







 超级会员免费看
超级会员免费看
 本文探讨了Redis数据结构如何实现快速访问,重点分析了键值对的哈希表组织方式和潜在的慢操作。Redis使用全局哈希表进行键值对的快速查找,但哈希冲突和rehash可能导致操作变慢。文中还介绍了集合类型如List、Hash、Set和Sorted Set的底层数据结构,包括双向链表、压缩列表、整数数组、哈希表和跳表,以及它们的不同操作复杂度。理解这些数据结构有助于最大化Redis性能并避免潜在的慢操作。
本文探讨了Redis数据结构如何实现快速访问,重点分析了键值对的哈希表组织方式和潜在的慢操作。Redis使用全局哈希表进行键值对的快速查找,但哈希冲突和rehash可能导致操作变慢。文中还介绍了集合类型如List、Hash、Set和Sorted Set的底层数据结构,包括双向链表、压缩列表、整数数组、哈希表和跳表,以及它们的不同操作复杂度。理解这些数据结构有助于最大化Redis性能并避免潜在的慢操作。
一提到Redis,我们的脑子里马上就会出现一个词:“快。”但是你有没有想过,Redis的快,到底是快在哪里呢?实际上,这里有一个重要的表现:它接收到一个键值对操作后,能以微秒级别的速度找到数据,并快速完成操作。
数据库这么多,为啥Redis能有这么突出的表现呢?一方面,这是因为它是内存数据库,所有操作都在内存上完成,内存的访问速度本身就很快。另一方面,这要归功于它的数据结构。这是因为,键值对是按一定的数据结构来组织的,操作键值对最终就是对数据结构进行增删改查操作,所以高效的数据结构是Redis快速处理数据的基础。这节课,我就来和你聊聊数据结构。
说到这儿,你肯定会说:“这个我知道,不就是String(字符串)、List(列表)、Hash(哈希)、Set(集合)和Sorted Set(有序集合)吗?”其实,这些只是Redis键值对中值的数据类型,也就是数据的保存形式。而这里,我们说的数据结构,是要去看看它们的底层实现。
简单来说,底层数据结构一共有6种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。它们和数据类型的对应关系如下图所示:
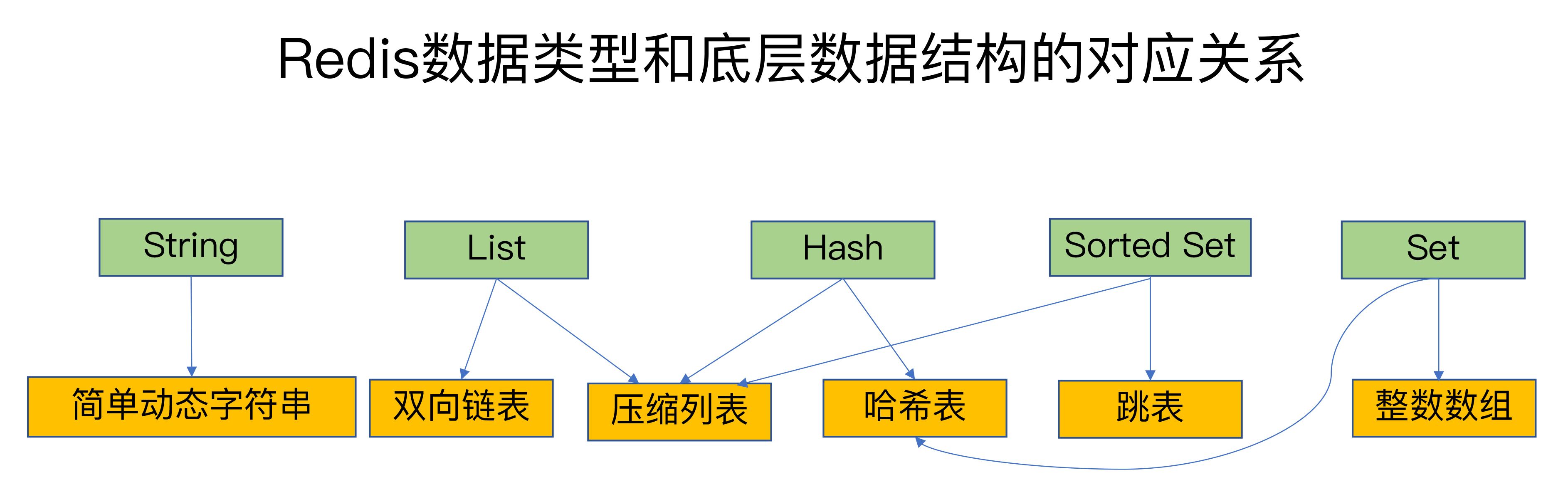
可以看到,String类型的底层实现只有一种数据结构,也就是简单动态字符串。而List、Hash、Set和Sorted Set这四种数据类型,都有两种底层实现结构。通常情况下,我们会把这四种类型称为集合类型,它们的特点是一个键对应了一个集合的数据</

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1244
1244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











