







 本文是针对小白的一篇详细教程,介绍了如何在PyCharm中安装和使用pytesseract及tesserocr库,特别是Tesseract-OCR的安装、环境变量设置和语言包的添加。建议使用pytesseract,因为tesserocr的安装可能遇到更多问题。文章提供了安装步骤、配置pycharm路径的方法以及简单的测试代码。
本文是针对小白的一篇详细教程,介绍了如何在PyCharm中安装和使用pytesseract及tesserocr库,特别是Tesseract-OCR的安装、环境变量设置和语言包的添加。建议使用pytesseract,因为tesserocr的安装可能遇到更多问题。文章提供了安装步骤、配置pycharm路径的方法以及简单的测试代码。
前言
这两个库的安装与使用折磨了小白博主几个小时,也是综合了各方资料肝出了这篇较为详细的几乎零基础的tesserocr和pytesseract库的安装与使用教程(主要介绍安装部分),可以帮大家少走一些弯路,利用tesserocr或者pytesseract库,前提是已经安装好Tesseract-OCR软件(文后有安装链接),tesserocr库的安装,问题不大,但要配合tesseract-OCR使用,麻烦死了,反正我搞了好久,还是有一些莫名的错误,听我一句劝就用pytesseract吧!
Tesseract-OCR安装
安装过程如下:
1.下载安装包(直接点开文末链接,下载最新版本就行了)
我安装的是这个:
带dev的为开发版本,不带dev的为稳定版本
2.打开下载的.exe文件,进行安装,建议按默认选项一路同意下去,然后就安装成功,
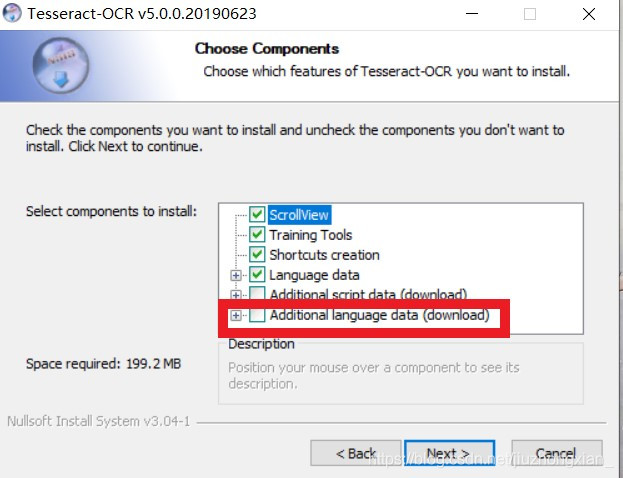
安装过程中,红色框框部分,可以设置下载各个语言的语言包,也可以点‘+’进行选择性下载,默认语言包为英语的语言包,个人感觉这样下载过慢,可以之后进入官网直接下载对应语言包,下载完成后放到Tesseract-OCR\tessdata\目录下
注:chi_sim.traineddata为简体中文语言包,可在cmd中运行tesseract --list-langs命令,查看已安装的语言包
3、设置环境变量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









