






 本文分享了Python的OCR识别库Tesserocr的安装和使用经验。安装Tesserocr前需先安装tesseract,直接用pip安装Tesserocr会因缺失组件报错,给出两种解决方法。验证安装时也会遇到问题,如tesseract命令无法识别、初始化API失败等,并提供了相应解决方案。
本文分享了Python的OCR识别库Tesserocr的安装和使用经验。安装Tesserocr前需先安装tesseract,直接用pip安装Tesserocr会因缺失组件报错,给出两种解决方法。验证安装时也会遇到问题,如tesseract命令无法识别、初始化API失败等,并提供了相应解决方案。

Tesserocr是python的一个OCR识别库,但其实是对tesseract做的一层python API封装,所以它的核心是tesseract。因此,在安装tesserocr之前,我们需要先安装tesseract。
这里我主要和大家分享一下自己在安装和使用tesserocr库的过程中遇到的一些坑。
当我们从网上下载安装好tesseract后,接下来,我们安装tesserocr库,当直接使用pip安装时,会出现如下图所示的错误。
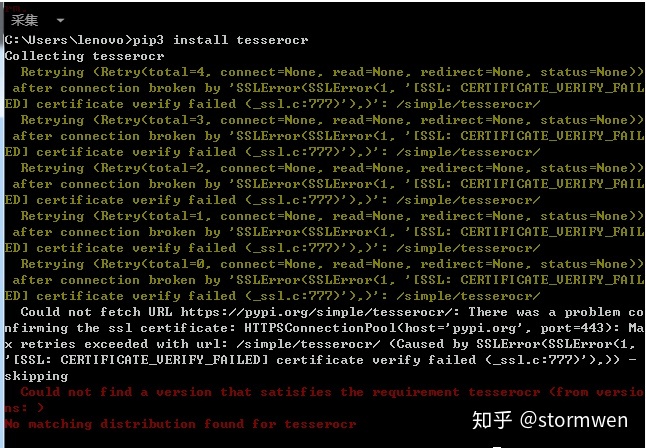
出现上述错误主要是缺失Microsoft Visual C ++ 14.0组件支持。
解决方法如下:
方法一:
最简单的解决办法,是安装运行C ++应用程序所需的Visual C ++组件,下载地址:https://go.microsoft。 ?COM / fwlink / LINKID = 615460。
但是,我更推荐下面这种方法。
方法二:
Step1:下载匹配的whl文件。链接地址:
https://github.com/simonflueckiger/tesserocr-windows_build/releasessimonflueckiger/tesserocr-windows_buildgithub.com

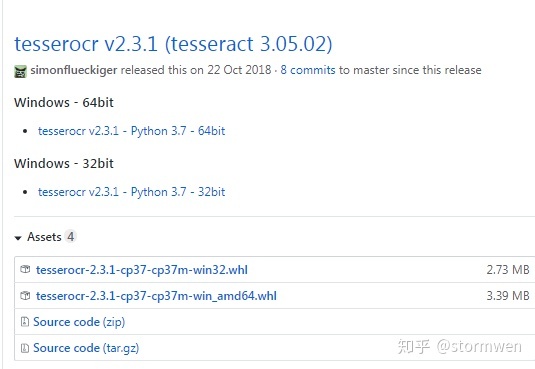
Step2:查看自己的python版本匹配对应文件
以我的为例,Python版本3.7 win64,匹配对应文件:
Step3:下载完成后使用pip安装:
E:Program Files (x86)Python3.7tesserocr-2.3.1-cp37-cp37m-win_amd64.whl验证安装
用到的例子的链接为:https://http://raw.githubusercontent.com/Python3WebSpider/TestTess/master/image.png,可以直接保存下载。

首先用命令行进行测试,将图片下载下来保存为image.png,然后用tesseract命令测试:
tesseract image.png result -l eng && cat result.txt
但是这时会出现tesseract既不是内部命令,也不是外部命令的错误提示,那么如何解决这个问题呢?
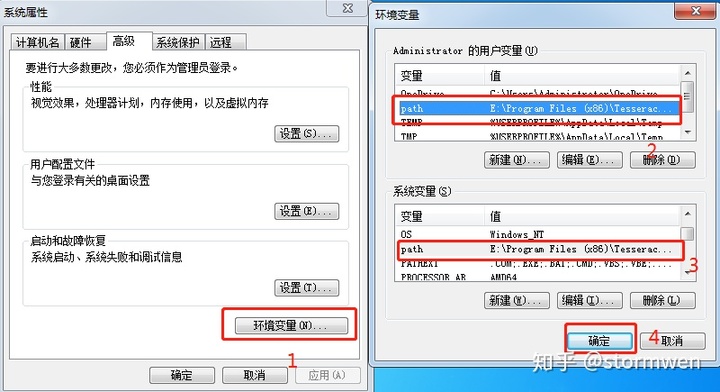
在环境变量的系统变量PATH,把tesseract-OCR的安装路径(如E:Program Files (x86)Tesseractor-OCR;)添加进去。
点击计算机—属性——高级设置——环境变量,点击环境变量,进入配置以下界面。
把刚才的安装路径“E: Program Files(x86) Tesseract-OCR”添加到用户变量Path和环境变量Path中去。下面是我的配置信息样本:
然后在运行上述的验证安装的命令,仍然出现无法识别tesseract的错误提示,那么又怎么解决这个问题呢?
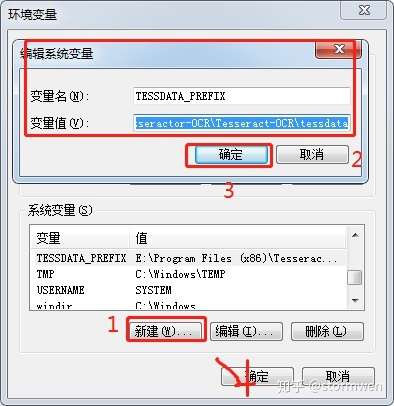
Step1:新建TESSDATA_PREFIX变量,值为tessdata的路径,我的是“E: Program Files(x86) Tesseract-OCR tessdata”;
Step2:在命令行输入tesseract image.png result -l eng && cat result.txt,运行结果如下:
Tesseract open source OCR Engine v3.05.01 with Leptonica
此外,我们还可以利用python代码来测试,这里就需要借助于tesserocr库了,测试代码如下:
import tesserocr
from PIL import Image
image = Image.open(r'E:Program Files (x86)Python3.7image.png')
print(tesserocr.image_to_text(image))使用tesserocr.image_to_text(“path”)报错:运行错误:初始化API失败,可能是无效的tessdata路径。
初始化API失败,可能是在路径E:下存在无效的tessdata,意思是在E盘中找不到tessdata。
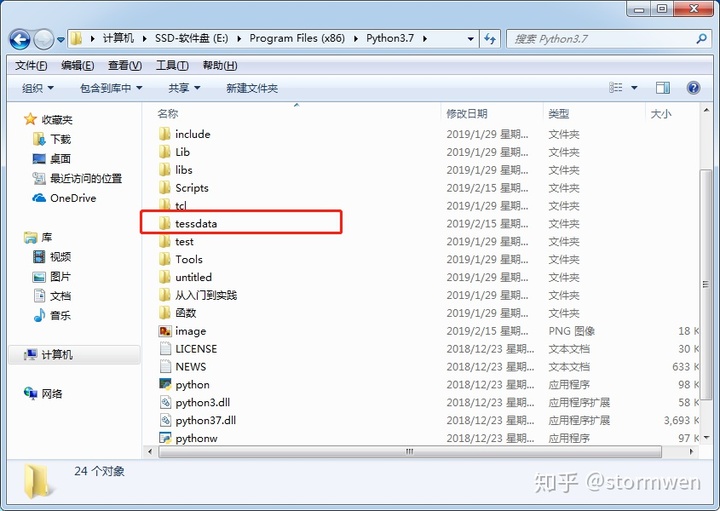
解决方案:将Tesseract-OCR 文件中的tessdata文件夹复制到Python的安装目录下
我们首先利用Image读取了图片文件,然后调用了tesserocr的imag_to_text()方法。再将其识别结果输出。
运行结果如下:
Python3WebSpider
另外,我们还可以直接调用file_to_text()方法,这可以达到同样的效果:
import tesserocr
print(tesserocr.file_to_text(r'E:Program Files (x86)Python3.7image.png'))通过这个简单的文字识别例子,证明了tesserocr和tesseract都已经安装成功。
今天主要分享的是关于tesserocr库安装和使用的知识,对小白来说,可以少走很多弯路,希望大家一起学习,一起进步。


















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









