







 本文介绍了主题模型的基础认知,包括其概念和优点。重点讲解了三种主题模型算法:潜在语义分析(LSA)、非负矩阵分解(NMF)和隐含狄利克雷分布(LDA)。LSA基于SVD矩阵分解,但效率较低;NMF提高了效率,可解决过拟合;LDA作为推荐模型,基于三层贝叶斯网络,具有统计基础。
本文介绍了主题模型的基础认知,包括其概念和优点。重点讲解了三种主题模型算法:潜在语义分析(LSA)、非负矩阵分解(NMF)和隐含狄利克雷分布(LDA)。LSA基于SVD矩阵分解,但效率较低;NMF提高了效率,可解决过拟合;LDA作为推荐模型,基于三层贝叶斯网络,具有统计基础。
目录
1 潜在语义分析(LSA,是一种基于SVD矩阵分解的主题模型算法)
2 非负矩阵分解(NMF,是一种基于NMF矩阵分解的主题模型算法)
3 隐含狄利克雷分布(LDA,基于三层贝叶斯网络的主题模型算法,推荐使用)
一 主题模型基础认知
1 主题模型的概念
第一点:主题模型是生成式模型
一篇文章的每一个词:文档以一定概率选择某个主题,并从这个主题中以一定概率选择某个词
第二点:主题模型的目的
主题模型可以自动分析每个文档,统计文档内词语,根据统计的信息判断当前文档包含哪些主题以及这些主题所占比例大小
2 主题模型的优点
- 第一点:克服了传统信息检索中文档相似度计算的缺点(如词袋法等忽略语义与语序问题)
- 第二点:从海量的文字中找到文字之间的语义主题(挖掘不同文字内在相同的语义主题)
二 主题模型具体算法
1 潜在语义分析(LSA,是一种基于SVD矩阵分解的主题模型算法)
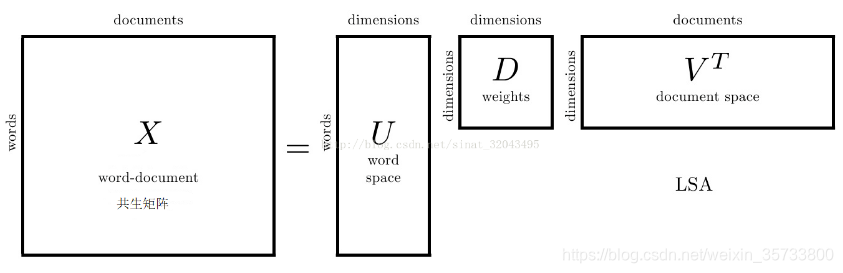
1)算法原理与流程
第一步:SVD分解
注意:
第一点:m表示词数,n表示文档数,k表示主题数
第二点:含义
表示第
个词与第
个文档的相关度(通过IT-IDF计算得到)
表示第
表示第
第
第二步:判断文档相似度
- 方式一:在文档主题矩阵
中使用聚类算法
- 方式二:在文档主题矩阵
2)优缺点
优点
适合小规模数据集且粗粒度找出文档的主题分布
缺点
- SVD矩阵分解效率低
- 很难选择适合的k值
- 不是基于概率的模型,缺乏统计基础,解释性低
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









