替换文件中的文本 |
| tar -czvf archive.tar.gz /path/to/dir | 创建压缩的 tar 存档文件 |
| tar -xzvf archive.tar.gz | 解压缩 tar 存档文件 |
| curl -O URL | 从 URL 下载文件并保存到当前目录 |
| wget URL | 从 URL 下载文件并保存到当前目录 |
| `ps aux | grep "process"` |
| kill -9 PID | 强制终止指定进程 |
| du -h --max-depth=1 /path | 以人类可读的方式显示指定路径的目录大小 |
| df -h | 以人类可读的方式显示文件系统使用情况 |
| tail -n 10 file | 显示文件的最后 10 行 |
| head -n 10 file | 显示文件的前 10 行 |
| `history | grep "command"` |
| scp user@remote:/path/to/file /local/dir | 从远程主机复制文件到本地目录 |
| scp /local/file user@remote:/path/to/dir | 从本地主机复制文件到远程目录 |
| ssh user@remote | 通过 SSH 连接到远程主机 |
| rsync -avz /source/ user@remote:/destination/ | 使用 rsync 同步本地和远程目录 |
| chmod +x script.sh | 使脚本具有执行权限 |
| chown user:group file | 更改文件的所有者和组 |
| diff file1 file2 | 比较两个文件的内容 |
| echo "text" > file | 将文本写入文件(覆盖文件内容) |
| echo "text" >> file | 将文本追加到文件末尾 |
| scp -r user@remote:/path/to/dir /local/dir | 递归复制远程目录到本地目录 |
| rsync -avz --delete /source/ user@remote:/destination/ | 同步并删除远程目录中不存在的文件 |
| sort file | 对文件的内容进行排序 |
| uniq file | 去除文件中的重复行 |
| watch -n 1 command | 每秒执行一次指定命令,并显示输出 |
| ping -c 4 host | 发送 4 个 ICMP 请求到主机并显示结果 |
| traceroute host | 显示数据包从本地到主机的路径 |
| lsof -i :port | 列出占用指定端口的进程信息 |
| netstat -tuln | 列出所有监听的网络端口 |
| ip addr show | 显示所有网络接口的 IP 地址 |
| route -n | 显示 IP 路由表 |
| uname -a | 显示系统信息,包括内核版本、系统架构等 |
| free -m | 显示系统内存使用情况 |
| uptime | 显示系统的运行时间和平均负载 |
| journalctl -xe | 查看系统日志和错误消息 |
| ps -ef | 显示系统中运行的所有进程的详细信息 |
| scp -r user@remote:/path/to/dir /local/dir | 递归复制远程目录到本地目录 |
| rsync -avz --delete /source/ user@remote:/destination/ | 同步并删除远程目录中不存在的文件 |
22.python操作shell脚本
import subprocess
# 执行 ls 命令
result = subprocess.run(['ls', '-l'], stdout=subprocess.PIPE, text=True)
# 输出命令结果
print(result.stdout)
import subprocess
# 执行 pwd 命令
result = subprocess.run(['pwd'], stdout=subprocess.PIPE, text=True)
# 获取命令输出
current_directory = result.stdout.strip()
print(f"当前工作目录: {current_directory}")
import subprocess
# 执行 mkdir 命令创建目录
directory_name = 'new_directory'
subprocess.run(['mkdir', directory_name])
print(f"已创建目录: {directory_name}")
import subprocess
# 执行一个简单的Shell脚本
subprocess.run('./sxf.sh', shell=True)
import subprocess
# 传递参数给Shell脚本
param1 = '-l'
param2 = '-ll'
subprocess.run(['./sxf.sh', param1, param2], shell=True)
import subprocess
# 获取Shell脚本的输出
result = subprocess.run('./sxf.sh', shell=True, stdout=subprocess.PIPE, text=True)
# 输出Shell脚本的结果
print(result.stdout)
import subprocess
# 执行Shell脚本并获取返回值
result = subprocess.run('./sxf.sh', shell=True, stdout=subprocess.PIPE, text=True)
# 检查返回值
if result.returncode == 0:
print("Shell脚本执行成功")
else:
print(f"Shell脚本执行失败,返回值: {result.returncode}")
23.python 定时执行自动化测试脚本
import schedule
import time
import subprocess
def run_test_script():
print("Running automated test script...")
# 替换为你的测试脚本的路径
script_path = '/path/to/test_script.py'
# 使用 subprocess 调用测试脚本
subprocess.run(['python', script_path])
# 使用 schedule 库设定每天定时执行测试脚本的任务
schedule.every().day.at("10:00").do(run_test_script)
while True:
# 运行 schedule 任务
schedule.run_pending()
time.sleep(1)
# -- coding: utf-8 --**
import time
import subprocess
def run_test_script():
print("Running automated test script...")
subprocess.run(['python', '/path/to/test_script.py'])
while True:
current_time = time.localtime()
if current_time.tm_hour == 18 and current_time.tm_min == 16:
run_test_script()
break
time.sleep(6) # 等待一分钟后重新检查
from croniter import croniter
import time
import subprocess
def run_test_script():
print("Running automated test script...")
subprocess.run(['python', '/path/to/test_script.py'])
cron = croniter("19 18 * * *") # 每天10:00执行测试脚本
while True:
current_time = time.time()
next_run = cron.get_next(float)
if current_time >= next_run:
run_test_script()
else:
time.sleep(next_run - current_time)
24.常见的题目
数据类型和数据结构:
问题: 列举 Python 中常见的数据类型。
答案: 整数(int)、浮点数(float)、字符串(str)、列表(list)、元组(tuple)、集合(set)、字典(dict)等。
问题: 什么是列表、元组、集合和字典?它们之间有何区别?
答案: 列表是可变的有序序列,元组是不可变的有序序列,集合是无序且元素唯一的集合,字典是无序的键值对集合。
问题: 说一下 Python 中的字符串格式化方法。
答案: 字符串格式化有多种方式,包括使用 % 操作符、format() 方法和 f-string(Python 3.6+的新特性)。
面向对象编程(OOP):
问题: 什么是面向对象编程?Python 如何支持面向对象编程?
答案: 面向对象编程是一种编程范式,其中数据和功能被组织为对象。Python支持面向对象编程,包括类、对象、封装、继承和多态。
问题: 解释一下封装、继承和多态。
答案: 封装是将数据和方法封装在一个类中;继承是一个类可以继承另一个类的属性和方法;多态是同一种操作可以在不同的类中表现出不同的行为。
问题: Python中的 __init__ 方法有什么作用?
答案: __init__ 方法是一个特殊的方法,用于初始化对象的属性。它在对象创建时自动调用。
异常处理:
问题: 什么是异常?Python 中如何处理异常?
答案: 异常是程序执行过程中的错误。Python 使用 try...except 语句来处理异常,通过捕获并处理异常可以避免程序终止。
问题: 有哪些常见的内置异常?
答案: 包括 SyntaxError、TypeError、ZeroDivisionError、FileNotFoundError 等。
问题: 什么是 try...except 语句,以及它的使用方式?
答案: try...except 语句用于捕获和处理异常。在 try 代码块中放置可能引发异常的代码,然后在 except 代码块中处理异常。
模块和包:
问题: 什么是模块和包?它们有什么区别?
答案: 模块是包含 Python 代码的文件,包是包含多个模块的目录。包中必须包含一个 __init__.py 文件。
问题: 如何导入模块?有哪些常见的导入方式?
答案: 使用 import 关键字导入模块。常见的导入方式包
问题: 解释一下 Python 中的 == 和 is 的区别。
答案: == 用于比较对象的值是否相等,而 is 用于比较对象的身份标识是否相等,即对象是否是同一个实例。
问题: 什么是 Python 中的列表推导(List Comprehension)?
答案: 列表推导是一种用简洁语法创建列表的方法,通常使用一行代码即可完成。
问题: 解释一下 Python 的装饰器是什么,以及如何使用?
答案: 装饰器是一种用于修改或扩展函数或方法行为的语法。使用 @decorator 语法可以将装饰器应用于函数或方法。
数据类型和数据结构:
问题: 什么是 Python 中的生成器(Generator)?如何创建一个生成器?
答案: 生成器是一种特殊的迭代器,可以通过函数中的 yield 关键字创建。它允许按需生成值,而不是一次性生成所有值。
问题: 什么是 Python 中的集合(Set)?举例说明集合的常见操作。
答案: 集合是一个无序且元素唯一的数据结构。常见操作包括添加元素、移除元素、交集、并集、差集等。
问题: Python 中的字典(Dictionary)有什么特点?如何遍历字典?
答案: 字典是一种键值对映射的数据结构,具有高效的查找速度。可以使用 for key, value in my_dict.items() 进行遍历。
面向对象编程(OOP):
问题: 什么是 Python 中的多重继承?
答案: 多重继承是指一个类可以继承自多个父类。在 Python 中,一个类可以通过在类定义时指定多个父类来实现多重继承。
问题: 解释一下 Python 中的 super() 函数的作用。
答案: super() 函数用于调用父类的方法,通常在子类中使用,以确保正确调用继承的方法。
问题: Python 中的抽象类和接口有何区别?
答案: 抽象类是包含抽象方法的类,不能直接实例化;接口是一种规范,用于定义类应该实现哪些方法,Python 中通常使用抽象基类来表示接口。
异常处理:
问题: 什么是 Python 中的异常处理机制?举例说明如何使用 try...except 语句。
答案: 异常处理用于处理程序运行时的错误。try...except 语句允许捕获并处理异常。
问题: Python 中的 finally 关键字的作用是什么?
答案: finally 关键字用于定义在无论是否发生异常时都会执行的代码块。
问题: 什么是自定义异常?如何创建一个自定义异常类?
答案: 自定义异常是通过继承内置的 Exception 类来创建的。可以定义自己的异常类以处理特定的错误情况。
模块和包:
问题: 什么是 Python 模块?如何导入模块?
答案: 模块是包含 Python 代码的文件,可以使用 import 关键字导入模块。
问题: Python 中的包是什么?如何组织一个包?
答案: 包是包含多个模块的目录,其中必须包含一个 __init__.py 文件。可以通过导入子模块来组织一个包。
问题: Python 中的命名空间是什么?如何解决命名冲突?
答案: 命名空间是指变量名和对象之间的映射关系。可以通过给变量或对象添加前缀、使用模块来创建不同的命名空间来解决命名冲突。L(全局解释器锁)是一种机制,它确保在同一时刻只有一个线程在执行 Python 字节码。这会对多线程程序的性能产生影响,因为同一时间只有一个线程能够执行 Python 代码。
问题: 说一下 Python 的垃圾回收机制。
答案: Python使用自动垃圾回收机制,主要基于引用计数和循环垃圾回收。引用计数用于跟踪对象的引用情况,当引用计数变为零时,对象被销毁。循环垃圾回收则用于检测并清除循环引用的对象。
问题: Python 中的可变对象和不可变对象有什么区别?
答案: 可变对象的值可以在创建后被修改,而不可变对象的值在创建后不能被修改。例如,列表是可变的,而元组是不可变的。
问题: 解释一下 Python 中的装饰器是什么,以及如何使用?
答案: 装饰器是一种用于修改或扩展函数或方法行为的语法。它可以通过 @decorator 语法应用于函数或方法,用于简化代码结构。
问题: Python 中的 __init__ 和 __new__ 方法有什么区别?
答案: __new__ 方法用于创建一个新实例,而 __init__ 方法用于初始化实例。通常情况下,不需要重写 __new__ 方法,而 __init__ 方法是常见的初始化方法。
数据类型和数据结构:
问题: 什么是 Python 中的生成器表达式?与列表推导有何不同?
答案: 生成器表达式是一种用于创建生成器的简洁语法,与列表推导不同的是,生成器表达式使用圆括号而不是方括号,生成器表达式是惰性计算的,它只在需要时产生值。
问题: 解释一下 Python 中的深拷贝和浅拷贝的区别。
答案: 浅拷贝创建一个新对象,然后将原始对象中的元素复制到新对象中,但不会递归复制嵌套对象。深拷贝创建一个新对象,同时递归复制原始对象及其嵌套对象。
问题: 什么是 Python 中的迭代器和可迭代对象?
答案: 可迭代对象是具有 __iter__ 方法的对象,而迭代器是实现了 __iter__ 和 __next__ 方法的对象。迭代器可以用于按需生成值的序列。
面向对象编程(OOP):
问题: 什么是 Python 中的元类(metaclass)?
答案: 元类是用于定义类的类。在 Python 中,可以通过定义元类来定制类的创建和行为。
问题: 解释一下 Python 中的 MRO(方法解析顺序)是什么?
答案: MRO 是指在多继承中确定方法调用顺序的规则。在 Python 中,可以通过类的 __mro__ 属性查看方法解析顺序。
问题: Python 中的 __slots__ 属性有什么作用?
答案: __slots__ 属性用于限制类实例的属性,只允许定义在 __slots__ 中的属性。这有助于减小实例的内存占用。
异常处理:
问题: Python 中的 try...except...else 语句的执行流程是怎样的?
答案: try 代码块中的语句将被执行,如果没有异常抛出,则执行 else 代码块中的语句,如果有异常,则执行 except 代码块中的语句。
问题: 什么是上下文管理器(Context Manager)?如何使用 with 语句创建上下文管理器?
答案: 上下文管理器是实现了 __enter__ 和 `__exit
问题: 解释一下 Python 中的 __init__ 和 __call__ 方法。
答案: __init__ 方法用于初始化对象,而 __call__ 方法使对象可调用。当实例被调用时,__call__ 方法会被调用。
问题: Python 中的 *args 和 **kwargs 的作用是什么?
答案: *args 用于传递不定数量的非关键字参数,而 **kwargs 用于传递不定数量的关键字参数。
问题: 什么是 Python 中的迭代器和生成器?
答案: 迭代器是具有 __iter__ 和 __next__ 方法的对象,用于按需生成值的序列。生成器是一种创建迭代器的简便方式,使用 yield 语句生成值。
数据类型和数据结构:
问题: Python 中的 collections 模块提供了哪些常见的数据结构?
答案: collections 模块提供了诸如 Counter、defaultdict、OrderedDict 等常见的数据结构。
问题: 什么是列表推导(List Comprehension)?举例说明如何使用。
答案: 列表推导是一种用于创建列表的简洁语法,可以在一行代码中生成列表。例如:[x**2 for x in range(5)]。
问题: Python 中的 map 和 filter 函数有什么作用?
答案: map 用于对可迭代对象的每个元素应用函数,返回一个迭代器。filter 用于筛选可迭代对象中满足条件的元素,返回一个迭代器。
面向对象编程(OOP):
问题: 什么是 Python 中的元类(metaclass)?
答案: 元类是用于定义类的类,允许在创建类时定制类的创建和行为。
问题: 解释一下 Python 中的多重继承。
答案: 多重继承是指一个类可以继承自多个父类。在类定义时,可以通过逗号分隔指定多个父类。
问题: Python 中的装饰器有什么作用?如何定义一个装饰器?
答案: 装饰器是用于修改或扩展函数或方法行为的语法。可以通过定义一个函数,并使用 @decorator 语法应用于其他函数或方法来创建装饰器。
异常处理:
问题: Python 中 try...except...else...finally 的执行流程是怎样的?
答案: try 代码块中的语句将被执行,如果没有异常抛出,则执行 else 代码块中的语句,最后无论是否有异常都会执行 finally 代码块中的语句。
问题: 什么是上下文管理器(Context Manager)?如何使用 with 语句创建上下文管理器?
答案: 上下文管理器是通过实现 __enter__ 和 __exit__ 方法的对象,用于定义一段代码的前后操作。可以通过 with 语句使用上下文管理器,确保在代码块执行前后进行相应的操作。
问题: Python 中的自定义异常是如何定义的?
答案: 自定义异常是通过创建一个继承自内置的 Exception 类的新类来定义的。可以在新类中添加额外的属性和方法以处理特定的异常情况。
模块和包:
问题: Python 中的模块和包有什么区别?
答案: 模块是包含 Python 代码的文件,而包是包含多个模块的目录。包中必须包含
问题: Python 中的深拷贝和浅拷贝有何区别?
答案: 浅拷贝创建一个新对象,然后将原始对象中的元素复制到新对象中,但不会递归复制嵌套对象。深拷贝创建一个新对象,同时递归复制原始对象及其嵌套对象。
问题: Python 中的 __str__ 和 __repr__ 方法有何区别?
答案: __str__ 用于返回对象的用户友好的字符串表示,而 __repr__ 用于返回对象的官方字符串表示,通常包含用于重建对象的有效 Python 表达式。
问题: 什么是 Python 中的闭包(Closure)?
答案: 闭包是指一个函数对象,它引用了在函数定义体外部定义的变量。闭包允许在函数内访问外部作用域的变量,即使这些变量在函数调用时已经不存在。
数据类型和数据结构:
问题: Python 中的 set 和 frozenset 有什么区别?
答案: set 是可变的,而 frozenset 是不可变的。因此,set 可以在创建后进行修改,而 frozenset 不能。
问题: 什么是 Python 中的迭代器协议?
答案: 迭代器协议是指实现 __iter__ 和 __next__ 方法的对象协议。通过迭代器协议,对象可以按照迭代器的方式逐个返回元素。
问题: 解释一下 Python 中的 zip 函数的用途。
答案: zip 函数用于将多个可迭代对象组合成一个元组序列。它返回一个迭代器,每个元素都是输入可迭代对象中对应位置的元组。
面向对象编程(OOP):
问题: Python 中的装饰器有何作用?能否给出一个装饰器的例子?
答案: 装饰器是用于修改或扩展函数或方法行为的语法。一个简单的装饰器例子是计时器,用于测量函数执行时间。
问题: 什么是 Python 中的元类(metaclass)?为何要使用元类?
答案: 元类是用于定义类的类。元类可以在创建类时动态修改类的行为,允许在类级别进行高级定制。
问题: Python 中的 GIL(全局解释器锁)是什么?它有什么影响?
答案: GIL是一种全局锁,防止多线程同时执行Python字节码。这导致在多核系统上,Python 多线程程序的并行性受到限制,因为同一时刻只允许一个线程执行。
异常处理:
问题: Python 中的 assert 语句有什么作用?在什么情况下使用?
答案: assert 用于在代码中加入调试断言。如果 assert 后面的条件为假,将引发 AssertionError 异常。通常用于在代码中插入调试语句。
问题: Python 中的上下文管理器有何作用?如何实现一个上下文管理器?
答案: 上下文管理器用于在代码块执行前后进行一些操作。可以通过定义一个类,并在其中实现 __enter__ 和 __exit__ 方法来创建上下文管理器。
问题: 什么是 Python 中的自定义异常?如何抛出异常?
答案: 自定义异常是通过创建一个继承自内置的 Exception 类的新类来定义的。可以使用 raise 语句抛出异常。
模块和包:
问题: Python 中的 __init__.py 文件有什么作用?
答案: __init__.py 文件用于指示目录是一个 Python 包。在 Python 3.3+ 中,可以为空文件,但在旧版本中,通常包含初始化包的代码。
问题: 解释一下 Python 的相对导入是如何工作的?
答案: 相对导入是指在包内部使用相对路径来导入模块。例如,from .module import something。相对导入只在包内有效。
问题: 什么是 Python 中的装饰器?请详细说明装饰器的原理和使用场景。
答案: 装饰器是一种高级特性,允许在不修改原函数代码的情况下,通过在其上添加额外的功能。装饰器本质上是一个函数,它接受一个函数作为参数,并返回一个新的函数。原理涉及到函数闭包和函数作为第一类对象。常见的使用场景包括日志记录、性能分析、权限验证等。
问题: 什么是生成器(Generator)?与普通函数有什么不同?
答案: 生成器是一种特殊的迭代器,使用 yield 语句生成值,而不是一次性生成所有值。生成器函数的执行状态会在每次调用 yield 时保存,下次调用时会从上次的状态继续执行,这使得生成器对于处理大量数据或无限序列非常高效。
问题: 什么是 Python 中的闭包(Closure)?能否举例说明闭包的应用场景?
答案: 闭包是指包含对自由变量引用的函数对象。闭包允许函数捕获并维持其创建时可见的作用域,即使在函数外部调用时仍然有效。一个常见的闭包应用场景是在函数内部定义一个函数,并返回该函数,用于实现函数工厂或延迟执行。
并发和多线程:
问题: Python 中的 GIL(全局解释器锁)是什么?它对多线程程序有何影响?
答案: GIL是一种全局锁,防止多线程同时执行Python字节码。这导致在多核系统上,Python 多线程程序的并行性受到限制,因为同一时刻只允许一个线程执行。GIL对CPU密集型任务影响较大,但对I/O密集型任务的影响相对较小。
问题: 什么是线程安全(Thread Safety)?在 Python 中如何实现线程安全?
答案: 线程安全是指多线程环境下,某个函数或对象的操作不会导致不一致的结果。在 Python 中,可以使用锁(Locks)来保护共享资源,确保在任何时刻只有一个线程可以访问。
问题: Python 中有哪些处理并发的模块和库?请简要介绍一下。
答案: Python 中的一些处理并发的模块和库包括 threading 模块(多线程编程)、multiprocessing 模块(多进程编程)、asyncio 模块(异步编程)、以及第三方库如 concurrent.futures、gevent、Twisted 等。
异步编程和协程:
问题: 什么是异步编程?Python 中的 asyncio 模块是如何实现异步编程的?
答案: 异步编程是一种编程范式,旨在处理大量的并发任务,而无需为每个任务创建新的线程或进程。asyncio 模块使用协程(coroutines)和事件循环(event loop)来实现异步编程,允许在一个线程中处理大量并发任务。
问题: 什么是 Python 中的协程(Coroutine)?与生成器有何不同?
答案: 协程是一种轻量级的线程,允许在函数中暂停和恢复执行。与生成器不同的是,协程可以在每次暂停时向其发送值,并从中接收值,实现更灵活的协作式多任务。
问题: Python 中的 async 和 await 关键字的作用是什么?
答案: async 用于定义协程函数,而 await 用于暂停协程的执行,等待异步操作完成。这两个关键字通常一起使用来编写异步代码。
Web 开发和框架:
问题: 什么是 Flask 框架?它与 Django 有何区别?
答案: Flask 是一个轻量级的 Web 框架,专注于简洁和灵活。与 Django 相比,Flask更灵活,允许开发者自由选择数据库、模板引擎等组件,适用于中小型项目和快速原型开发。
问题: 什么是 Django 框架中的 ORM?有什么优势?
答案: Django 中的 ORM(Object-Relational Mapping)是一种将数据库表映射到 Python 对象的技术。它允许开发者使用 Python 代码而不是 SQL 查询语言来操作数据库,提高了代码的可读性和可维护性。ORM的优势包括抽象数据库细节、提高代码复用性、减少代码量等。
问题: 什么是 RESTful API?如何在 Python 中实现 RESTful API?
答案: RESTful API 是一种设计风格,基于 HTTP 协议,使用标准的 HTTP 方法(GET、POST、PUT
25.常見的算法題
# -- coding: utf-8 --**
#两数之和:问题: 给定一个整数数组和一个目标值,找出数组中和为目标值的两个数
def two_sum(nums, target):
num_dict = {}
for i, num in enumerate(nums):
complement = target - num
if complement in num_dict:
return [num_dict[complement], i]
num_dict[num] = i
return None
# Example usage:
nums = [2, 7, 11, 15]
target = 9
result = two_sum(nums, target)
print(result) # Output: [0, 1]
#反转一个单链表
class ListNode:
def __init__(self, value=0, next=None):
self.value = value
self.next = next
def reverse_linked_list(head):
prev, current = None, head
while current:
next_node = current.next
current.next = prev
prev = current
current = next_node
return prev
# Example usage:
# Assuming 1 -> 2 -> 3 -> 4 -> 5 is the linked list
linked_list = ListNode(1, ListNode(2, ListNode(3, ListNode(4, ListNode(5)))))
reversed_list = reverse_linked_list(linked_list)
while reversed_list.next:
print(reversed_list.value)
reversed_list = reversed_list.next
#字符串转化成整数
def atoi(s):
s = s.strip()
if not s:
return 0
sign = 1
i = 0
if s[0] in ['+', '-']:
sign = -1 if s[0] == '-' else 1
i = 1
result = 0
max_int, min_int = 2**31 - 1, -2**31
while i < len(s) and s[i].isdigit():
digit = int(s[i])
if result > (max_int - digit) // 10:
return max_int if sign == 1 else min_int
result = result * 10 + digit
i += 1
return sign * result
# Example usage:
string_num = " -42"
integer_num = atoi(string_num)
print(integer_num) # Output: -42
#有效的括号:问题: 给定一个只包括 '('、')'、'{'、'}'、'['、']' 的字符串,判断字符串是否有效。
def is_valid_parentheses(s):
stack = []
brackets = {')': '(', '}': '{', ']': '['}
for char in s:
if char in brackets.values():
stack.append(char)
elif char in brackets.keys():
if not stack or stack.pop() != brackets[char]:
return False
else:
return False
return not stack
# Example usage:
parentheses_str = "{[()]}";
result = is_valid_parentheses(parentheses_str)
print(result) # Output: True
#找出字符串的最长回文子串
def longest_palindrome(s):
def expand_around_center(left, right):
while left >= 0 and right < len(s) and s[left] == s[right]:
left -= 1
right += 1
return s[left + 1:right]
longest = ""
for i in range(len(s)):
palindrome1 = expand_around_center(i, i)
palindrome2 = expand_around_center(i, i + 1)
palindrome = palindrome1 if len(palindrome1) > len(palindrome2) else palindrome2
if len(palindrome) > len(longest):
longest = palindrome
return longest
# Example usage:
input_str = "babad"
result = longest_palindrome(input_str)
print(result) # Output: "bab" or "aba"
#合并两个有序链表,新合并的链表也有序
class ListNode:
def __init__(self, value=0, next=None):
self.value = value
self.next = next
def merge_sorted_lists(l1, l2):
dummy = ListNode()
current = dummy
while l1 and l2:
if l1.value < l2.value:
current.next = l1
l1 = l1.next
else:
current.next = l2
l2 = l2.next
current = current.next
current.next = l1 or l2
return dummy.next
# Example usage:
# Assuming l1: 1 -> 3 -> 5 and l2: 2 -> 4 -> 6
merged_list = merge_sorted_lists(ListNode(1, ListNode(3, ListNode(5))),
ListNode(2, ListNode(4, ListNode(6))))
print(merged_list)
26.Pytest和unittest
unittest: unittest 遵循了 xUnit 风格的测试框架,其测试用例继承自 unittest.TestCase 类,测试方法以 test_ 开头。
pytest: pytest 使用更简洁的语法,不需要继承特定的基类。测试用例可以是简单的函数,而测试方法的命名不需要特定的前缀。
断言:unittest: 使用 self.assertEqual()、self.assertTrue() 等断言方法来验证测试条件。
pytest: 使用 Python 的内置断言语句 assert,不需要使用特定的断言方法。
自动发现和运行测试:
unittest: 需要在测试文件中定义测试类和测试方法,并使用 unittest.main() 运行测试。测试文件的命名约定为 test_*.py。
pytest: 自动发现测试文件和测试函数,无需特定的命名约定。只需运行 pytest 命令即可执行测试。
测试参数化:
unittest: 使用 @unittest.skip、@unittest.skipIf 等装饰器来跳过测试或根据条件运行测试。
pytest: 支持更灵活的参数化测试,使用 @pytest.mark.parametrize 装饰器可以轻松地进行参数化测试。
插件系统:
unittest: 原生支持插件,但相对简单。
pytest: 拥有丰富的插件生态系统,可以通过插件实现各种功能,如参数化、覆盖率分析、多线程测试等。
测试夹具(Fixture):
unittest: 使用 setUp 和 tearDown 方法来设置和清理测试夹具。
pytest: 提供更灵活的夹具机制,可以使用 @pytest.fixture 装饰器创建夹具函数,还支持夹具的参数化。
测试用例发现的方式:
unittest: 通过 unittest.TestLoader 来加载和发现测试用例。
pytest: 自动发现测试文件和测试函数,可以识别以 test_ 开头的函数或以 Test 开头的类。
总体而言,pytest 更灵活、语法更简洁,有更强大的功能和插件生态系统,因此在很多情况下,开发者更喜欢使用 pytest 进行测试。但在一些项目中,unittest 仍然是一个合适的选择,特别是在项目已经使用 unittest 框架并且迁移成本较高的情况下。
27.python如何编写大模型:
运行百川大模型的环境:GPU空间足够,下载十个个G大小的百川bin文件,然后进行调用
import torch
from modelscope import snapshot_download, AutoModelForCausalLM, AutoTokenizer,GenerationConfig
model_dir = snapshot_download("baichuan-inc/Baichuan2-13B-Chat", revision='v1.0.3')
tokenizer = AutoTokenizer.from_pretrained(model_dir, device_map="auto",
trust_remote_code=True, torch_dtype=torch.float16)
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto",
rust_remote_code=True, torch_dtype=torch.float16)
model.generation_config = GenerationConfig.from_pretrained(model_dir)
messages = []
messages.append({"role": "user", "content": "讲解一下“温故而知新”"})
response = model.chat(tokenizer, messages)
print(response)
messages.append({'role': 'assistant', 'content': response})
messages.append({"role": "user", "content": "背诵一下将进酒"})
response = model.chat(tokenizer, messages)
print(response)
一些核心名词的概念分析:
微调(SFT:Supervised Fine Tuning)是一种机器学习技术,涉及对预训练模型进行小的调整,以提高其在特定任务中的性能。因为模型已经对世界有了很好的了解,并且可以利用这些知识更快地学习新任务,因此微调比从头开始训练模型更有效,通常也会产生更好的结果。从成本的角度看,微调的成本也会比预训练大模型的成本要低的多。虽然微调也需要成本,但我们基本可以承担这些成本。
RAG,即检索增强生成,英文Retrieval-Augmented Generation的缩写。
RAG可以通过将检索模型和生成模型结合在一起,从而提高了生成内容的相关性和质量。通俗一点讲就是大模型LLM如何很好的与外部知识源结合在一起, 使其生成的内容质量更高,缓解大模型LLM生成内容「幻觉」的问题。
如何调用gpt4做接口测试?
def req_openai(message, key):
# gpt-3.5-turbo
#openai.api_base="https://openkey.cloud/v1"
openai.api_base='"https://op.zakix.info/v1'
openai.api_key = key
retry_times = 0
messages = []
messages.append({"role": "user", "content": message })
try:
response = openai.ChatCompletion.create(
#model='gpt-3.5-turbo'
# model="gpt-4",
model='gpt-4-1106-preview',
messages=messages,
temperature=1
)
reply = response["choices"][0]['message']['content']
return reply
except Exception as r:
print(r)
return ''
28.爬虫常见的解析方法
Xpath解析hmtl文件
# -- coding: utf-8 --**
from lxml import html
# 当前 HTML 示例
current_html = '''
<html>
<head>
<title>当前 HTML 示例</title>
</head>
<body>
<div>
<p class="paragraph">这是一个段落</p>
<ul>
<li>列表项1</li>
<li>列表项2</li>
<li>列表项3</li>
</ul>
</div>
</body>
</html>
'''
# 使用 lxml 和 XPath 解析当前 HTML 内容
tree = html.fromstring(current_html)
# 例子 1: 提取标题文本
title = tree.xpath('//title/text()')[0]
print(f'标题文本: {title}')
# 例子 2: 遍历并获取列表项文本
list_items = tree.xpath('//ul/li/text()')
for item in list_items:
print(f'列表项: {item}')
# 例子 3: 提取段落的 class 属性值
class_attribute = tree.xpath('//p[@class="paragraph"]/@class')[0]
print(f'段落的 class 属性值: {class_attribute}')
# 例子 4: 使用相对路径提取信息
first_list_item = tree.xpath('//ul/li[1]/text()')[0]
print(f'第一个列表项: {first_list_item}')
# 例子 5: 使用逻辑运算符组合条件
specific_list_item = tree.xpath('//ul/li[contains(text(), "2")]/text()')[0]
print(f'包含 "2" 的列表项: {specific_list_item}')
正则表达式解析
# -- coding: utf-8 --**
import re
# 当前 HTML 示例
current_html = '''
<html>
<head>
<title>当前 HTML 示例</title>
</head>
<body>
<div>
<p class="paragraph">这是一个段落</p>
<ul>
<li>列表项1</li>
<li>列表项2</li>
<li>列表项3</li>
</ul>
</div>
</body>
</html>
'''
# 例子 1: 提取标题文本
title_match = re.search(r'<title>(.*?)</title>', current_html)
if title_match:
title = title_match.group(1)
print(f'标题文本: {title}')
# 例子 2: 遍历并获取列表项文本
list_items_match = re.findall(r'<li>(.*?)</li>', current_html)
for item in list_items_match:
print(f'列表项: {item}')
# 例子 3: 提取段落的 class 属性值
class_attribute_match = re.search(r'<p class="(.*?)">这是一个段落</p>', current_html)
if class_attribute_match:
class_attribute = class_attribute_match.group(1)
print(f'段落的 class 属性值: {class_attribute}')
# 例子 4: 使用正则表达式提取信息
first_list_item_match = re.search(r'<li>(.*?)</li>', current_html)
if first_list_item_match:
first_list_item = first_list_item_match.group(1)
print(f'第一个列表项: {first_list_item}')
# 例子 5: 使用正则表达式组合条件
specific_list_item_match = re.search(r'<li>列表项2</li>', current_html)
if specific_list_item_match:
specific_list_item = specific_list_item_match.group(0)
print(f'特定列表项: {specific_list_item}')
Bs4解析html
# -- coding: utf-8 --**
from bs4 import BeautifulSoup
# HTML 示例
html = '''
<html>
<head>
<title>BeautifulSoup Example</title>
</head>
<body>
<div>
<p class="paragraph">这是一个段落</p>
<ul>
<li>列表项1</li>
<li>列表项2</li>
<li>列表项3</li>
</ul>
</div>
</body>
</html>
'''
# 创建 BeautifulSoup 对象
soup = BeautifulSoup(html, 'html.parser')
# 例子 1: 获取标题文本
title_text = soup.title.text
print(f'标题文本: {title_text}')
# 例子 2: 遍历并获取列表项文本
list_items = soup.find_all('li')
for item in list_items:
print(f'列表项: {item.text}')
# 例子 3: 添加新元素
new_li = soup.new_tag('li')
new_li.string = '新增列表项'
soup.ul.append(new_li)
print(soup)
# 例子 4: 修改元素属性
paragraph = soup.find('p', class_='paragraph')
paragraph['class'] = 'new-paragraph'
print(soup)
# 例子 5: 删除元素
first_li = soup.find('li')
first_li.extract()
print(soup)
Pyquery解析html
from pyquery import PyQuery as pq
# 创建 PyQuery 对象
html = '''
<div>
<p class="paragraph">这是一个段落</p>
<ul>
<li>列表项1</li>
<li>列表项2</li>
<li>列表项3</li>
</ul>
</div>
'''
doc = pq(html)
# 例子 1: 获取段落文本
paragraph_text = doc('.paragraph').text()
print(f'段落文本: {paragraph_text}')
# 例子 2: 遍历并获取列表项文本
list_items = doc('ul li')
for item in list_items.items():
print(f'列表项: {item.text()}')
# 例子 3: 添加新元素
doc('ul').append('<li>新增列表项</li>')
print(doc)
# 例子 4: 修改元素属性
doc('.paragraph').attr('class', 'new-paragraph')
print(doc)
# 例子 5: 删除元素
doc('ul li:first').remove()
print(doc)

















 2093
2093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









