






前言:
ComfyUI的学习是一场持久战,当你掌握ComfyUI的安装和运行之后,会出现琳琅满目的节点,当各种各样的工作流映入眼帘,往往难以接受纷繁复杂的节点种类,本篇文章将以通俗易懂的语言,对ComfyUI的各种核心节点进行系统的梳理和参数的详解,祝愿大家在学习的过程中掌握自我思考的能力,并且切实的掌握和理解各个节点的用法与功能。
目录:
一、Load Checkpoint节点
二、Load Checkpoint with config节点
三、CLIP Set Last Layer节点
四、CLIP Text Encode (Prompt)节点
五、KSampler节点
六、Empty Latent image节点
七、VAE Decode节点
八、Preview image节点
文生图示例工作流
一、Load Checkpoint节点
节点功能:该节点用来加载checkpoint大模型,常用的大模型有sd1.0,sd1.5,sd2.0,sdxl等等。
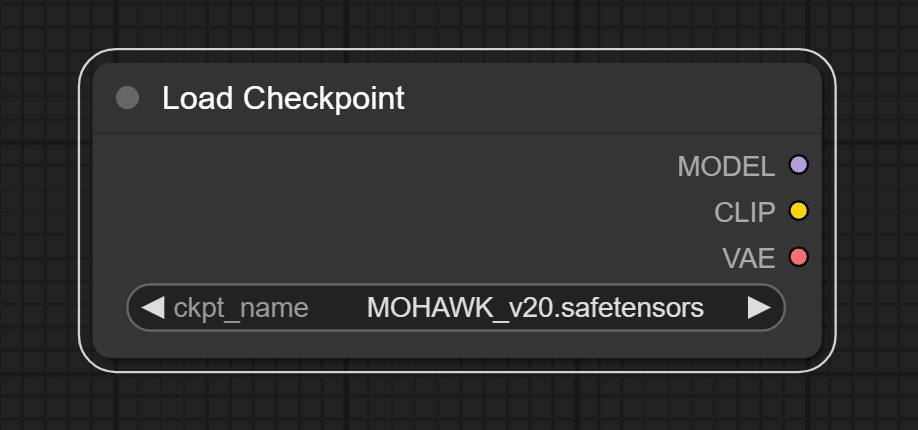
输入:
输出:
注意:StableDIffusion大模型(checkpoint)内置有CLIP和VAE模型。
二、Load Checkpoint with config节点
节点功能:该节点用来加载checkpoint大模型,常用的大模型有sd1.0,sd1.5,sd2.0,sdxl等等。
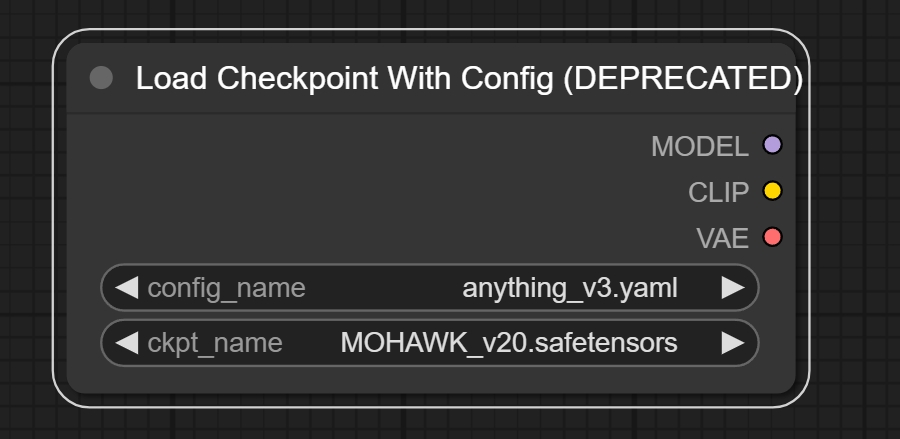
输入:
输出:
注意:常规的Load Checkpoint节点,可以自行搜索并加载相应的配置文件。
三、CLIP Set Last Layer节点
节点功能:该节点用来设置选择CLIP模型在第几层的输出数据。
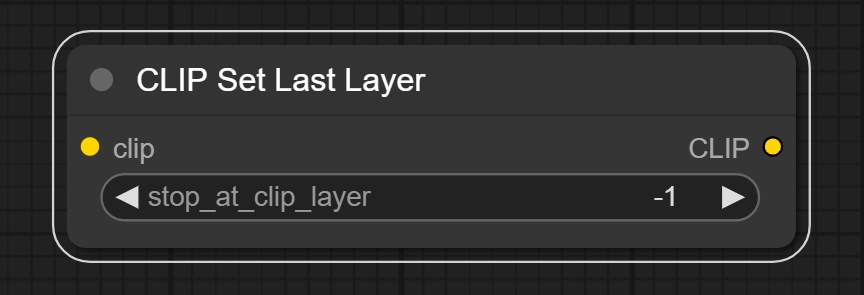
输入:
参数:
注意:CLIP模型对prompt进行编码的过程中,可以理解为对原始文本进行层层编码,该参数就是选择我们需要的一层编码信息,去引导模型扩散。
输出:
四、CLIP Text Encode (Prompt)节点
节点功能:该节点用来输入正反向提示词,也就是“文生图”,“文生视频”中“文”的输入位置。
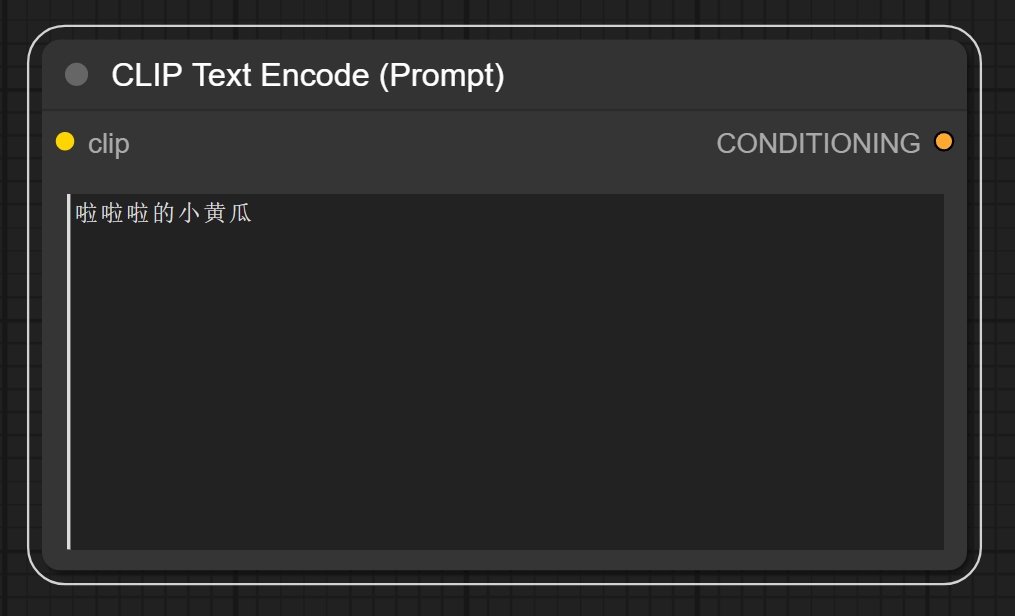
输入:
参数:
输出:
注意:当前prompt仅支持英文的输入。
五、KSampler节点
节点功能:该节点用来对潜空间噪声图进行逐步去噪的操作。 **注意去噪的过程是在潜空间进行处理**
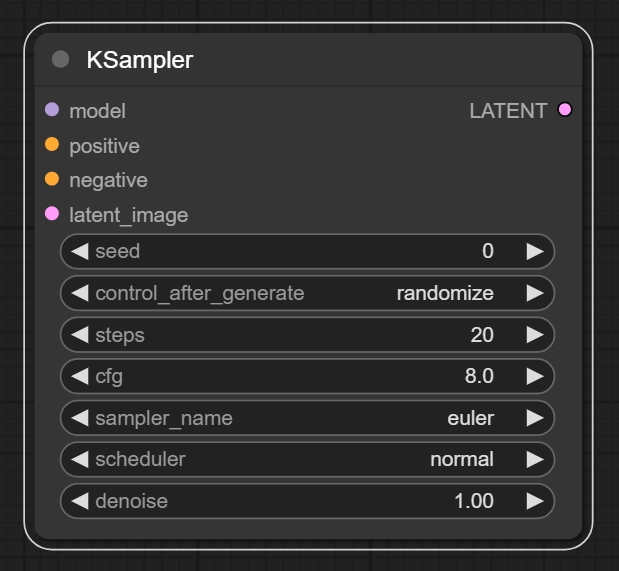
输入:
参数:
输出:
六、Empty Latent image节点
节点功能:该节点用来生成纯噪声的潜空间图像,并且设置图像的比例。
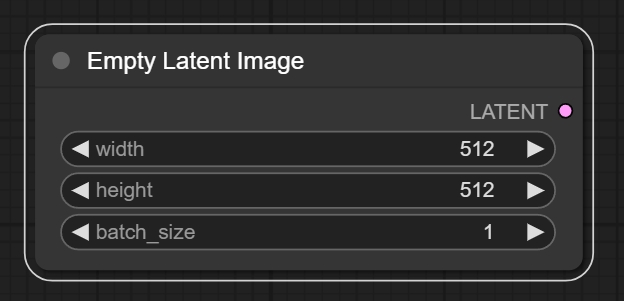
参数:
注意:SD1.0,SD1.5等模型最常使用512*512的尺寸。 SDXL,SD turbo等最常使用1024*1024的尺寸。
输出:
七、VAE Decode节点
节点功能:该节点用来将潜空间图像解码到像素级的图像。
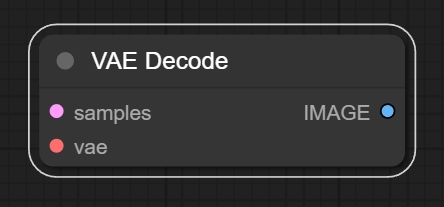
输入:
输出:
八、Preview image节点
节点功能:该节点用来预览image图像。
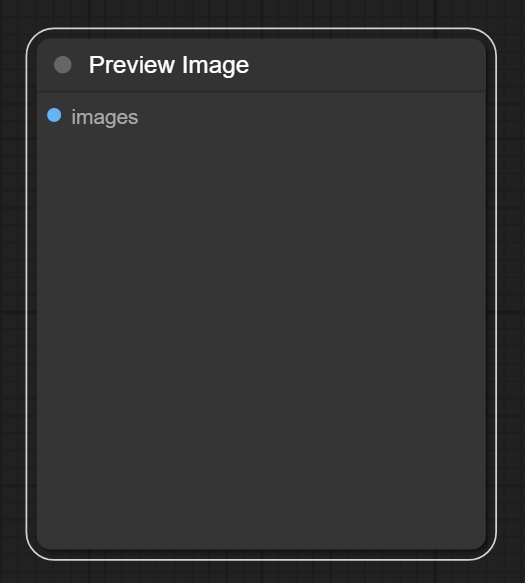
输入:
文生图示例工作流:
学习完以上节点,您就可以搭建第一个“文生图”工作流了
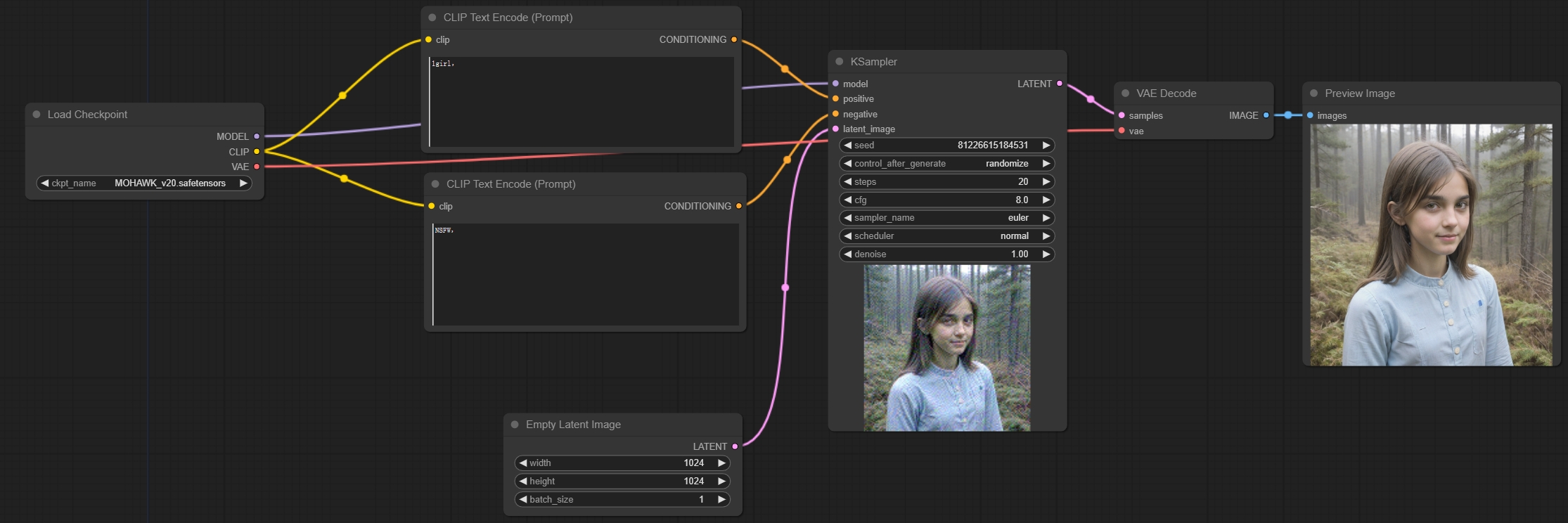
这里使用了SDXL的大模型,所以latent图像设置1024*1024,正向提示词输入1girl,反向提示词输入NSFW避免出现不能播的内容,采样器使用默认设置,最终出图如下:


















 3207
3207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









