



 作者阅读周志华老师的机器学习书籍(西瓜书)后分享理解。介绍了真值概念,它是理想值一般无法得到。还阐述噪声是真实标记与实际标记偏差,衡量数据集质量,无法用算法改善;偏差是期望预测与真实标记的误差。
作者阅读周志华老师的机器学习书籍(西瓜书)后分享理解。介绍了真值概念,它是理想值一般无法得到。还阐述噪声是真实标记与实际标记偏差,衡量数据集质量,无法用算法改善;偏差是期望预测与真实标记的误差。
最近在看周志华老师的机器学习的书籍(俗称西瓜书)。
因为数学功底差,在理解起来困难重重,但是冥思苦想后还有自己的看法,记录一下并和大家分享讨论。
几点理解:
0.吹年之前,先说个 人们容易忽略的概念 真值!
真值是啥玩意那,就是一个我们不知道的(有时候是我们的目标哦),但是实际存在的东西,比如测电压时的测量值和真值。
补充一下真值的概念:真值是指在一定的时间及空间(位置或状态)条件下,被测量所体现的真实数值。真值是一个变量本身所具有的真实值,它是一个理想的概念,一般是无法得到的。
为啥要提真值那?因为真值不是统计学的概念,后面的噪声和偏差都涉及到了真值。
1.噪声是什么玩意,怎么理解?
噪声的公式为:
噪声为真实标记与数据集中的实际标记间的偏差:
![]()
说白就是:衡量我拿到的数据集的数据的质量如何,有句话说的好,巧妇难为无米之炊,你原始数据差,我算法再好也搞不定啊,因此噪声是无法通过算法改善的,噪声就是物质的存在(但是人们可以对噪声进行处理,比如滤波)。但是人们总是想(期望)拿到数据的值和真值之间的差的平均值为零,也就是噪声期望为零。举个通俗易懂的例子:我们通过设备测信号,我们总是期望测得的数据就是信号的真值,但是实际上,测得数据都是在真值上下移动,衡量数据与真值的差,我们引入了噪声的概念。但是凡是涉及到真值的,统计学的角度都无法知道真值。
2.另外一个涉及到真值的统计量就是:
偏差
期望预测与真实标记的误差称为偏差(bias), 为了方便起见, 我们直接取偏差的平方:
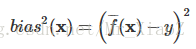
偏差相比起噪声来很容易理解,就是我算法获得值和目标值(真值)的偏差呗!在此不做过多赘述。
注:以上分析仅代表我的个人观点,如果不赞同,欢迎讨论!

















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









