




论文链接:https://arxiv.org/abs/2506.21545
代码链接:https://github.com/microsoft/DELT
DELT(Data Efficacy in LM Training)是一种创新的文本数据组织范式。
它集成了数据评分(Data Scoring)、数据选择(Data Selection) 和数据排序(Data Ordering) 三大核心组件。
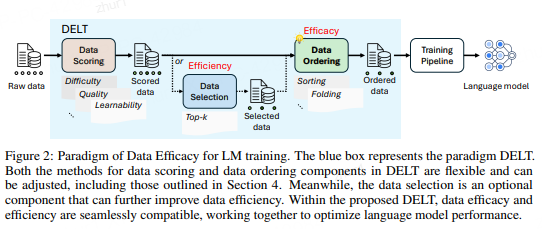
- 数据评分根据特定的属性为每个样本赋予分数,如:难度、质量、多样性等。
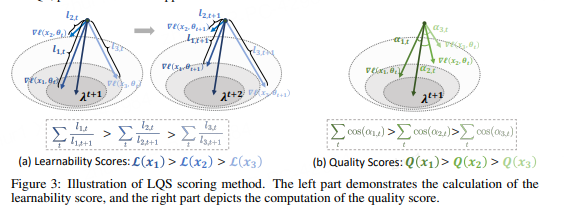
因此,数据评分的规则设置非常重要。于是,研究还提出了Learning-Quality Score(LQS)方法。
该数据评分方式结合了质量和可学习性两个关键指标,不但可以筛选出低质量数据,而且也能捕捉数据在不同阶段的训练价值,进一步提供了可靠的数据排列顺序。
- 数据选择通过评分筛选出最优子集(如:top-k、按阈值筛选等),然后数据排序根据评分重新组织所选择数据的呈现顺序(如:基于课程学习的分数从低到高排列)。 为了兼顾数据处理效率,DELT范式的数据选择和数据排序共用数据评分的结果。
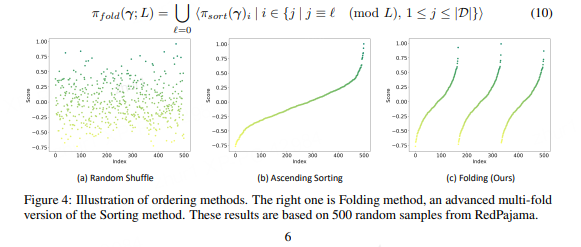
- 为了进一步提升数据效能,团队还提出了一种全新的折叠排序方法Folding Ordering(FO)。
基于课程学习的排序(即,按分数升序排序)可能导致模型遗忘和数据内部分布偏差。
折叠排序策略通过多层“折叠”,将数据按分数分层并多次采样,无重复且均衡分布。
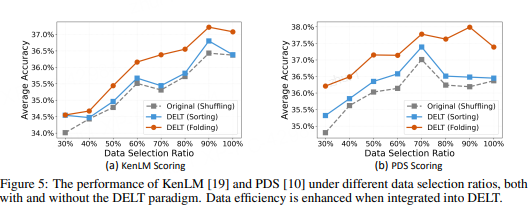
与传统随机排序方法相比,DELT范式不仅通过减小数据规模提升了训练效率;而且在不同模型尺寸和数据规模下,在各种评测集上都显著提升了模型性能。

















 77
77

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









