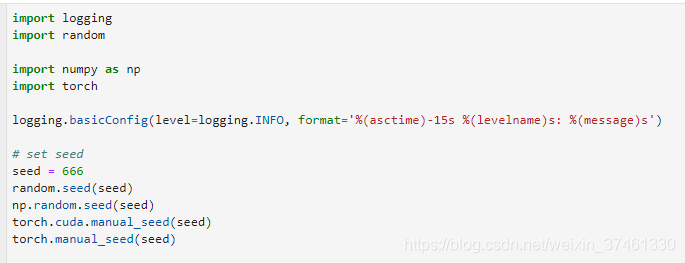
 文本特征抽取技术
文本特征抽取技术







 本文介绍了三种文本特征抽取方法:Word2Vec,通过CNN进行n-gram特征抽取并使用MaxPooling保留最大特征值;TextRNN,利用双向双层LSTM处理文本序列数据,将最后隐藏层拼接作为文本表示。
本文介绍了三种文本特征抽取方法:Word2Vec,通过CNN进行n-gram特征抽取并使用MaxPooling保留最大特征值;TextRNN,利用双向双层LSTM处理文本序列数据,将最后隐藏层拼接作为文本表示。
1.Word2Vec:
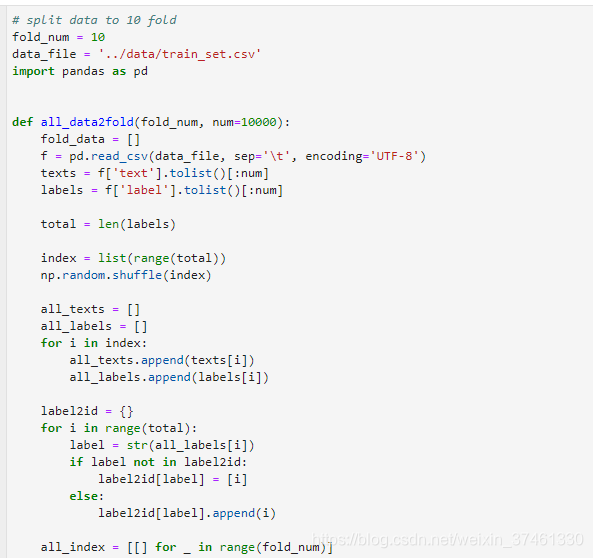
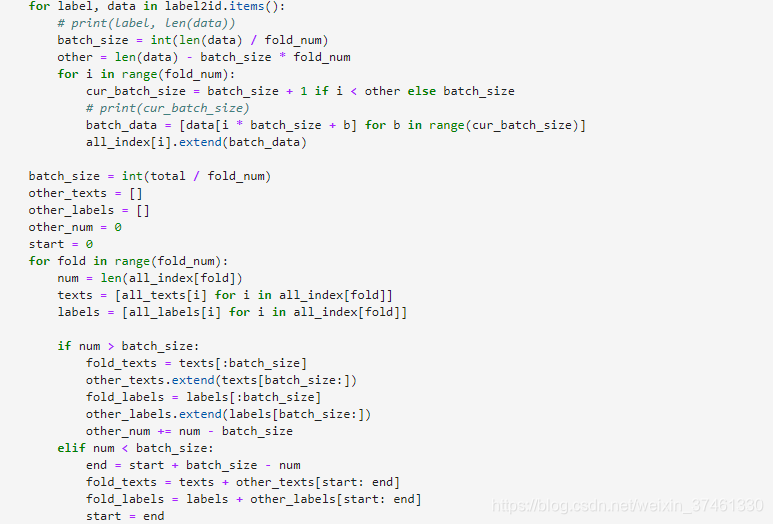
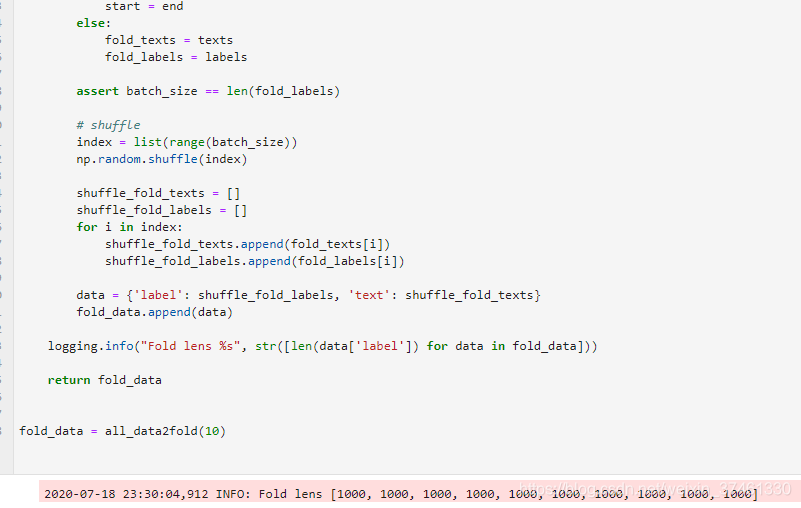
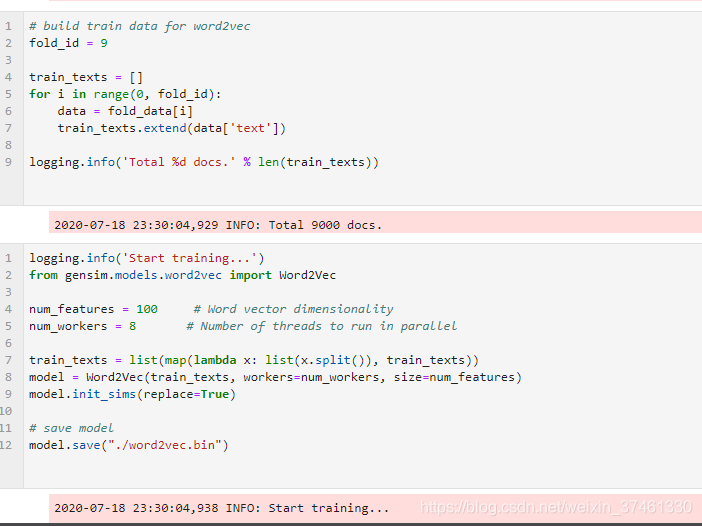
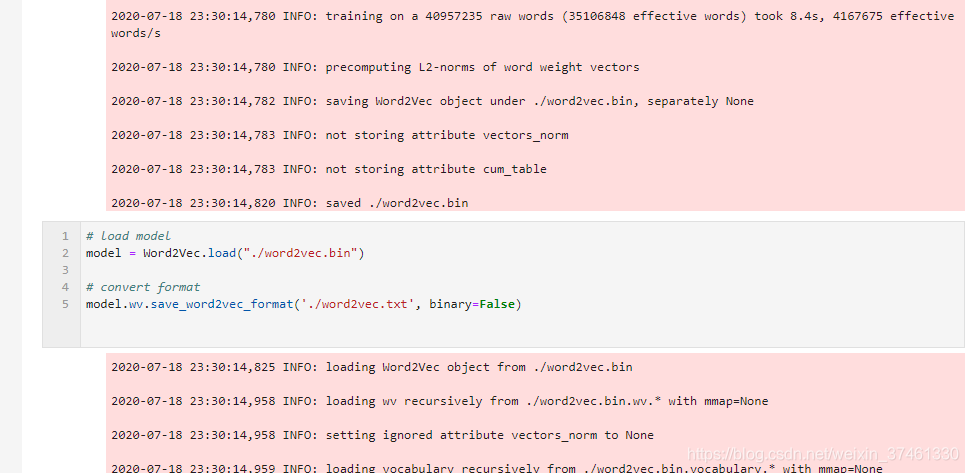
2.TextCNN:
利用CNN(卷积神经网络)进行文本特征抽取,不同大小的卷积核分别抽取n-gram特征,卷积计算出的特征图经过MaxPooling保留最大的特征值,然后将拼接成一个向量作为文本的表示。
这里我们基于TextCNN原始论文的设定,分别采用了100个大小为2,3,4的卷积核,最后得到的文本向量大小为100*3=300维。


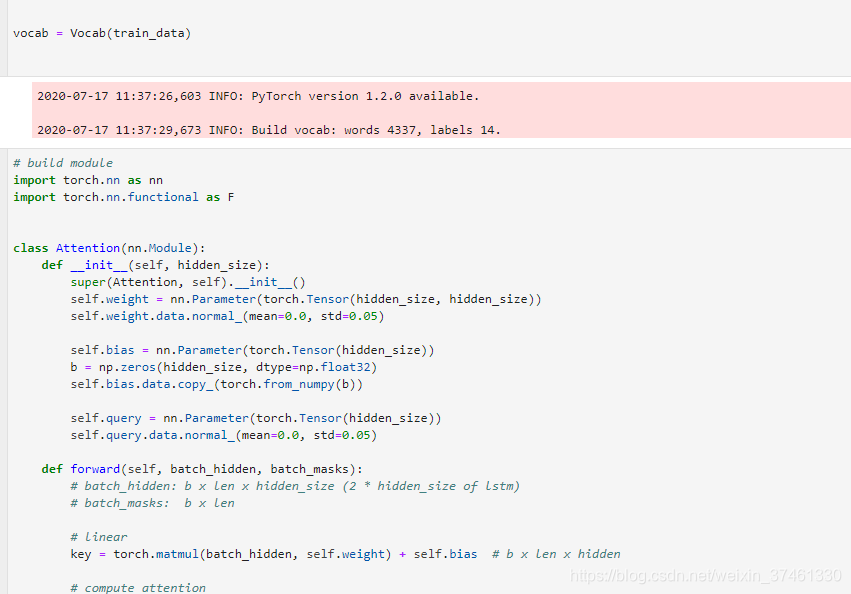
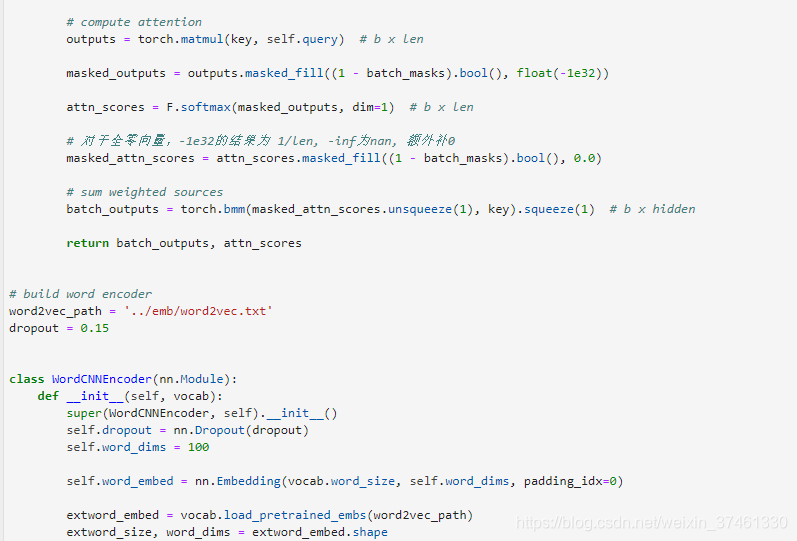
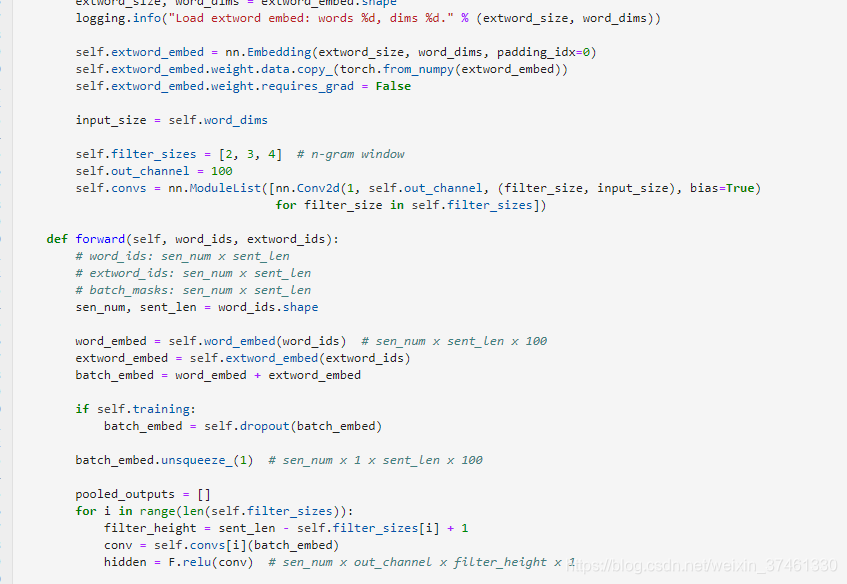
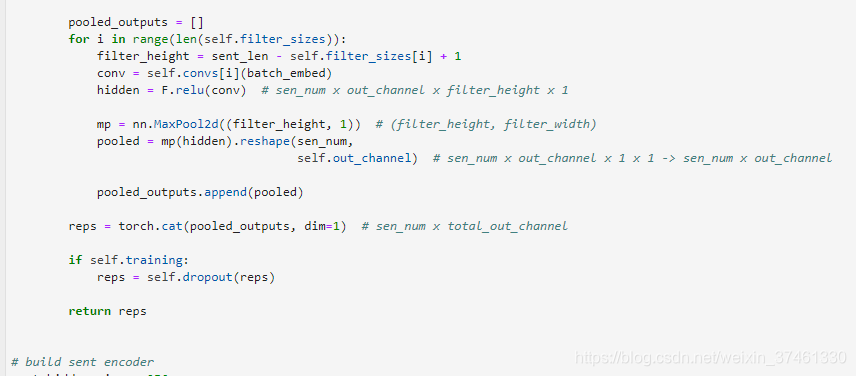
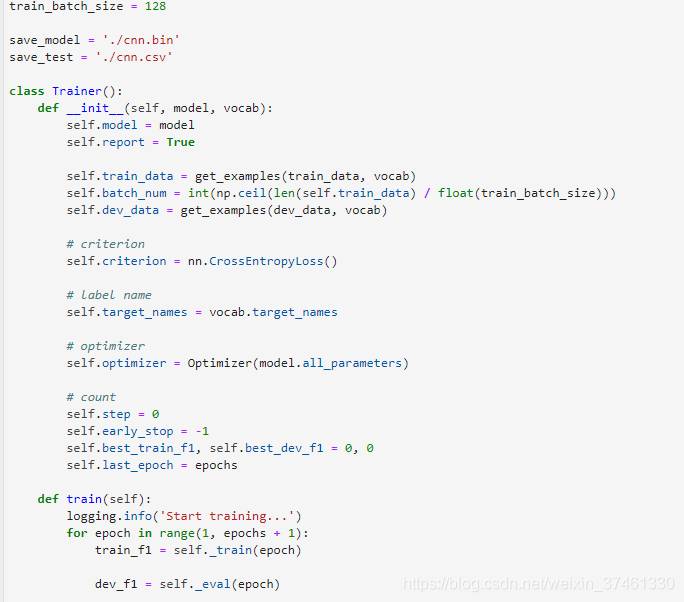

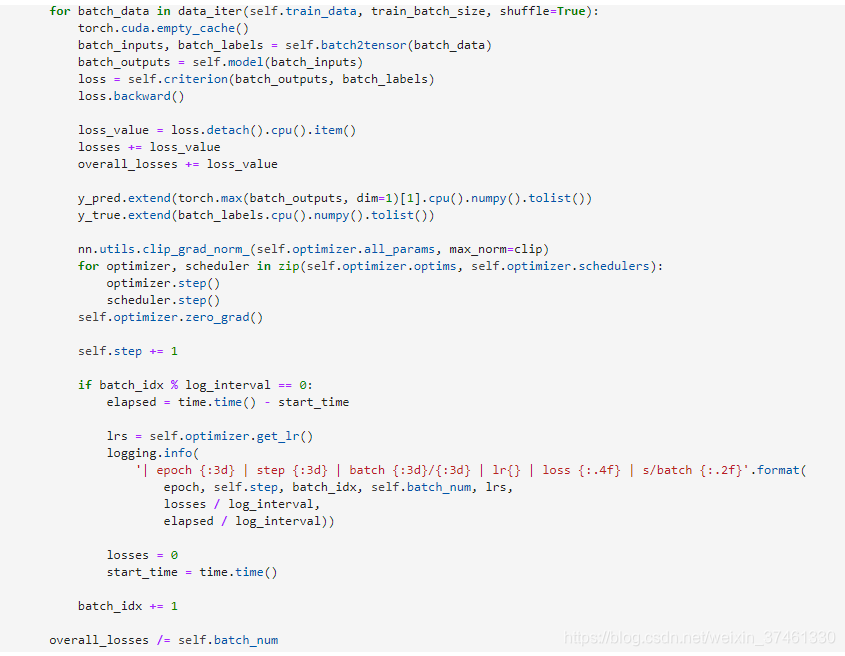
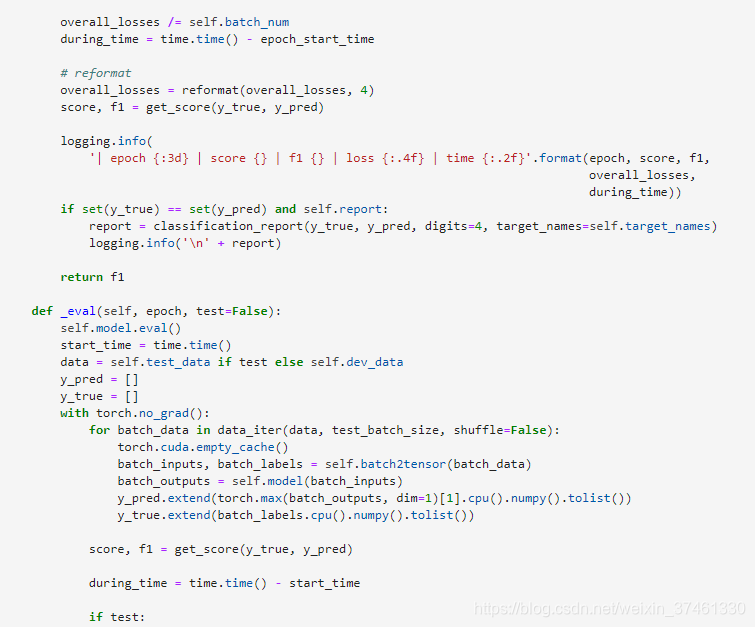
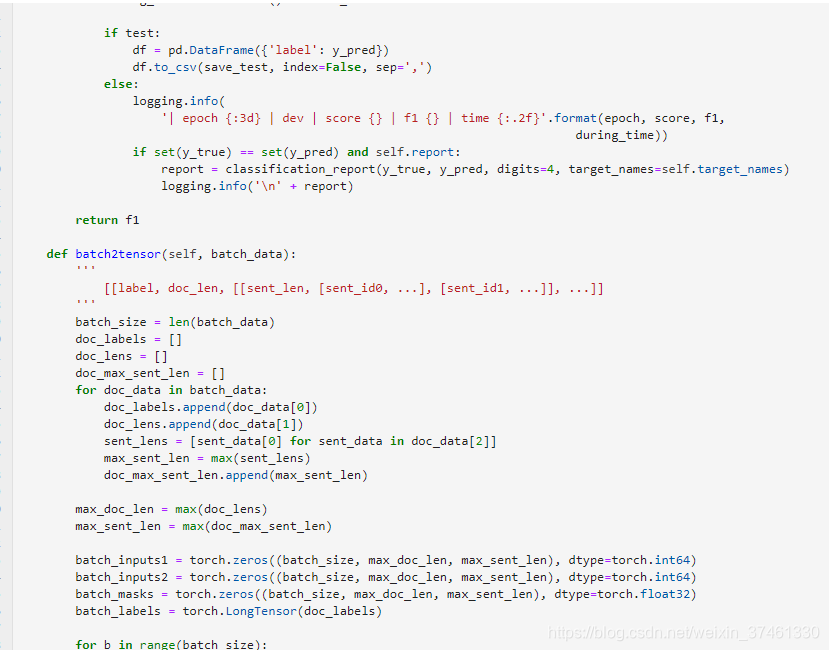
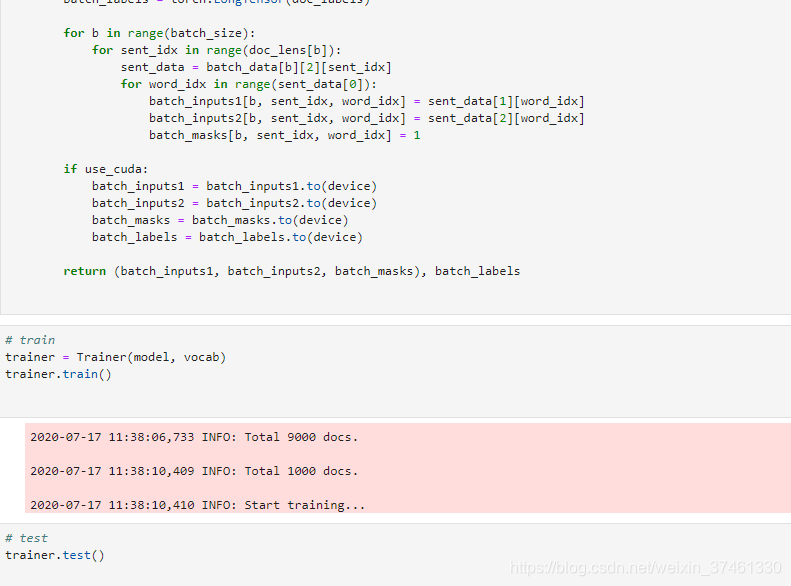
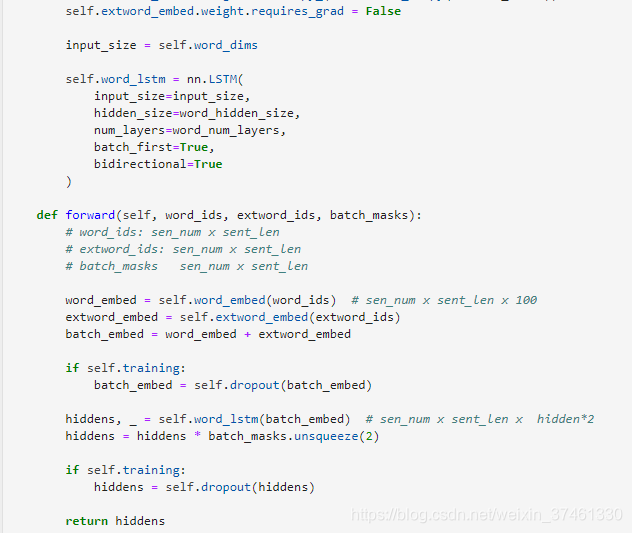
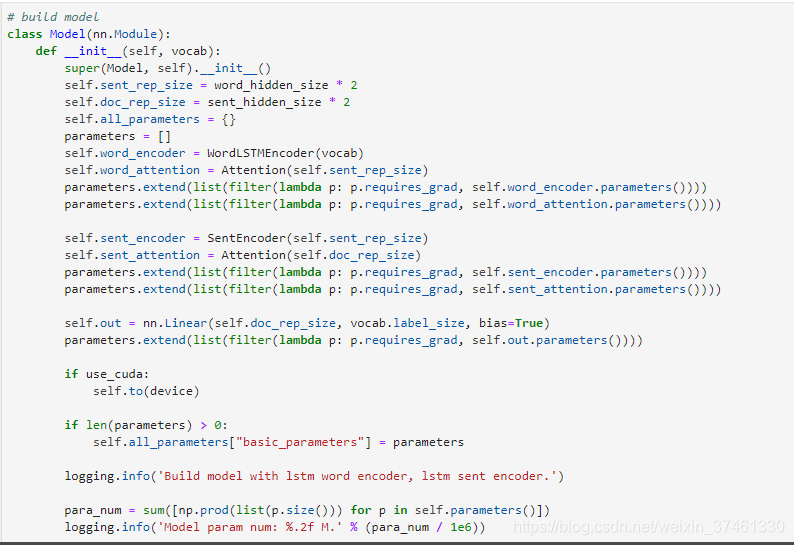
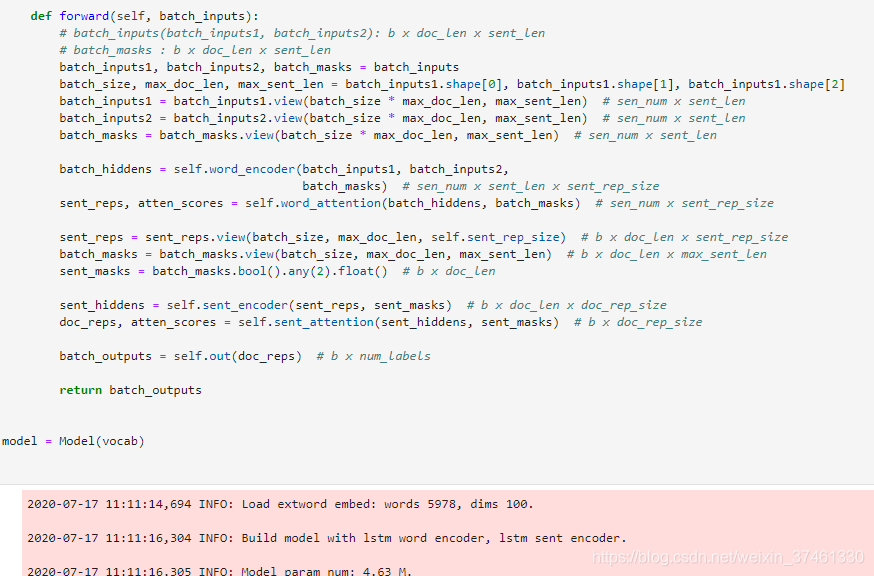
3.TextRNN:
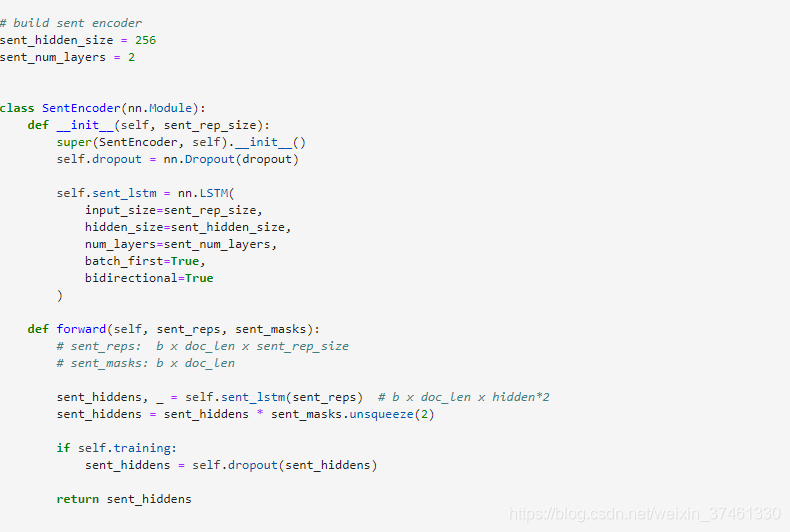
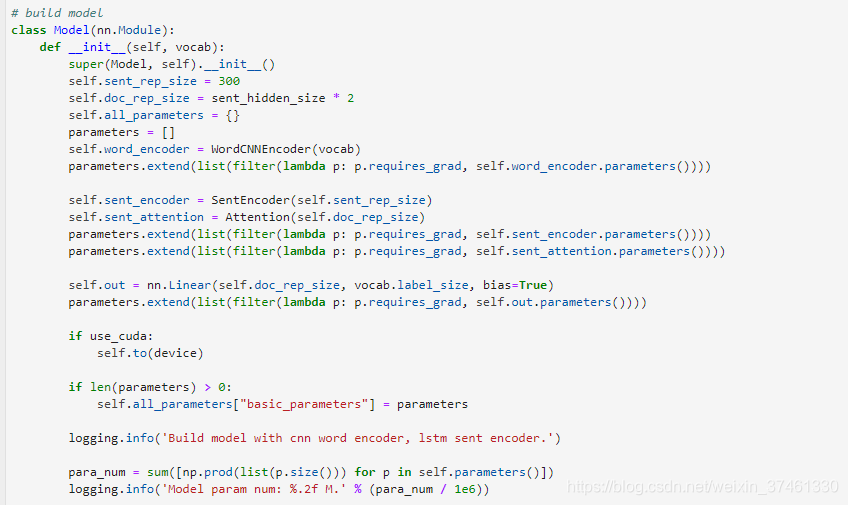
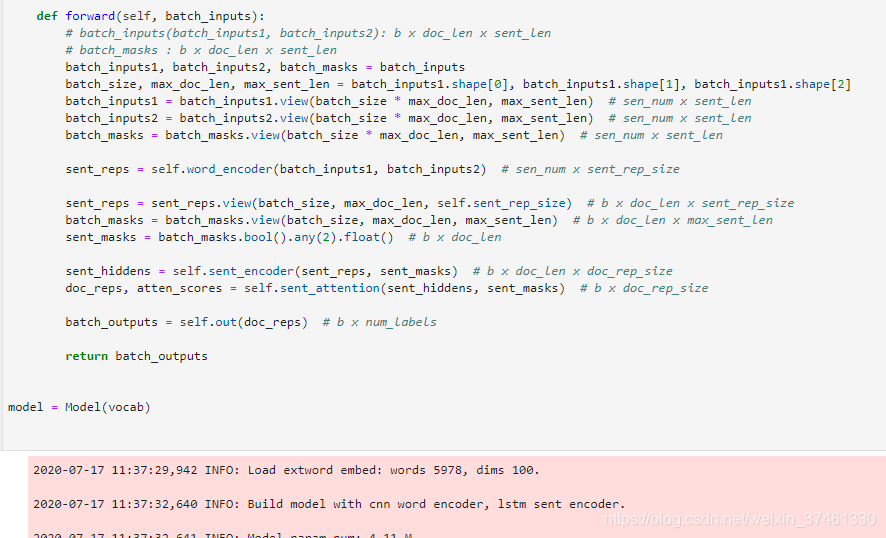
TextRNN
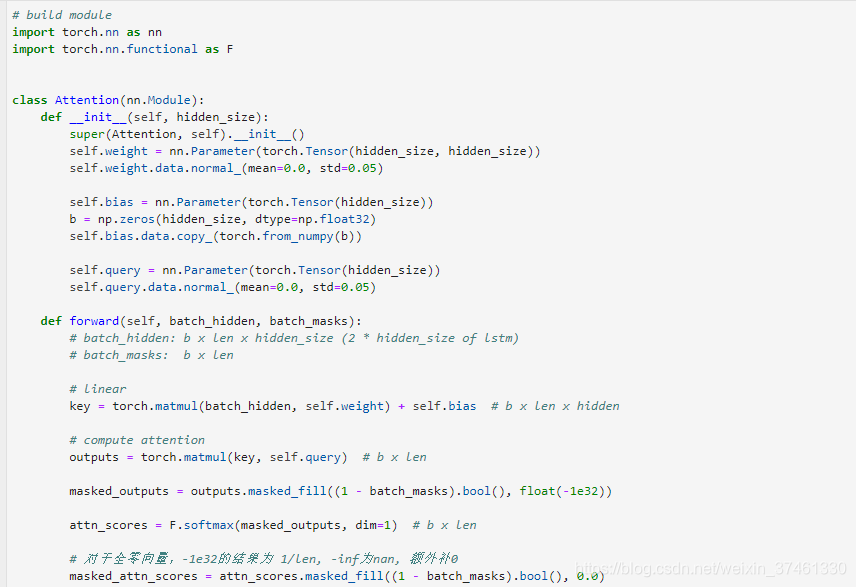
TextRNN利用RNN(循环神经网络)进行文本特征抽取,由于文本本身是一种序列,而LSTM天然适合建模序列数据。TextRNN将句子中每个词的词向量依次输入到双向双层LSTM,分别将两个方向最后一个有效位置的隐藏层拼接成一个向量作为文本的表示。
























 2558
2558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









