






 本文详细解析了ArrayList、LinkedList和Vector在Java中的实现方式和特性。ArrayList基于数组实现,查询快,增删慢,非线程安全;LinkedList采用链表结构,查询慢,增删快,同样非线程安全;而Vector与ArrayList类似,但其操作是线程安全的。在添加元素时,ArrayList会进行自动扩容,LinkedList则是通过节点链接实现添加。
本文详细解析了ArrayList、LinkedList和Vector在Java中的实现方式和特性。ArrayList基于数组实现,查询快,增删慢,非线程安全;LinkedList采用链表结构,查询慢,增删快,同样非线程安全;而Vector与ArrayList类似,但其操作是线程安全的。在添加元素时,ArrayList会进行自动扩容,LinkedList则是通过节点链接实现添加。
一般在面试中可能会被问到arraylist、linkedlist、vector三者相关的区别!
一般来说我想大概都会回答如下的这些:
arraylist底层是数组结构,查询快,增删慢,线程不安全,效率高。
linkedlist底层是链表数据结构,查询慢,增删快,线程不安全,效率高。
vector底层是数组结构,查询快,增删慢,线程安全,效率低。
以上就是最基本的一个优缺点,但是他们的内部结构,具体怎么实现添加查询这一块的,我想应该有一部分人还是不太清楚。
下面我将带领一起去集合的内部看一看具体的代码实现。
arraylist:
首先是arraylist的一个实例化,java提供了一个有参构造和无参构造。下面一起查看代码:
/**
* constructs an empty list with the specified initial capacity.
构造具有指定初始容量的空列表。
*
* @param initialcapacity the initial capacity of the list 初始容量列表的初始容量
* @throws illegalargumentexception if the specified initial capacity 如果指定的初始容量为负,则抛出illegalargumentexception
* is negative
*/
public arraylist(int initialcapacity) {
if (initialcapacity > 0) {
this.elementdata = new object[initialcapacity];
} else if (initialcapacity == 0) {
this.elementdata = empty_elementdata;
} else {
throw new illegalargumentexception("illegal capacity: "+
initialcapacity);
}
}
通过上述我们可以看到,这是arraylist的有参构造,可以自定义集合的初始化长度,否则如果输入的是0那么就使用arraylist自带的默认的数组缓存区。
/**
* constructs an empty list with an initial capacity of ten. 构造初始容量为10的空列表。
*/
public arraylist() {
this.elementdata = defaultcapacity_empty_elementdata;
}
使用无参构造,将会创建一个默认长度的数组。初始长度为10。
/**
* default initial capacity. 默认初始容量
*/
private static final int default_capacity = 10;
/**
* shared empty array instance used for empty instances. 用于空实例的共享空数组实例
*/
private static final object[] empty_elementdata = {};
* 解析add添加方法的全过程,下面的add方法相关的所有源代码,
/**
* appends the specified element to the end of this list. 将指定的元素追加到列表的末尾
*
* @param e element to be appended to this list 将追加到此列表中的e元素
* @return true (as specified by {@link collection#add})
*/
public boolean add(e e) {
// 调用自动扩容存储机制,确保自动数组有存储新元素的能力。
ensurecapacityinternal(size + 1); // increments modcount!!
// 自动扩容存储机制处理后,将元素添加到集合的末尾
elementdata[size++] = e;
return true;
}
private void ensurecapacityinternal(int mincapacity) {
// 判断该数组是否是一个新创建的实例对象
if (elementdata == defaultcapacity_empty_elementdata) {
// 如果是,就设置数组的长度为默认长度 10
mincapacity = math.max(default_capacity, mincapacity);
}
// 确保能够有储存能力
ensureexplicitcapacity(mincapacity);
}
private void ensureexplicitcapacity(int mincapacity) {
// 保存这个列表在结构上被修改的次数。
modcount++;
// overflow-conscious code
// 如果默认的长度减去实际数组的长度大于0,那么就调用grow()方法
if (mincapacity - elementdata.length > 0)
grow(mincapacity);
}
private void grow(int mincapacity) {
// overflow-conscious code
int oldcapacity = elementdata.length; // 获取数组原始的长度
int newcapacity = oldcapacity + (oldcapacity >> 1); // 获取新的数组的长度 (0 + 0/2)
if (newcapacity - mincapacity < 0) // 如果新的值 - 最小值小于0 (0-10)
newcapacity = mincapacity; // 将默认值 10 赋值给 新的值
if (newcapacity - max_array_size > 0) // 如果新的值 - 最大长度 大于 0 (0 - 2147483639) > 0
newcapacity = hugecapacity(mincapacity); // 调用方法
// mincapacity is usually close to size, so this is a win:
elementdata = arrays.copyof(elementdata, newcapacity); // 复制原本的数组,定义长度,赋值给自己,来达到自动扩容
}
* 总结以上,在arraylist被无参实例化的时候就会被创建一个空的数组,在添加第一个值时,arraylist底层的自动扩容机制将会被执行,也就是private void grow(int mincapacity)这个方法会被调用,给内部的elementdata数组定义初始长度为10,然后再将值添加到数组的末尾。这里面主要就是牵涉到一个自动扩容机制,在每一次添加之前,都会去判断,当前数组长度是否有实际的存储能力,如果没有那么自动扩容机制就会根据当前数组长度+当前长度/2来计算的方式,对当前数组进行扩容。
linkedlist:
* 链接内部结构图
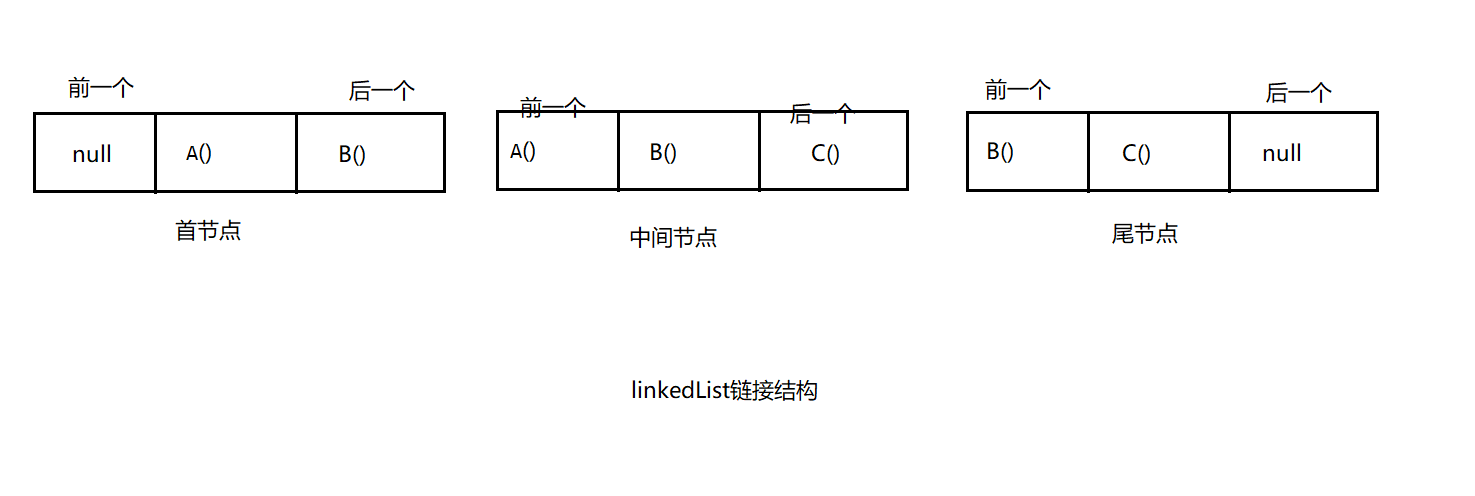
* 查看linkedlist的无参构造和有参构造
* 无参构造
/**
* constructs an empty list. // 构造一个空列表
*/
public linkedlist() {
}
* 有参构造
/**
* constructs a list containing the elements of the specified 构造包含指定元素的列表
* collection, in the order they are returned by the collection's 集合,按照集合返回的顺序
* iterator. 迭代器
*
* @param c the collection whose elements are to be placed into this list
* @throws nullpointerexception if the specified collection is null
*/
public linkedlist(collection extends e> c) {
this();
addall(c);
}
* 解析add添加方法:
/**
* appends the specified element to the end of this list. 将指定的元素追加到列表的末尾
*
*
this method is equivalent to {@link #addlast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link collection#add})
*/
public boolean add(e e) {
linklast(e);
return true;
}
/**
* links e as last element. 链接做为最后一个元素
*/
void linklast(e e) {
// 将最后一个节点临时存储起来
final node l = last;
// 创建一个新的节点,设置新的节点的上一个节点和当前节点的值
final node newnode = new node<>(l, e, null);
// 将新创建的节点重新存储到专门用于保存最后一个节点的值的对象
last = newnode;
// 判断是否是第一次添加,如果是第一次添加值,那么上一个值一定是null,否则就会一个值
if (l == null)
// 如果是第一次添加,那么我们就要将新创建的节点保存到链表的头first
first = newnode;
else
// 否则就设置l的下一个节点为新的节点
l.next = newnode;
// 长度增加
size++;
// 修改次数
modcount++;
}
* 总结以上:从源代码上我们可以看到,linkedlist内部采用的实际上是通过多个节点来保存值,每个节点对象中对它的上一个节点和下一个节点继续记录,以此将所有的节点串联起来,就形成了链表。
vector:
vector其实本质上和arraylist是一样的,底层都是使用了数组来完成,只是vector是从jdk1.0版本开始,arraylist是1.2版本开始,可以理解的是arraylist其实就是用来代替vector的。vector和arraylist最大的区别就是一个是线程安全,一个是线程不安全的。这个我们可以通过查看底层代码来得知。
* 解析add代码
/**
* appends the specified element to the end of this vector. 将指定的元素附加到这个向量的末尾
*
* @param e element to be appended to this vector
* @return {@code true} (as specified by {@link collection#add})
* @since 1.2
*/
public synchronized boolean add(e e) {
modcount++;
ensurecapacityhelper(elementcount + 1);
elementdata[elementcount++] = e;
return true;
}
* 总结上述可得知:相比较arraylist的add方法,我们可以看出,vector的add方法添加的同步锁。
------------------------------------------------------ 分割 -------------------------------------------------------------------
学无止境,永远不要轻言放弃。
希望与广大网友互动??
点此进行留言吧!

















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









