




论文标题:From Data-Centric to Sample-Centric: Enhancing LLM Reasoning via Progressive Optimization
为了实现这一目标,他们提出了一个名为 LPPO(Learning-Progress and Prefix-guided Optimization) 的渐进式优化框架。该框架模仿了人类学习的两个核心特征:
- 前缀引导采样(Prefix-Guided Sampling, PG-Sampling)
寻求提示:当我们遇到一个百思不得其解的难题时,我们通常不会直接放弃或去看完整答案,而是会寻求一个“提示”(hint),帮助我们打开思路,然后自己完成剩下的部分。- 学习进程加权(Learning-Progress Weighting, LP-Weighting)
聚焦进步:在学习过程中,我们会自然地将更多精力投入到那些我们正在取得进步、但尚未完全掌握的知识点上,而不是反复练习已经熟练掌握或完全无法理解的内容。
LPPO框架
LPPO框架的创新之处在于,它认为一个静态的、统一的训练策略对于所有样本而言并非最优。学习是一个动态的过程,模型对不同样本的“掌握程度”在不断变化。因此,训练策略也应该是动态的、个体化的。
这种“样本为中心”的理念借鉴了人类的学习过程:
- 对于“卡住”的难题:当模型对于某个问题,无论如何探索都无法得到正确答案时(即通过率始终为0),一直让它“盲目”尝试是低效的。这就像一个学生面对一道奥数题,毫无头绪,反复尝试只会消耗时间和信心。此时,一个来自老师或答案解析的“前缀提示”,比如解题的第一步或关键思路,往往能起到四两拨千斤的作用。
LPPO中的前缀引导采样(PG-Sampling) 正是扮演了这个“老师”的角色。
- 对于不同学习阶段的题目:一个训练批次中的样本,对模型当前的意义是不同的。
LPPO中的学习进程加权(LP-Weighting) 机制,就是为了动态识别出这些“正在取得进步的题目”,并加大它们在模型参数更新中的影响力,从而加速学习进程。
- 已掌握的题目:模型已经能稳定解决(例如通过率接近100%),再继续投入大量计算资源意义不大。
- 无法理解的题目:远超模型当前能力,无论如何训练,通过率都没有提升,持续投入可能是徒劳的。
- 正在取得进步的题目:模型正在逐渐“领悟”,通过率在稳步提升(例如从10%提升到30%)。这部分样本处于模型学习的“最近发展区”,是最高效的学习材料。
通过结合这两种策略,LPPO旨在让模型的训练资源始终聚焦于最有效率的学习点上,实现更快、更好的收敛。
方法论深度解析
LPPO框架由PG-Sampling和LP-Weighting两个核心组件构成,它们无缝地集成在标准的RLVR训练流程中。
1. 前缀引导采样 (Prefix-Guided Sampling, PG-Sampling)
PG-Sampling是一种在线数据增强技术,专门用于处理模型难以解决的“挑战性问题”。
机制:
- 识别挑战性问题:在每个训练周期(epoch)开始时,首先对一批样本进行一轮评估(rollout),计算每个样本的通过率(pass rate)。如果一个样本的通过率低于某个阈值 (在论文的实验中,该阈值被设为0,即只针对完全无法解决的问题),那么它就被标记为“挑战性问题”。
- 生成前缀提示:对于一个挑战性问题 ,需要一个预先准备好的专家解题方案 。PG-Sampling会从这个专家方案中截取一段前缀 作为“提示”。这个前缀的长度 不是固定的,而是通过一个随机过程确定:
其中, M是专家方案的总长度, λ是一个从均匀分布 U(βmin, βmax) 中采样的随机比例。例如,设置 βmin=0.3, βmax =0.8,意味着提示的长度将在专家方案全长的30%到80%之间随机变化。这种随机性可以防止模型过拟合于特定长度的提示。- 引导模型探索:模型 πθ 将问题 q 和生成的前缀提示 Spre,q 拼接起来作为新的输入,然后继续生成剩余的解题部分Srem,q :
- 计算奖励:将前缀Spre,q 和模型生成的后缀 Srem,q 组合成一个完整的解题方案,然后通过验证器(verifier)判断其最终答案是否正确,并据此计算奖励。
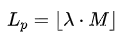
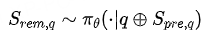
与监督学习(SFT)的对比:
PG-Sampling与完全的监督学习(SFT)或行为克隆(Behavior Cloning)有本质区别。SFT会强制模型学习整个专家方案,这可能会压制模型的探索天性,使其思维固化。而PG-Sampling只提供一个“开头”,鼓励模型在正确的方向上进行自我探索来完成剩余的步骤。这既给予了必要的引导,又保留了强化学习探索未知解法的优势,在监督与探索之间取得了平衡。
2. 学习进程加权 (Learning-Progress Weighting, LP-Weighting)
LP-Weighting是一种动态调整样本权重的策略,其核心是根据模型在每个样本上的“学习进步速度”来决定该样本在梯度更新中的贡献度。
机制:
- 追踪学习状态:对于每个样本 ,需要追踪其在不同训练周期 的通过率。然而,由于每个周期的评估(rollout)次数有限,原始的通过率 pass_rate_i(t) 可能存在较大噪声。为了获得一个更稳定的学习状态评估,LP-Weighting使用指数移动平均(Exponential Moving Average, EMA) 来平滑通过率序列:
其中 α 是平滑因子,Pi(t) 代表了在第 t 个周期时,模型对样本 i 的一个更稳定、更长期的掌握程度评估。- 量化学习进程:有了平滑的通过率,就可以定义“学习进程” 为相邻两个周期间平滑通过率的一阶差分:
这个值的直观含义是:
大于0:模型在样本 上正在取得进步。
小于0:模型在样本 上的表现出现了退步。
约等于0:学习陷入停滞(可能已经完全掌握,或完全无法学习)。- 计算动态权重:根据学习进程 Δi(t),可以计算出每个样本的动态权重 wi(t):
这个公式包含三个部分:
σ是 Sigmoid 激活函数,它将可能取值范围很广的 Δi(t) 映射到一个平滑的区间内,通常是 (0, 1)。
k 是一个敏感度因子,控制权重对学习进程变化的敏感程度。k 越大,权重曲线越陡峭,对微小的进步或退步反应越剧烈。
b 是一个偏置项或基础权重。它的作用是为所有样本提供一个最小的权重下限,即使是那些学习进程为负的样本也能获得一定的训练信号,这有助于防止“灾难性遗忘”。- 应用于优势估计:在强化学习的策略更新阶段,这个动态权重 wi(t) 被用来缩放优势函数估计值 Ai。
加权后的优势 Ai’ 计算如下:
这意味着,那些模型正在取得显著进步的样本,其对应的优势信号将被放大,从而在梯度更新中占据主导地位;
而那些学习停滞或退步的样本,其影响力则被相应减弱。
最终,这个加权的优势 Ai’会被代入到GRPO等策略优化的目标函数中,指导模型参数的更新。
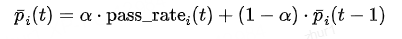
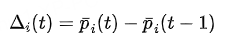
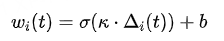
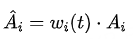
通过这种方式,LP-Weighting自动地将模型的“注意力”引导到最有学习价值的样本上,实现了计算资源的智能分配。
实验设置
基础模型: Qwen2.5-Math-7B
训练数据:817个来自LIMO研究的较难数学题(这些题目附有专家解法,可用于PG-Sampling)和一部分来自MATH数据集的中等难度问题。这旨在模拟高质量数据稀缺的真实场景。
评估基准:在六个广泛认可的数学推理基准上进行评估,包括AIME24, AIME25, AMC23, MATH-500, Minerva, 和 OlympiadBench。
评估指标:主要使用 pass@1,即模型生成一次答案的正确率。
主要结果
7B模型在六个数学推理基准上的零样本pass@1性能
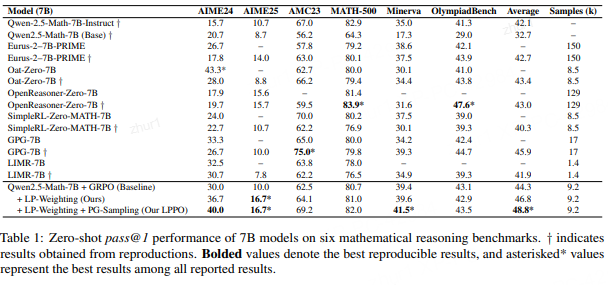
从上表中可以清晰地看到LPPO的强大效果:
显著优于基线:直接在Qwen2.5-Math-7B上应用GRPO作为基线,其平均分数为44.3%。
而集成了LP-Weighting和PG-Sampling的LPPO框架,将平均分提升至 48.8% ,获得了 4.5% 的绝对提升。这是一个非常显著的进步。
组件的互补性:
单独使用 LP-Weighting,平均分达到46.8%,相比基线提升了2.5%,证明了动态加权策略本身的有效性。
在LP-Weighting的基础上再加入 PG-Sampling(即完整的LPPO),分数从46.8%进一步提升到48.8%,再次增加了2.0%。这表明两种策略是互补的,而非冗余。PG-Sampling解决了模型从0到1的突破问题,而LP-Weighting则负责在1到N的过程中加速。
超越同类模型:与其他使用RLVR进行微调的当代7B模型(如Eurus-2, Oat-Zero, GPG-7B等)相比,LPPO在平均性能上取得了领先,并且在AIME24, AIME25, Minerva等多个高难度基准上达到了当前最佳(state-of-the-art)水平。
消融研究
为了更深入地理解两个组件各自的作用,研究者们绘制了模型在训练过程中的性能变化曲线。
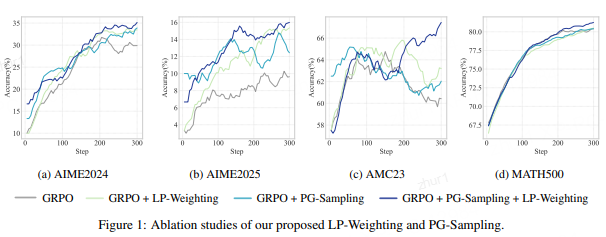
LP-Weighting 和 PG-Sampling 的消融研究
上图清晰地揭示了两个组件在不同训练阶段的独特贡献:
- PG-Sampling:“快速启动” (Fast Start) :在训练的早期阶段(例如前60步),包含PG-Sampling的策略(绿色和紫色曲线)的性能迅速超越了不含PG-Sampling的策略(蓝色和橙色曲线)。这说明,通过为难题提供“提示”,PG-Sampling帮助模型迅速克服了初始的探索障碍,实现了性能的“冷启动”。
- LP-Weighting:“稳定收尾” (Reliable Finish) :在训练的中后期(约60步之后),LP-Weighting的作用开始显现。包含LP-Weighting的策略(橙色和紫色曲线)的学习曲线变得更加陡峭且平滑。这表明,LP-Weighting通过过滤梯度噪声、并聚焦于有进步的样本,使得模型的学习过程更稳定、高效,最终能够达到一个更高的性能上限。
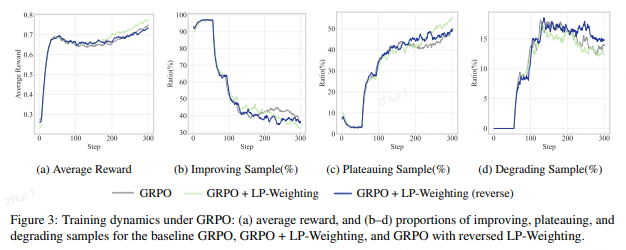
训练动态分析:
GRPO下的训练动态
通过分析训练过程中样本状态的变化,可以发现LP-Weighting显著提升了模型的平均奖励,同时有效减少了“表现退步”(degrading)样本的比例。这表明该策略使模型的学习过程更加稳健,能够更好地保持已学到的知识。
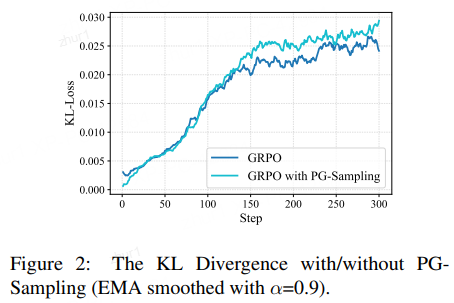
对模型探索行为的影响:
有/无 PG-Sampling 的 KL 散度
KL散度用于衡量当前策略与初始参考策略的差异,可以看作是探索程度的一个指标。实验发现,PG-Sampling会引导策略更快地偏离初始策略。这并不意味着盲目的探索,而是说明通过注入前缀提示,模型被更有效地引导到了一个与初始策略不同、但价值更高(即解题能力更强)的策略空间中。

















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









