







简介:智能指针是C++中用于自动内存管理的工具,可防止对象未正确释放导致内存泄漏。'ptr.h'是一个开源项目,开发了一种使用信号量实现非阻塞线程安全引用计数的智能指针模板。这个库支持多线程环境下的动态对象管理,具备高效性和灵活性。它采用了信号量技术进行引用计数,实现线程安全的资源访问和自动释放。'ptr.h'智能指针模板支持通用删除机制,适用于管理对象数组及其他资源。开发者还可以通过定制删除器来满足特定内存清理需求。'ptr.h'为C++程序员提供了强大的内存管理工具,促进了源码学习与项目贡献的开源精神。 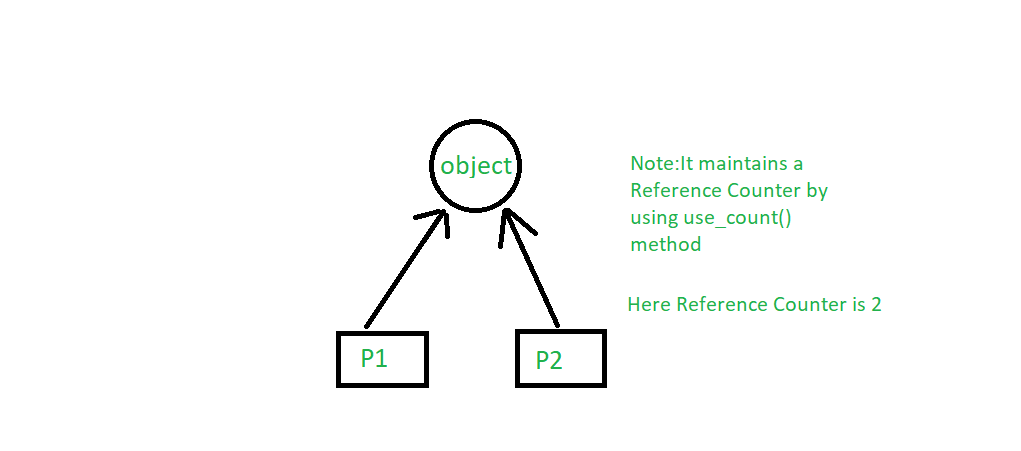
1. C++智能指针概念
1.1 智能指针的诞生背景
在C++中,程序员经常需要手动管理内存,这既耗时又容易出错。为了减少内存泄漏、空悬指针等问题,C++11标准引入了智能指针的概念。智能指针通过引用计数来自动管理内存的分配和释放,从而简化了内存管理的复杂性。
1.2 智能指针的类型与选择
C++标准库提供了多种智能指针,如 std::unique_ptr 、 std::shared_ptr 和 std::weak_ptr 。每种智能指针都有其独特的用途,比如 std::unique_ptr 保证了资源的独占所有权,而 std::shared_ptr 允许多个指针共享所有权。理解这些智能指针的特性对于有效管理资源至关重要。
1.3 如何使用智能指针
智能指针的使用是透明的,即在很多情况下,可以像使用普通指针一样使用智能指针。但是,使用智能指针时应避免循环引用,因为这可能会导致内存泄漏。正确的做法是使用 std::weak_ptr 来打破循环依赖。下面是一个使用 std::shared_ptr 的简单示例:
#include <memory>
#include <iostream>
int main() {
std::shared_ptr<int> ptr = std::make_shared<int>(10);
std::cout << "当前引用计数: " << ptr.use_count() << std::endl; // 输出: 当前引用计数: 1
return 0;
}
通过这种方式,智能指针能够帮助开发者更安全、高效地管理资源,提高程序的健壮性。
2. 非阻塞线程安全引用计数
在现代的多线程编程中,引用计数技术是管理对象生命周期的常用技术。它允许对象在没有任何引用指向它时自动释放,从而避免内存泄漏。然而,传统引用计数方法在多线程环境下面临性能瓶颈,甚至可能导致阻塞。非阻塞线程安全引用计数(Non-blocking Thread-safe Reference Counting)解决了这一问题,通过使用先进的并发控制技术,它能够在不造成线程阻塞的情况下安全地进行引用计数管理。
2.1 引用计数的基本原理
2.1.1 引用计数的定义和作用
引用计数是一种用于跟踪资源如内存占用的技术。每一个资源都有一个关联的计数器,用于记录有多少个引用指向该资源。每当一个对象被创建时,其引用计数初始化为1,之后每当有新的引用指向它时,计数器增加1;相反,当某个引用不再指向该对象时,计数器减少1。当引用计数降至0时,表示没有任何引用指向该对象,此时可以安全地释放该对象占用的资源。
引用计数的引入主要是为了解决对象生命周期管理的问题。它使程序员能够更简单地处理复杂的数据结构和资源管理,尤其是在涉及大量共享对象和内存管理的场景中。
2.1.2 引用计数在智能指针中的应用
智能指针是C++标准库中的一个特性,它能够自动管理对象的生命周期。智能指针的典型实现如 std::shared_ptr ,使用引用计数来追踪有多少个智能指针实例指向同一个对象。当智能指针的拷贝或赋值发生时,引用计数相应增加;当智能指针被销毁或重置时,引用计数减少。只有当引用计数降至0时,对象才会被自动删除。
这种机制显著简化了共享资源管理,并减少了内存泄漏的可能性。然而,在多线程环境中,引用计数的同步访问也带来了性能开销和潜在的线程安全问题。
2.2 非阻塞技术在引用计数中的实现
2.2.1 非阻塞算法的原理
非阻塞算法是一种特别的并发控制技术,它允许在执行过程中遇到的并发冲突以一种非阻塞的方式解决,而不是使用锁(locks)等阻塞同步机制。在引用计数场景中,非阻塞算法可以确保即使有多个线程在几乎同时进行引用计数的增加或减少操作,系统也能保证引用计数的正确性和一致性。
非阻塞算法的实现通常依赖于原子操作(atomic operations),例如比较和交换(compare-and-swap, CAS)操作,来实现线程间的同步。这些操作对于软件开发者是原子性的,意味着当一个线程对某个值执行原子操作时,其他线程要么看到操作前的原始值,要么看到操作后的更新值,而不会看到中间状态。
2.2.2 非阻塞引用计数的优势与挑战
非阻塞引用计数的优势主要在于它能够提供更高效的并发控制和更好的性能。由于避免了锁的使用,减少了线程阻塞和唤醒的开销,同时在多核处理器上提供了更好的并行性和扩展性。
然而,非阻塞引用计数也面临着一些挑战。实现非阻塞引用计数的算法通常比传统引用计数算法更为复杂,因此在调试和维护上可能需要更多的努力。此外,非阻塞算法需要特别注意ABA问题,即在检查和更新操作之间,值被改变后又恢复到原值,可能导致错误的操作。尽管如此,随着技术的发展和对非阻塞算法理解的加深,这些挑战正逐渐被克服。
2.2.3 实现非阻塞引用计数的代码示例
在本小节中,我们用C++实现一个简单的非阻塞引用计数器,它通过CAS操作来安全地增加或减少引用计数。代码如下:
#include <atomic>
class NonBlockingCounter {
public:
NonBlockingCounter() : count_(0) {}
void AddReference() {
while (true) {
std::size_t current_count = count_.load(std::memory_order_acquire);
if (current_count == std::numeric_limits<std::size_t>::max()) {
throw std::overflow_error("Reference count overflow");
}
if (count_.compare_exchange_weak(current_count, current_count + 1, std::memory_order_release)) {
break;
}
}
}
void ReleaseReference() {
while (true) {
std::size_t current_count = count_.load(std::memory_order_acquire);
if (current_count == 0) {
throw std::runtime_error("Reference count underflow");
}
if (count_.compare_exchange_weak(current_count, current_count - 1, std::memory_order_release)) {
if (current_count == 1) {
delete this; // Deallocate memory when reference count reaches 0
}
break;
}
}
}
private:
std::atomic<std::size_t> count_;
};
逻辑分析与参数说明
-
AddReference和ReleaseReference函数利用std::atomic的load和compare_exchange_weak方法来执行非阻塞的引用计数操作。 -
std::memory_order_acquire和std::memory_order_release指定了操作的内存顺序。std::atomic类型的操作保证了在多线程中对count_的访问是原子的。 - CAS操作是核心,它尝试以原子方式更新变量值。如果当前值符合预期值(即
current_count),则进行更新(计数加一或减一),否则循环重试。 - 使用
std::numeric_limits<std::size_t>::max()和std::runtime_error处理潜在的上溢和下溢错误,确保程序的健壮性。
可视化示例
使用流程图来描述非阻塞引用计数的过程:
graph TD
A[开始] --> B{是否获取锁};
B -- 是 --> C[执行引用计数操作];
C --> D[释放锁];
D --> E[结束];
B -- 否 --> F[等待其他线程完成引用计数操作];
F --> B;
总结
非阻塞引用计数技术在C++多线程编程中提供了高效且安全的资源管理机制。通过原子操作和无锁设计,它可以有效提高并发程序的性能和可伸缩性,但同时也带来了实现上的复杂性和挑战。随着对并发控制理论的深入研究,我们可以预见非阻塞技术将在多线程编程领域发挥更大的作用。
在下一小节中,我们将探讨在实际应用中,如何使用信号量来避免内存泄漏,并实现线程安全的引用计数管理。
3. 信号量在引用计数中的应用
在处理共享资源时,保证并发访问的线程安全是一项关键任务。引用计数是一种常见的技术,用于追踪对象的引用数,以确定何时可以安全地删除对象。然而,在多线程环境中,对引用计数的操作必须是线程安全的。信号量作为一种同步机制,在实现线程安全的引用计数管理方面起着至关重要的作用。
3.1 信号量的基本概念
3.1.1 信号量的定义和类型
信号量是一个用于控制对共享资源访问的同步原语,它由荷兰计算机科学家艾兹赫尔·戴克斯特拉(Edsger Dijkstra)提出。在操作系统和并发编程中,信号量通常用于实现互斥锁和条件变量。
信号量分为以下两种主要类型:
-
二进制信号量(也称为互斥锁) :其值只能是0或1,表示资源的锁定状态。当信号量的值为0时,表示资源不可用;当值为1时,资源可用。这种信号量保证了同一时间只有一个线程可以访问资源。
-
计数信号量 :其值可以是任意非负整数,表示资源的可用数量。线程可以通过信号量来申请或释放资源,并相应地增加或减少信号量的值。
3.1.2 信号量在同步中的作用
信号量的主要作用是提供一种机制来控制对共享资源的访问,确保在任一时刻只有一个线程可以访问这些资源。这对于防止竞态条件(race conditions)至关重要,竞态条件通常发生在多个线程同时访问同一数据或资源时,导致数据不一致或其他不可预测的结果。
信号量通常与两个操作相关联:
-
等待(wait)操作 :也称为P操作或down操作,用于请求资源。如果信号量的值大于0,则减少其值(表示资源已被占用);如果信号量的值为0,则线程被阻塞,直到资源可用。
-
信号(signal)操作 :也称为V操作或up操作,用于释放资源。它增加信号量的值(表示资源已释放),如果有线程因等待该资源而被阻塞,那么它将被唤醒。
3.2 信号量在智能指针中的实际运用
3.2.1 避免内存泄漏
在C++中,智能指针如 std::shared_ptr 利用引用计数来管理资源的生命周期。但是,如果多个线程同时修改引用计数,而没有适当的同步机制,就可能引起引用计数的更新冲突,从而导致资源泄漏或提前释放资源。
使用信号量可以确保对引用计数的访问是原子性的。当一个线程想要增加引用计数时,它必须先获取信号量,然后再进行修改。这样可以确保在修改引用计数的过程中,其他线程无法同时对引用计数进行操作。释放资源时,同样的机制确保了引用计数的减少是安全的。
3.2.2 实现线程安全的引用计数管理
为了实现线程安全的引用计数管理,可以通过封装信号量到智能指针中来保护引用计数的原子性。以下是一个简化的示例,说明如何使用信号量来保护引用计数的增加和减少操作:
#include <semaphore.h>
#include <memory>
class SemaphoreProtectedCounter {
private:
int count;
sem_t sem;
public:
SemaphoreProtectedCounter() : count(0) {
sem_init(&sem, 0, 1);
}
~SemaphoreProtectedCounter() {
sem_destroy(&sem);
}
void increment() {
sem_wait(&sem); // 请求信号量
count++;
sem_post(&sem); // 释放信号量
}
void decrement() {
sem_wait(&sem); // 请求信号量
if (count > 0) {
count--;
}
sem_post(&sem); // 释放信号量
}
int getCount() {
return count;
}
};
// 使用示例
int main() {
SemaphoreProtectedCounter counter;
counter.increment();
// ... 其他线程操作
counter.decrement();
return 0;
}
在上述代码中, sem_wait 函数在进行计数操作前请求信号量,而 sem_post 函数在操作完成后释放信号量。这确保了对 count 变量的访问是线程安全的。尽管这种方法可以防止竞态条件,但频繁的上下文切换可能导致性能下降。
表格:信号量与智能指针同步操作性能比较
| 同步机制 | 性能开销 | 线程安全 | 实现复杂度 | | -------- | -------- | -------- | ---------- | | 互斥锁 | 高 | 高 | 低 | | 信号量 | 中 | 高 | 中 | | 无锁编程 | 低 | 依赖于算法设计 | 高 |
在实际应用中,选择哪种同步机制取决于具体的需求和应用场景。互斥锁提供了最简单的线程安全保证,但可能因为频繁的锁定和解锁带来较大的性能开销。信号量提供了更灵活的控制,但同样需要额外的性能开销。无锁编程提供了极高的性能,但设计和实现起来较为复杂。
代码块注释和逻辑分析
在上述代码示例中,我们使用了 sem_wait 和 sem_post 来实现对 count 变量的线程安全操作。这两个函数分别对应于等待操作和信号操作。 sem_wait 会减少信号量的计数值,如果计数在调用前已经为0,则调用线程将被阻塞,直到计数值大于0。 sem_post 会增加信号量的计数值,并可能唤醒等待该信号量的某个线程。这两个操作确保了对 count 变量的访问不会发生冲突。
这种使用信号量保护共享数据的做法,在处理引用计数时非常有效。但它也引入了额外的性能开销,因为每次对引用计数的操作都需要进行上下文切换来等待和释放信号量。因此,在性能敏感的应用中,开发者需要权衡线程安全与性能之间的关系,并选择合适的同步机制。
mermaid流程图:智能指针引用计数线程安全操作
graph TD;
A[开始] --> B{引用计数增加};
B --> C[请求信号量];
C --> D{是否有线程等待?};
D -- 是 --> E[阻塞当前线程];
D -- 否 --> F[减少引用计数];
E --> G[唤醒等待线程];
F --> H[释放信号量];
H --> I[结束];
B -- 引用计数减少 --> J[请求信号量];
J --> K{是否有线程等待?};
K -- 是 --> L[阻塞当前线程];
K -- 否 --> M[增加引用计数];
L --> N[唤醒等待线程];
M --> O[释放信号量];
O --> I;
上述流程图展示了引用计数增加和减少的线程安全操作流程。无论是增加还是减少引用计数,都需要先请求信号量,然后执行相应的操作,最后释放信号量。如果在请求信号量时有其他线程正在等待,当前线程将被阻塞,直到信号量被释放并唤醒等待线程。这样可以确保对共享资源的安全访问。
通过结合信号量和智能指针,开发者可以构建出既能保证内存安全又能适应并发环境的健壮应用程序。在后续章节中,我们将进一步探讨动态内存管理,这是C++编程中的另一个重要方面,并介绍智能指针在其中扮演的角色。
4. 动态内存管理
4.1 动态内存管理的重要性
4.1.1 动态内存与静态内存的区别
在C++中,内存管理是程序员必须深入理解和掌握的一个重要概念。静态内存分配是指对象在编译时就已经确定其大小和生命周期,通常用于全局变量、静态变量和局部变量等。这些变量的内存分配是在程序的编译和链接阶段就已完成,其生命周期与程序的执行周期一致。相对地,动态内存分配则是指在程序运行时,根据程序的需要,通过特定的内存分配函数(如 new 和 delete )进行的内存分配和释放。
动态内存分配和静态内存分配的主要区别在于,动态内存分配提供了更大的灵活性,允许程序在运行时确定内存的使用,可以根据实际需要申请和释放内存。这一特性使得动态内存管理非常适合于需要处理不确定大小数据结构的场景,如链表、树、图等数据结构的实现。
4.1.2 C++内存管理机制
C++提供了较为复杂的内存管理机制,包括 new 、 delete 操作符和智能指针等。 new 操作符用于在堆上分配内存,而 delete 操作符用于释放 new 操作符分配的内存。尽管 new 和 delete 为动态内存分配和释放提供了便利,但它们仍然需要程序员手动管理内存,容易造成内存泄漏和野指针等问题。
为了减少内存管理的错误和简化内存管理的复杂性,C++11引入了智能指针,如 std::unique_ptr 、 std::shared_ptr 和 std::weak_ptr 等。智能指针通过引用计数机制自动管理对象的生命周期,当引用计数降到零时,智能指针会自动调用 delete 释放内存,极大地提高了内存管理的安全性和便利性。
4.2 智能指针与动态内存管理
4.2.1 自动内存释放机制
智能指针的核心优势在于它提供了一种自动的内存管理机制。智能指针通过引用计数跟踪有多少个指针指向同一对象。当最后一个指向对象的智能指针被销毁或重置时,引用计数降至零,智能指针自动调用对象的析构函数并释放对象所占用的内存。
#include <memory>
#include <iostream>
int main() {
std::shared_ptr<int> sp = std::make_shared<int>(42); // 创建一个shared_ptr指向一个int对象
// 当sp离开作用域时,它会自动释放分配的内存
return 0;
}
在上述代码示例中,当 main() 函数执行结束时, sp 所管理的内存将被自动释放。这避免了忘记手动释放内存所引发的内存泄漏问题。
4.2.2 避免内存泄漏的实践技巧
尽管智能指针极大简化了内存管理,但开发者仍需注意一些实践技巧来避免内存泄漏。例如,在异常处理中,智能指针应被放置在作用域块的末尾,确保即使发生异常,智能指针仍能正确释放资源。
void someFunction() {
std::unique_ptr<ExpensiveObject> up = std::make_unique<ExpensiveObject>(); // 创建一个unique_ptr指向一个对象
if (condition) {
throw std::runtime_error("Some error condition");
}
// 如果没有异常发生,继续执行
}
当 condition 为真时,会抛出异常。即使在异常发生时,由于 up 智能指针位于作用域的末尾,它的析构函数会被调用,因此 ExpensiveObject 对象会被正确释放,防止了内存泄漏。
此外,建议总是使用智能指针来管理动态分配的资源,避免裸指针的使用。使用智能指针不仅可以自动管理资源,还可以减少内存泄漏的风险,并且代码的可读性和可维护性也得到提升。在使用智能指针时,还要注意避免循环引用,因为这会导致引用计数无法归零,从而阻止资源的释放。为了处理循环引用,可以考虑使用 weak_ptr 来打破循环。
5. 通用删除机制
5.1 删除器的设计原理
5.1.1 删除器的概念和作用
在智能指针的生命周期中,资源的释放是一个关键的环节。智能指针的删除器是一个函数或者函数对象,负责在引用计数达到零时执行实际的删除动作。它对于资源的正确释放和异常安全的保证起到了决定性的作用。删除器可以与智能指针配合使用,它能够有效地管理对象的生命周期,确保对象在不再需要时能够被安全地释放。
5.1.2 删除器的实现策略
删除器的实现策略通常涉及以下几个方面:
- 直接调用析构函数 :这是最直接的删除器,它简单地调用指向对象的析构函数。
- 异常安全 :在异常发生时,删除器仍然能够保证资源得到正确的释放。
- 自定义释放机制 :在某些特殊情况下,我们可能需要在对象被销毁前执行额外的操作,比如日志记录、资源清理等。
为了提高代码的灵活性和复用性,我们通常会使用函数对象来实现删除器,这样可以允许我们在删除器中保存状态或执行更复杂的操作。标准库中已经提供了一些常用的删除器,比如 std::default_delete ,也可以根据具体需求自定义删除器。
5.2 常见删除器的实现和应用
5.2.1 标准删除器的使用
标准删除器 std::default_delete 是C++标准库中的一个通用删除器,它通常与 std::unique_ptr 搭配使用。 std::default_delete 的实现非常简单,它在被调用时会直接删除一个对象,如下所示:
template <class T>
struct default_delete {
void operator()(T* ptr) const {
delete ptr;
}
};
在使用时,只需要将 std::unique_ptr 与默认的删除器模板参数一起使用,即可实现默认的删除行为:
std::unique_ptr<int, std::default_delete<int>> ptr(new int(10));
5.2.2 定制删除器的创建与应用
有时候,标准删除器可能无法满足特定的需求。这时,我们可能需要创建一个自定义的删除器。自定义删除器可以是函数,也可以是函数对象,甚至可以是一个lambda表达式。
例如,如果对象的删除不仅仅需要调用 delete 操作符,还需要执行额外的日志记录,我们可以定义如下的删除器:
struct MyDeleter {
void operator()(int* p) const {
std::cout << "Deleting int with value " << *p << std::endl;
delete p;
}
};
对于更复杂的情况,比如资源释放需要释放多个相关联的对象,我们可以使用lambda表达式来创建一个更灵活的删除器:
auto my_deleter = [](int* p) {
delete[] p; // 假设这是一个数组的删除
};
std::unique_ptr<int[]> my_array(new int[10], my_deleter);
在这个例子中,我们创建了一个 unique_ptr 来管理一个动态分配的整型数组,并指定了一个lambda表达式作为删除器,这样就可以确保数组被正确地删除。
为了演示如何将自定义删除器应用到智能指针中,我们可以看一个更具体的例子:
#include <iostream>
#include <memory>
class MyClass {
public:
MyClass() { std::cout << "MyClass created.\n"; }
~MyClass() { std::cout << "MyClass destroyed.\n"; }
};
int main() {
// 使用自定义删除器,打印额外的日志信息
auto custom_deleter = [](MyClass* p) {
std::cout << "Custom deleter is about to delete a MyClass object.\n";
delete p;
};
// 创建一个unique_ptr,并将自定义删除器作为第二个参数
std::unique_ptr<MyClass, decltype(custom_deleter)> my_ptr(new MyClass, custom_deleter);
return 0;
}
执行上述代码,我们可以看到自定义删除器输出的提示信息,说明其在对象生命周期结束时被调用,从而展示了自定义删除器的强大功能和灵活性。
删除器的选择和使用对于智能指针的灵活性和功能性有着深远的影响。通过本章节的内容,您应该能够理解删除器在智能指针中的作用以及如何实现和使用定制的删除器。在不同的应用中,合适的删除器可以帮助开发者管理资源,确保资源的高效利用和安全释放。
6. 源码开源与贡献
在现代软件开发中,开源文化已经成为一种不可忽视的力量。它不仅仅是代码共享,更是知识、经验以及创新的交流平台。开源项目允许全球的开发者共同参与、改进,并从中受益。本章节将探讨开源的现状和意义,并详细介绍如何参与一个具体的开源项目——ptr.h。
6.1 开源的现状和意义
6.1.1 开源社区的介绍
开源社区***组织,它们通过互联网相互协作,共享软件资源。常见的开源社区包括GitHub、GitLab和SourceForge等,其中GitHub是目前最大的开源社区。开源社区中的项目通常是以开源许可证发布的,这些许可证确保任何人都可以使用、修改和分发源代码。
6.1.2 开源文化的重要性
开源文化促进了代码的透明度和协作,从而提升了软件的质量和安全性。它为开发者提供了学习和成长的机会,允许他们通过阅读和理解他人的代码来提高自己的技能。此外,开源项目往往是技术创新的前沿阵地,许多重要的技术革新最初都是在开源项目中出现的。
6.2 参与ptr.h开源项目
ptr.h是一个广泛使用的智能指针库,它提供了类似于C++标准库中的智能指针功能。参与ptr.h开源项目不仅能够提升个人的编程技能,还有机会为C++社区做出贡献。以下是参与ptr.h项目的具体步骤。
6.2.1 源码结构和贡献流程
ptr.h项目通常遵循典型的开源项目结构,包括但不限于以下几个部分:
-
include/:包含头文件。 -
src/:包含源代码文件。 -
tests/:包含单元测试代码。 -
docs/:包含文档说明。
贡献流程通常如下:
- Fork项目 :在GitHub上fork ptr.h项目到自己的账户下。
- 克隆到本地 :使用
git clone将项目克隆到本地开发环境。 - 创建新分支 :基于最新版本创建一个新分支进行开发。
- 进行修改 :在新分支上进行代码修改或添加新功能。
- 编写测试 :为修改或新功能编写单元测试。
- 提交更改 :使用
git commit提交更改,并使用git push推送到自己的GitHub仓库。 - 发起Pull Request :在GitHub上发起Pull Request请求原项目作者合并代码。
6.2.2 如何参与ptr.h项目的贡献与交流
要有效参与ptr.h项目的贡献和交流,首先需要熟悉项目文档和编码标准。参与讨论通常有以下几种方式:
- 参与Issues讨论 :在GitHub项目页面查看现有的Issues,并参与问题的讨论。
- 提出新的Issue :如果发现代码的问题或者有新的功能需求,可以提出新的Issue。
- 邮件列表交流 :许多开源项目有邮件列表,通过邮件列表与其他贡献者和维护者交流。
- 贡献文档 :除了代码,文档也是开源项目的重要组成部分。可以通过改进文档来参与项目贡献。
在进行代码贡献时,确保遵守项目维护者设定的贡献准则,这通常包括代码风格、测试覆盖和代码审查等要求。如果你是第一次贡献代码,可以通过一些小型的改进或修复来开始,比如文档错误或注释的改进。
以下是一个简单的示例,展示如何为ptr.h项目编写一个新的智能指针类:
// 新智能指针类实现示例
class my_unique_ptr {
public:
explicit my_unique_ptr(T* ptr = nullptr) : ptr_(ptr) {}
~my_unique_ptr() { delete ptr_; }
T* release() {
T* temp = ptr_;
ptr_ = nullptr;
return temp;
}
void reset(T* ptr = nullptr) {
T* old_ptr = ptr_;
ptr_ = ptr;
delete old_ptr;
}
T* get() const { return ptr_; }
T& operator*() const { return *ptr_; }
T* operator->() const { return ptr_; }
private:
T* ptr_;
};
// 在ptr.h头文件中添加my_unique_ptr的声明
// 在src/目录下添加对应的实现文件
通过如上方式,你不仅能够提升自己对C++智能指针的理解,还能为开源社区做出自己的贡献。记住,每个伟大的开源项目都由无数的小贡献积累而成。
简介:智能指针是C++中用于自动内存管理的工具,可防止对象未正确释放导致内存泄漏。'ptr.h'是一个开源项目,开发了一种使用信号量实现非阻塞线程安全引用计数的智能指针模板。这个库支持多线程环境下的动态对象管理,具备高效性和灵活性。它采用了信号量技术进行引用计数,实现线程安全的资源访问和自动释放。'ptr.h'智能指针模板支持通用删除机制,适用于管理对象数组及其他资源。开发者还可以通过定制删除器来满足特定内存清理需求。'ptr.h'为C++程序员提供了强大的内存管理工具,促进了源码学习与项目贡献的开源精神。

















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









