







1. Pandas
Pandas是python的一个第三方包,是一个结构化数据工具集,能够更加灵活、快速的对数据进行清洗和处理,适用于单击大数据量的数据分析和数据开发
使用pandas包之前,首先安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pandas
程序中再导入该包
import pandas as pd
2. 构建Series
Pandas有两个重要的数据结构:Series 和 DataFrame
DataFrame是一个二维表格对象,包括行和固定的列且每列数据类型一致。而Series就是DataFrame的列对象,包括数据列和索引列,若数据没有指定索引列,会自动创建一个0到N-1长度为N的整数型索引列
# 1.通过列表创建
lss = pd.Series([1, 2, 3])
lss = pd.Series([1, 2, 3], index=['A', 'B', 'C'])
# 2.使用元组创建
tss = pd.Series((1, 2, 3, 4, 5, 6))
# 3.使用字典创建
mss = pd.Series({'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6})
print(mss)
3.Serial转DataFrame
# 1.Series对象转DataFrame
df = mss.to_frame()
df = mss.reset_index()
4. 本地集合方式构建DataFrame
# 2. 字典、列表组合创建df,使用默认自增索引(形成了一张纵表,数据按列存放)
mldata = {
'温度': [25, 31, 28, 37, 40],
'湿度': [80, 71, 75, 69, 70],
'日期': ['2023-06-30', '2023-07-01', '2023-07-02', '2023-07-03', '2023-07-07']
}
mldf = pd.DataFrame(data=mldata)
# 3. 元组、列表组合创建df,使用默认自增索引(形成了一张横表,数据横着放)
tldata = [
('2023-06-30', '2023-07-01', '2023-07-02', '2023-07-03', '2023-07-07'),
(80, 71, 75, 69, 70), (25, 31, 28, 37, 40)
]
tldf = pd.DataFrame(data=tldata)
# 4.列表、列表组合构建df
lldata = [
['1960-05-07', '刘海柱', '职业法师'],
['1978-09-01', '赵金龙', '大力哥'],
['1984-12-27', '周立齐', '窃格瓦拉'],
['1969-01-24', '于谦', '相声皇后']
]
lldf = pd.DataFrame(data=lldata, columns=['birthday', 'name', 'AKA'])
print(lldf)
5. DataFrame接收本地文件
lfdf = pd.read_csv('../../data/E_Commerce_Data.csv', sep=',', encoding='gbk')
sep参数, 指定字段之间的分隔符号。默认的分隔符号为逗号, 当文件中的字段之间的分隔符号不是逗号的时候, 我们可以采用此参数来调整
encoding参数 指定编码格式。常见的编码格式有:ASCII、GB2312、UTF8、GBK 等
多文件格式数据读写
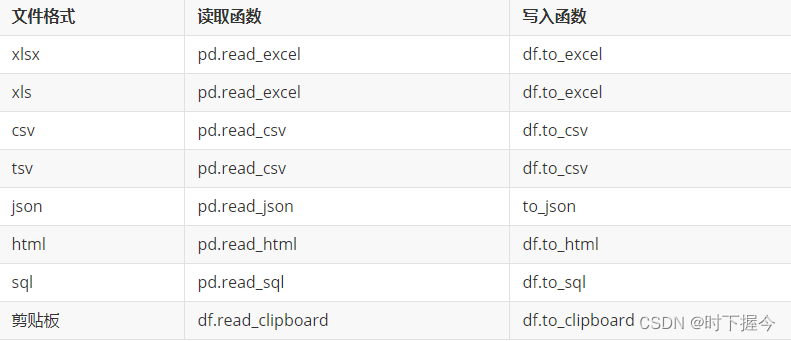
6. 读数据库返回DataFrame
如果想利用pandas和MySQL数据库进行交互,需要先安装与数据库交互所需要的python包
pip install pymysql == 1.0.2
pip install sqlalchemy == 1.4.31
然后程序中导入该包:
from sqlalchemy import create_engine
python包操作数据库的方式
lfdf = pd.read_csv('../../data/E_Commerce_Data.csv', sep=',', encoding='gbk')
# 创建数据库引擎,传入uri规则的字符
# mysql 表示数据库类型
# pymysql 表示python操作数据库的包
# root:root 表示数据库的账号和密码,用冒号连接
# node1:3306/test 表示数据库的ip和端口,以及名叫test的数据库
# charset=utf8 规定编码格式
engine = create_engine('mysql+pymysql://root:123456@node1:3306/test?charset=utf8')
# df.to_sql()方法将df数据快速写入数据库
# 第一个参数为数据表的名称
# 第二个参数engine为数据库交互引擎
# index=False 表示不添加自增主键
# if_exists='append' 表示如果表存在就添加,表不存在就创建表并写入
lfdf.to_sql('invoice_info', engine, index=False, if_exists='append')
# 读取整张表, 返回dataFrame
# 参数1表名,参数2数据库连接引擎对象
pd.read_sql('invoice_info', engine)
# 使用SQL语句获取数据,返回dataframe
# 参数1:sql语句,参数2:数据库连接引擎对象
df= pd.read_sql('select * from invoice_info where country="Kingdom"', engine)
print(lfdf)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









